Chapter 4 Main Memory¶
主存硬件演化
| 时间 | 技术 | 核心特点 |
|---|---|---|
| 20 世纪 40 年代中期 | Delay Line Memory | J. Presper Eckert 为 EDVAC 发明,典型实现是水银延迟线存储器,容量小、顺序特征强 |
| 1948 | CRT / Williams Tube | 利用 CRT 屏幕表面电荷点阵存位,是早期较接近随机访问的电子存储器 |
| 1970 | DRAM | 用电容存电荷,需要周期刷新,因高密度、低成本成为主流主存 |
| 1990s | SDRAM | 与系统时钟同步,适合流水线与 burst transfer,提升吞吐 |
| 之后 | DDR SDRAM | 在时钟上升沿和下降沿都传输数据,同频率下带宽翻倍 |
主存的发展并不是单纯追求“更快”,而是在容量、成本、可扩展性、带宽和访问方式之间不断折中。现代系统中,主存的核心矛盾逐渐从“能不能存下”转向“如何高效、受保护地管理和访问”。
1 Memory allocation evolution¶
In the Beginning
在 batch system 时代,往往一次只把一个程序装入物理内存,程序运行到结束才换下一个。
若作业大于物理内存,只能采用类似分阶段装入的方法:
- 把程序拆成多个可独立执行的部分
- 每一部分都能放进可用内存
- 当前部分完成后,再显式装入下一部分
这种方式本质上是人工管理装入与覆盖,灵活性很差。
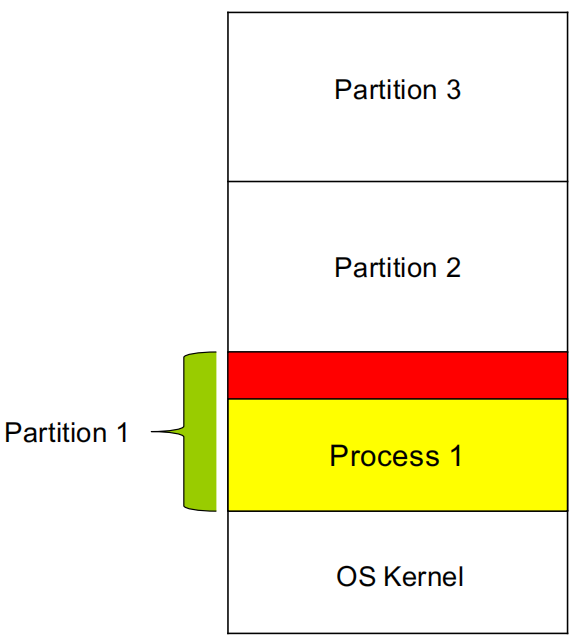
多个进程同时驻留在物理内存中,可以在一个进程等待时快速切换到另一个 ready process,因此需要把物理内存切成多个分区(partition)。分区机制至少要满足三点:
- Protection:防止进程互相覆盖 / 破坏
- Fast execution:保护机制不能把每次内存访问都拖慢太多
- Fast context switch:切换进程时,地址映射设置不能太慢
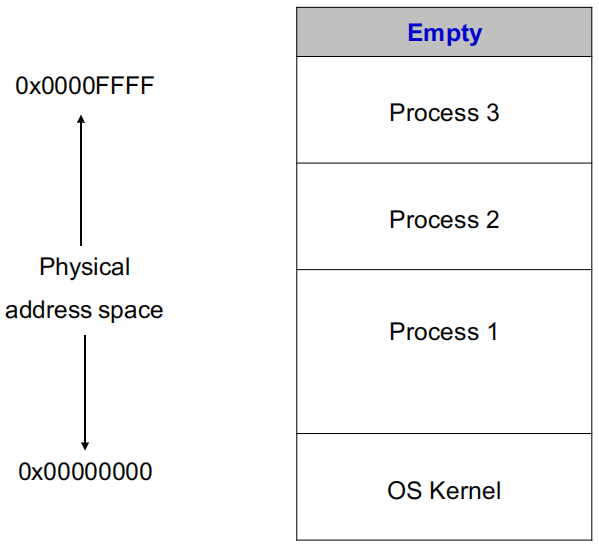
纯物理地址装载的问题
进程装入某个分区后,若程序内部直接使用物理地址,那么:
- 装载时必须把所有地址都重定位到该分区起始位置
- OS 需要负责物理内存上的保护
- 一旦进程开始运行,它就很难再被移动
因为程序中已经记住了自己所在的物理位置。
当某个新进程需要一段大于当前最大空闲分区的连续空间时,即使总空闲空间足够,也可能只能等待,甚至出现 starvation。
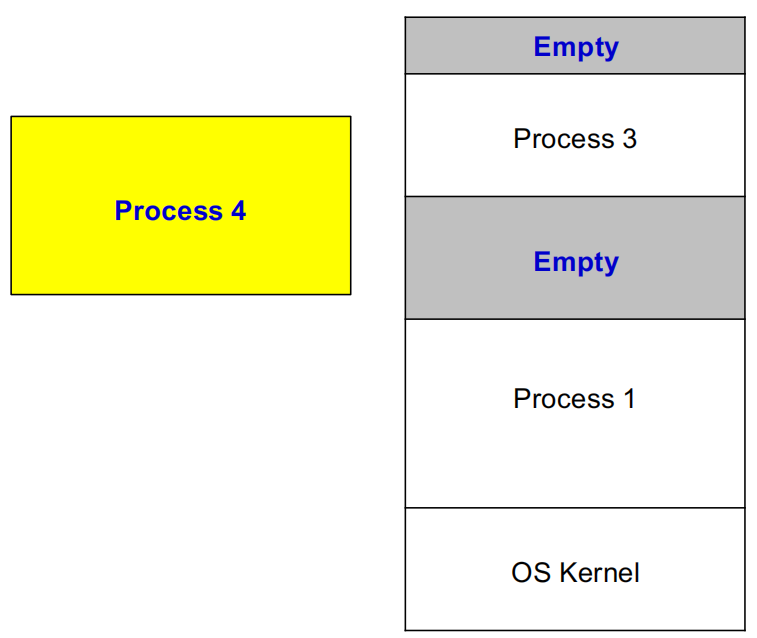
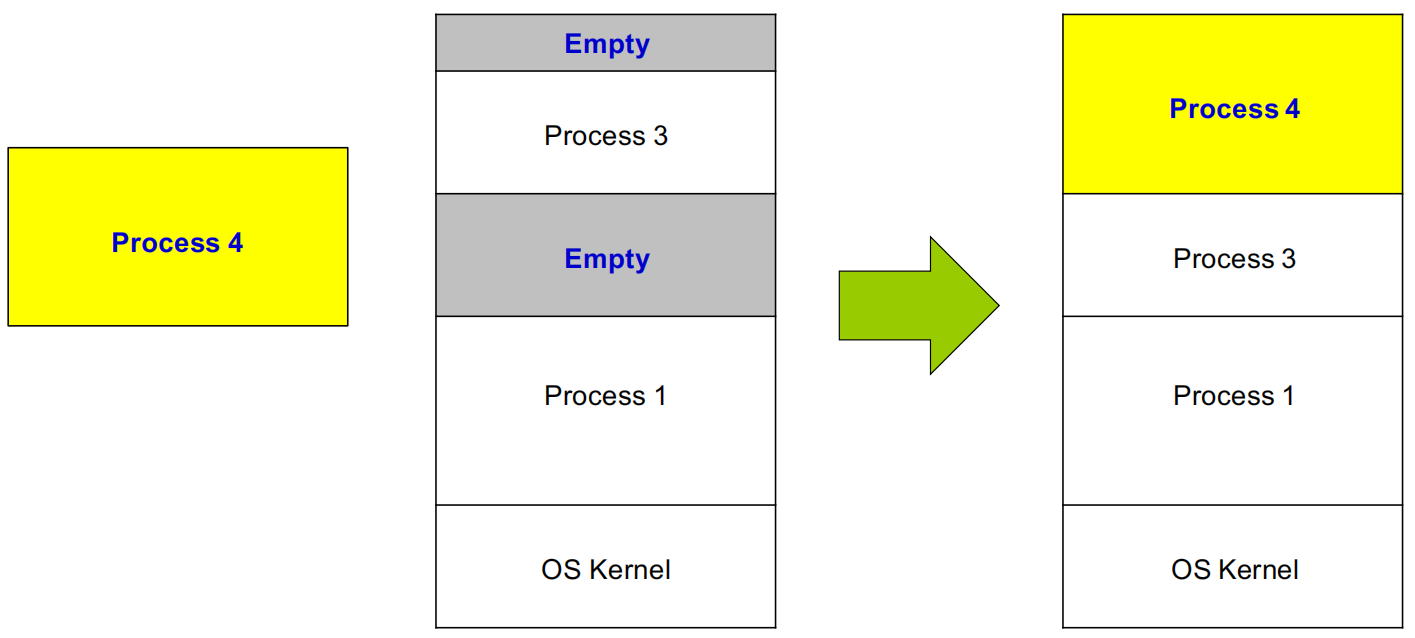
为了能把已有进程移动到别处,就必须让进程看到的地址不再是实际物理地址,而是逻辑地址(logical address)。
Logical Address 的核心思想
- 进程使用相对于自身分区起点的偏移量,运行时再由硬件把逻辑地址翻译成物理地址。
- 程序发出逻辑地址和机器实际访问可能不一样。
- 只要修改映射关系,进程就可以在内存中搬迁,而自己并不知道。
最简单的实现方法是为每个进程维护一对寄存器:
- Base register:该进程当前所在分区的起始物理地址
- Limit register:该进程可访问逻辑地址空间的长度上界
CPU 在 user mode 下生成的每一次内存访问,都必须经过边界检查。
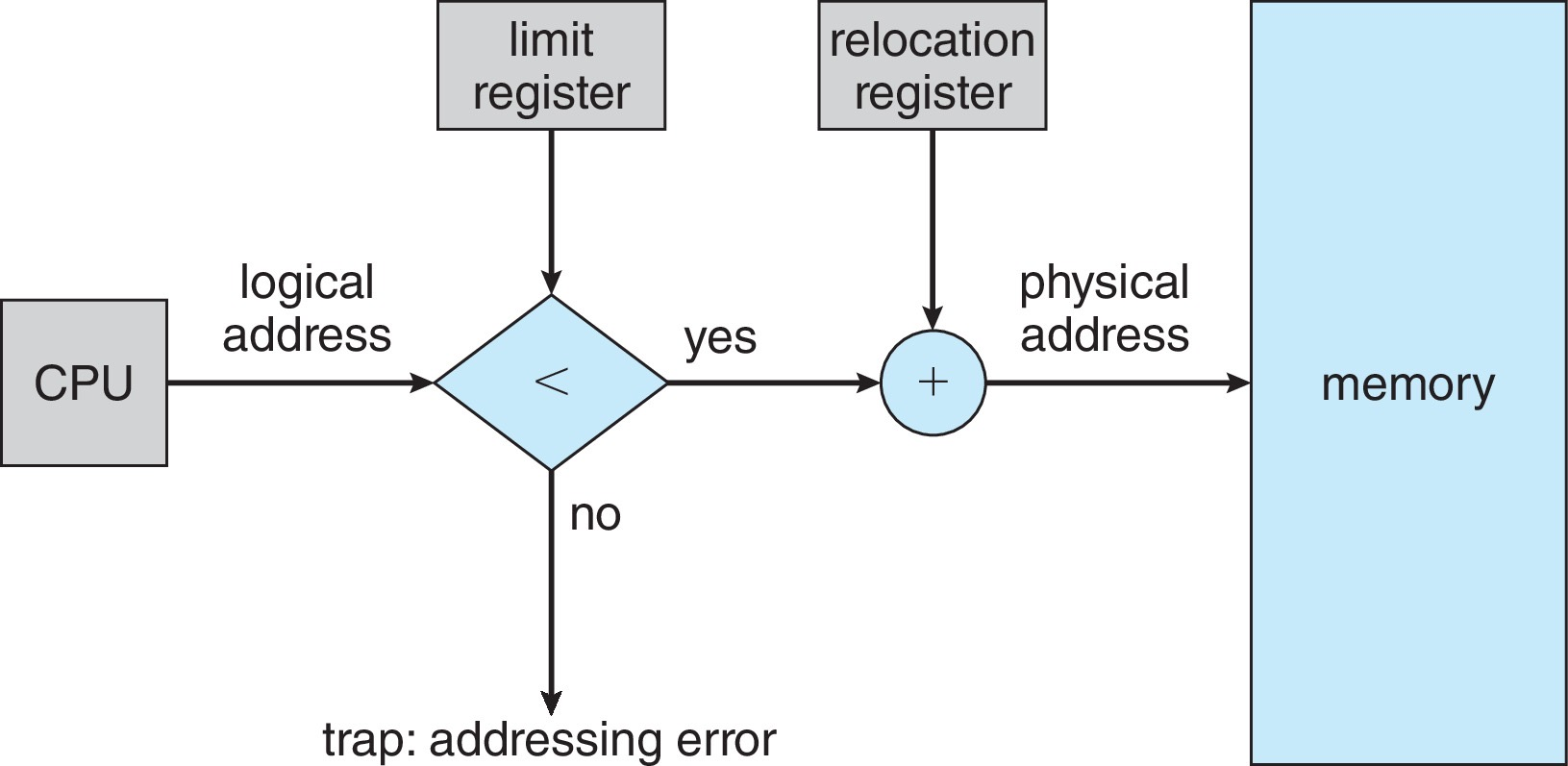
为什么 Base / Limit 在 context switch 时由 OS 重新装载
因为每个进程的地址空间范围不同。切换到新进程时,必须把该进程对应的 base 与 limit 一起切换,CPU 后续产生的所有逻辑地址才会落到正确的物理区域。
为什么装载 Base / Limit 的指令必须是特权指令?
如果用户进程能自己修改 base 或 limit,它就可能越界访问别的进程或内核的内存,整个保护机制会立刻失效,因此这些寄存器只能由 OS 在内核态下更新。
这种方案的优点
- Built-in protection:
limit天然提供边界检查 - Fast execution:加法和比较都能在硬件里高速完成
- Fast context switch:切换时只需更新少量寄存器
- No relocation at load time:程序地址都可以相对
0 - Process can be moved:进程可以被暂停、搬迁,再继续运行而不自知
2 Memory Allocation Strategies¶
2. 1 Fixed Partitions¶
- 内存被划分成固定大小的多个分区(OS 除外)
- Degree of multiprogramming = 分区数
- 实现简单,只要找一个空闲分区就能装入新进程,但所有进程都必须放得进某个分区
内部碎片(Internal Fragmentation)
- 已经分给某个进程的分区内部,还有一部分空间没被使用
- 这部分空间虽然空着,但由于已经属于这个分区,其他进程不能再拿来用
- 典型表现是:分区分配得比请求更大,浪费发生在已分配区域内部
2. 2 Variable Partitions¶
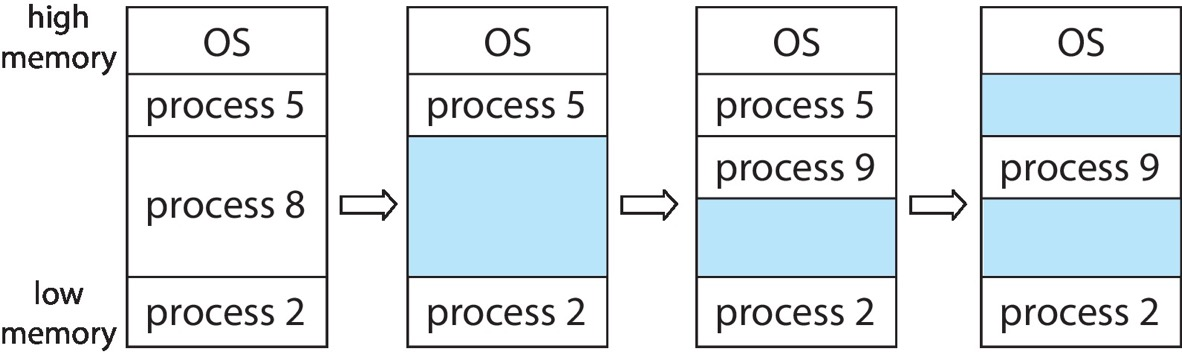
- 按照进程实际需要动态划分分区,空闲区域称为 hole
- 需要额外的数据结构记录哪些分区已经分配以及哪些 hole 仍然可用
基本过程
- 新进程到来时,从足够大的 hole 中分配空间
- 进程结束时释放其分区
- 若相邻区域都空闲,则把它们合并
| 策略 | 做法 | 特点 |
|---|---|---|
| First-fit | 从前往后找,第一个足够大的 hole 就分配 | 搜索通常较快,实践中表现常不错 |
| Best-fit | 找所有足够大的 hole 中最小的那个 | 剩余 hole 最小,但通常要遍历更多项 |
| Worst-fit | 总是从最大的 hole 中分配 | 试图保留更大的剩余空间,但通常效果不如前两者 |
外部碎片(External Fragmentation)
空闲空间散落在多个不连续的小 hole 中,虽然空闲总量可能大于请求大小,但由于不连续,仍然无法满足请求。
Compaction(紧凑 / 压缩)重新搬移内存中的进程,把零散 hole 合并成一个大的连续空闲块,可以缓解该现象。
但 compaction 要求程序必须能在运行时被重定位,会带来明显的性能开销,还要选择合适时机执行。
3 Segmentation¶
Segmentation 把进程地址空间拆成多个逻辑独立的 segment,每个 segment 都可以单独映射到物理内存中的不同位置。
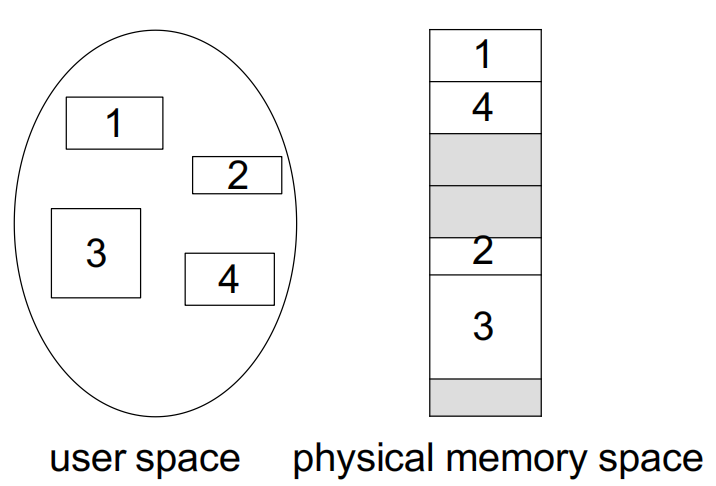
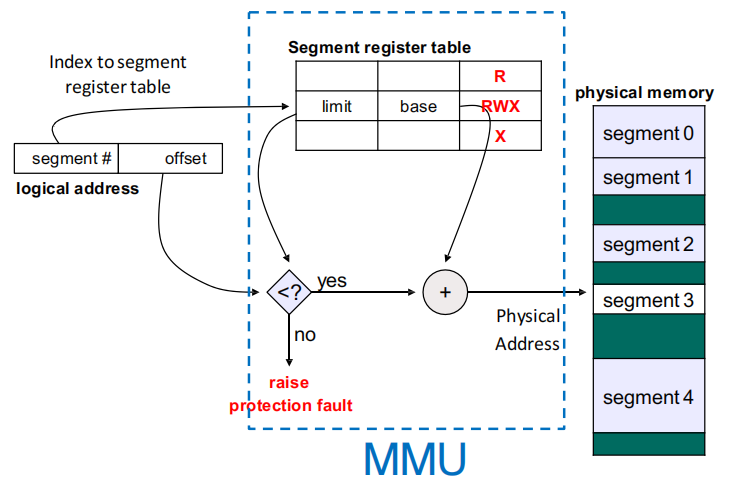
在 segmentation 中,逻辑地址不再只是一个偏移,而是二元组 \(\langle segment\ number,\ offset \rangle\),其中 segment number 说明访问的是哪个段,offset 表示该地址在段内的偏移。
Segment Table 的每个段表项至少包含 Base(该段起始物理地址)和Limit(该段长度),通常还会附带保护位,如 R / W / X、有效位、特权位等。
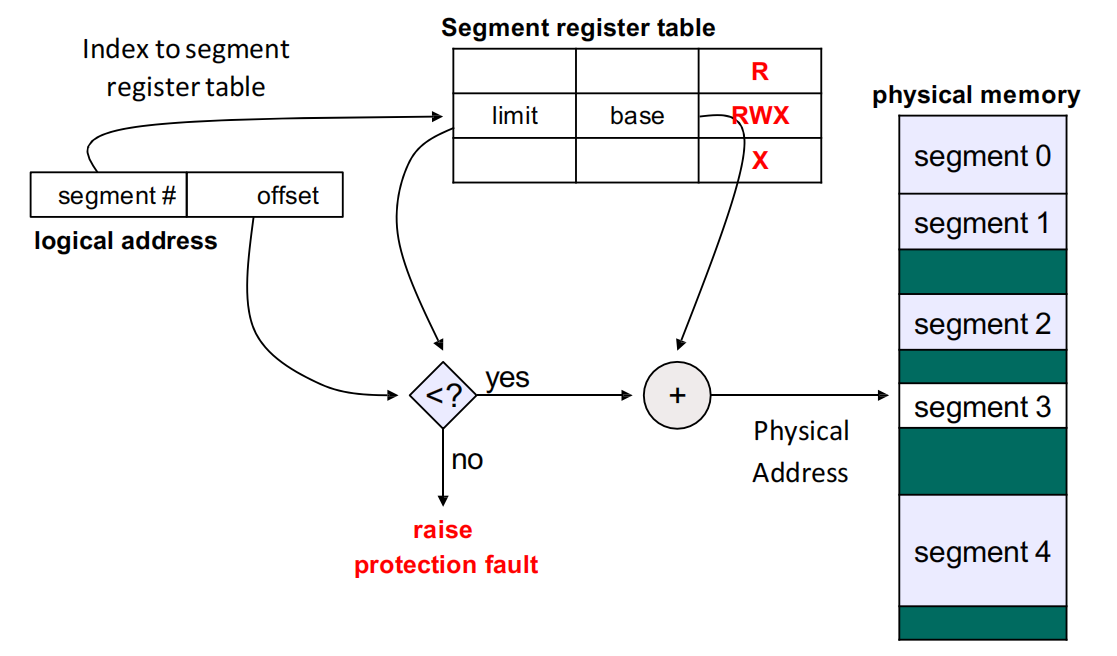
Segment Lookup 过程
对逻辑地址 ⟨s, d⟩:
- 用
s索引 segment table - 取出该段的
base、limit和权限位 - 检查
d < limit - 检查该访问是否满足
R/W/X权限 - 若检查通过,则 \(physical\ address = base + d\),否则触发 protection fault
Segmentation 解决了什么,又没解决什么
它解决了:
- 地址空间按程序逻辑结构组织的问题
- 段级别的保护问题
- 段可以分别装载、分别设置权限的问题
但它仍然可能有 external fragmentation,因为每个 segment 依然通常需要连续放在物理内存中。这正是后续 paging 设计要进一步改善的问题。
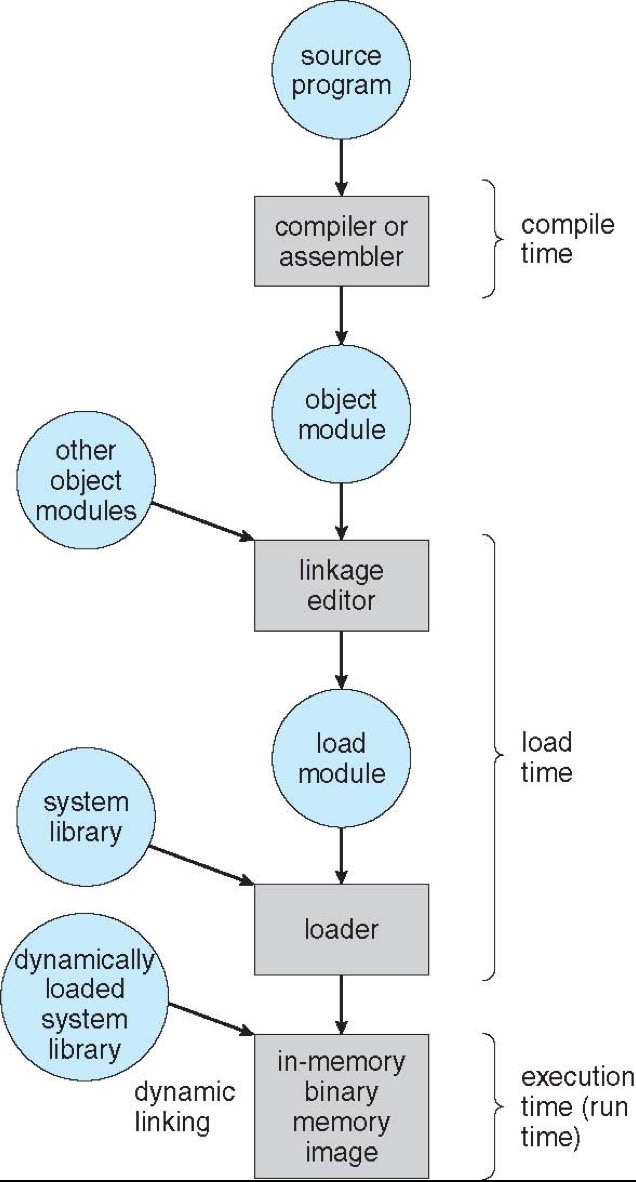
一个程序生命周期中,同一个地址会经历多次绑定(Address Binding):
- source code addresses:符号地址,如变量名
- relocatable addresses:相对某模块起点的偏移,如“离模块起始 14 bytes”
- absolute / physical addresses:真正用于访问内存的地址
每一次 binding,本质上都是把一个地址空间映射到另一个地址空间。
指令和数据绑定到内存的三个时机
- Compile time binding
- 如果编译时就知道程序将放到哪里,可以直接生成 absolute code
- 但起始位置一变,就需要重新编译
- Load time binding
- 编译时不知道最终装载位置,就生成 relocatable code
- 装载时再决定实际位置
- Execution time binding
- 运行时才完成地址翻译
- 允许进程在执行过程中被移动
- 需要硬件支持地址映射
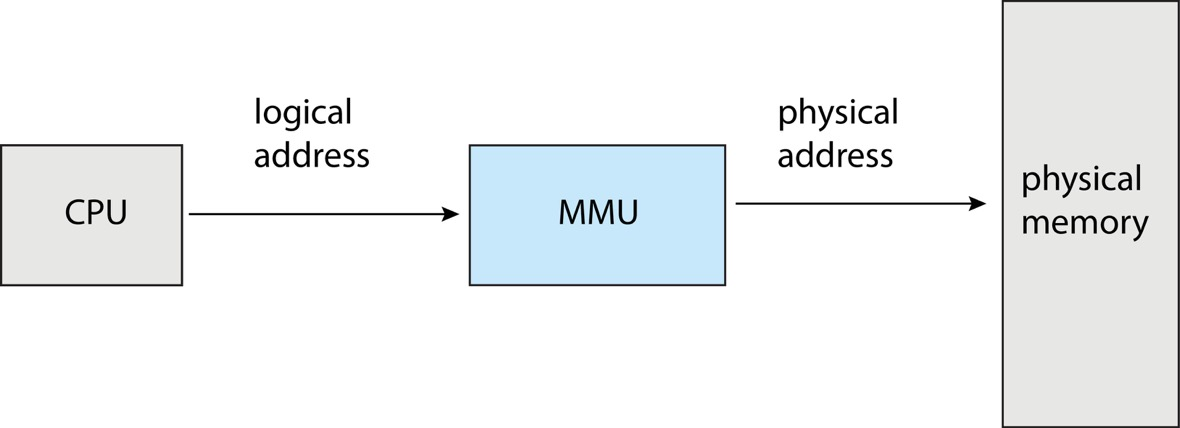
Logical Address vs Physical Address
- Logical address:CPU 生成的地址,也常称 virtual address
- Physical address:Memory unit 真正看到的地址
- Logical address space:程序可能产生的全部逻辑地址集合
- Physical address space:程序最终对应到的全部物理地址集合
逻辑地址空间与物理地址空间彼此分离,是现代内存管理的核心思想。
4 Memory-Management Unit (MMU)¶
MMU(Memory-Management Unit)是运行时完成逻辑地址到物理地址映射的硬件部件。
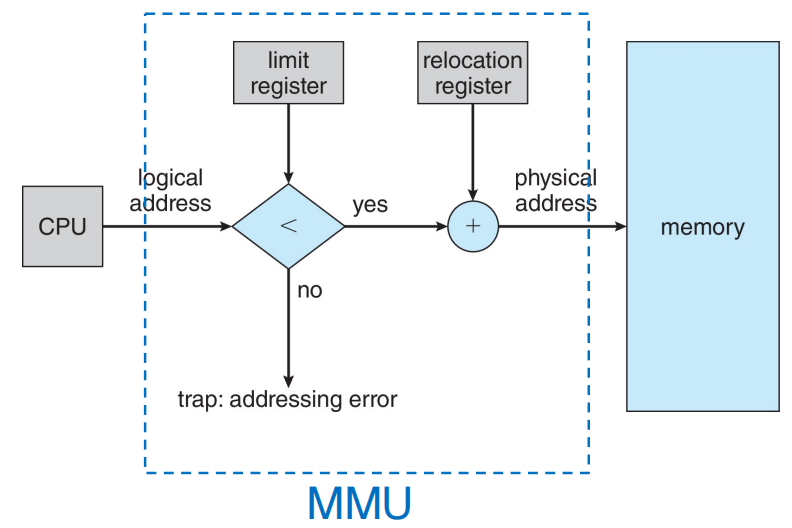
MMU 的最简单形式:relocation register
可以把 base-register 方案视为 MMU 的一个最简单特例:
base register又可称为 relocation register- 每次用户进程发出地址时,都把该值加到逻辑地址上
若某进程逻辑地址空间为 0 ~ max,而 relocation register 的值为 R,则其可访问的物理地址范围就是:
这就是最基本的execution-time binding。
示例
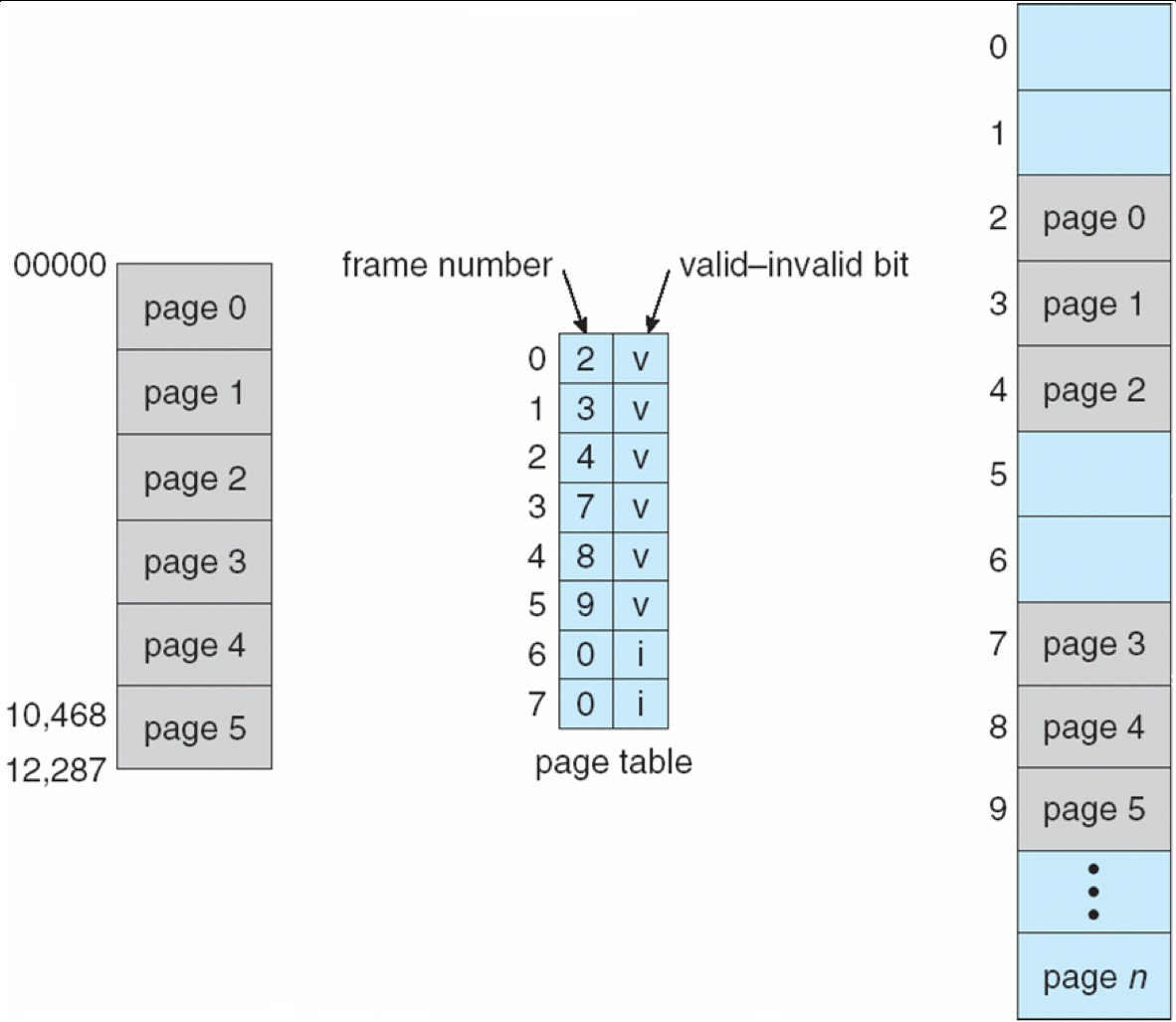
5 Paging¶
Paging 的核心思想是把连续分配(contiguous allocation)改成非连续分配(noncontiguous allocation):
- 进程的逻辑地址空间被切成固定大小的 page
- 物理内存被切成同样大小的 frame
- 一个进程的多个 page 可以分别装入任意空闲 frame,不要求物理上连续
这样一来,进程不再依赖大块连续空闲区,从而避免了 variable partitions 中典型的 external fragmentation 问题。
Paging 的基本做法
- OS 需要跟踪哪些 frame 空闲、哪些 frame 已分配
- 程序若有
N个 pages,就需要找到N个空闲 frames - 同时建立从 logical page -> physical frame 的映射,这个映射表就是 page table
为什么页/帧大小通常取 \(2\) 的幂(常见如 \(4 \, \text{KB}\))?
这样页内偏移可以直接由地址的低位表示,硬件切分地址、拼接物理地址都会非常自然,地址翻译电路也更简单。
Paging 虽然消除了外部碎片,但仍然会产生 internal fragmentation。
示例:Internal Fragmentation
若 \(\text{page size} = 2048 \, \text{bytes}\),\(\text{program size} = 72,766 \, \text{bytes}\),则程序需要 \(35\) 个完整 page 以及最后一个只用到 \(1086\) bytes 的 page,因此最后一个 frame 中浪费的空间为 \(2048 - 1086 = 962 \, \text{bytes}\)
Paging 中碎片的特点
- 最坏情况:浪费 \(1 \, \text{frame} - 1 \, \text{byte}\)
- 平均情况:若均匀分布,平均浪费约为 \(\frac{1}{2} \, \text{frame size}\)
- 实际中通常比这个理论平均值更小,因为一个程序往往只有最后一个 page 存在碎片
Small frame sizes more desirable than large frame size?
- 页更小:内部碎片更少,但 page table entry 更多,页表更大,TLB 压力也更大
- 页更大:页表更小、TLB 覆盖范围更大,但内部碎片更严重
因此实际系统会在两者之间折中,常见基本页大小是 4 KB,也常支持 64 KB、2 MB、1 GB 等大页(huge page)。
在 paging 中,OS 至少要维护两类核心信息:
| 数据结构 | 作用 |
|---|---|
| Page Table | 记录某进程的 虚页号(VPN) 到 物理帧号(PFN) 的映射 |
| Frame Table | 记录每个物理 frame 当前是否空闲、属于哪个进程、分配状态如何 |
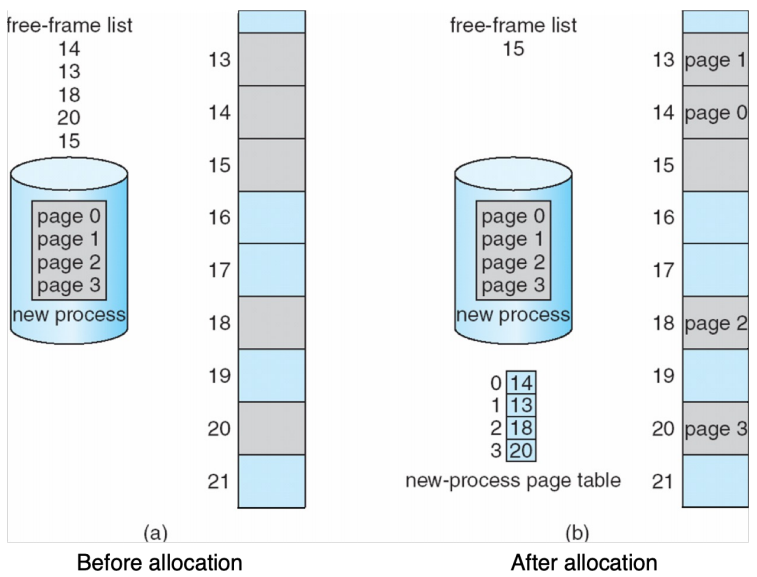
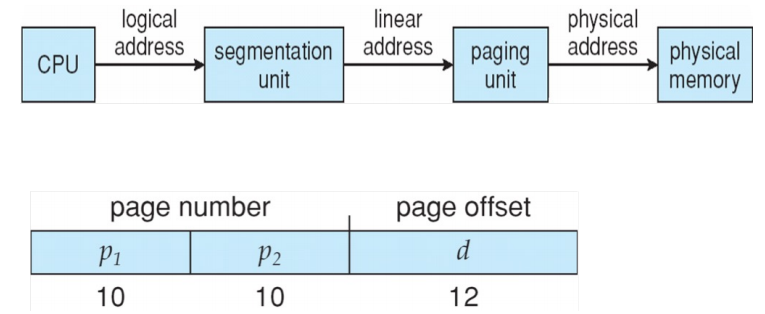
在 paging 中,一个逻辑地址会被拆成两部分:
- page number(\(p)\):作为 page table 的索引
- page offset(\(d\)):表示该地址在页内的偏移
若 page size 为 \(2^n\) bytes,则低 \(n\) 位是 offset,剩余高位是 page number:

查表后得到对应 frame number,再与 offset 拼接,即可得到物理地址:
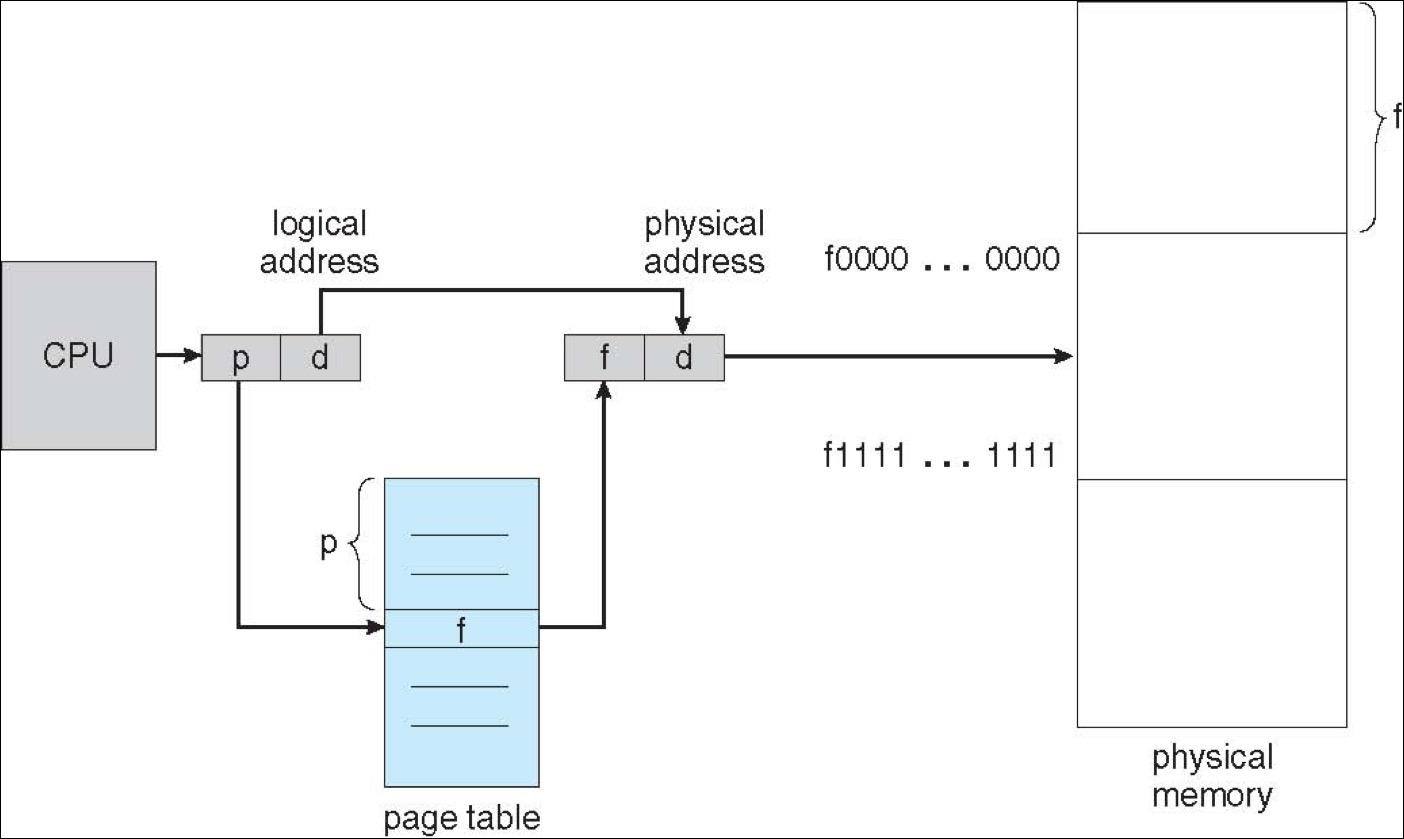
因为 page 和 frame 大小相同,所以页内偏移不变,只需要把页号换成帧号。
示例
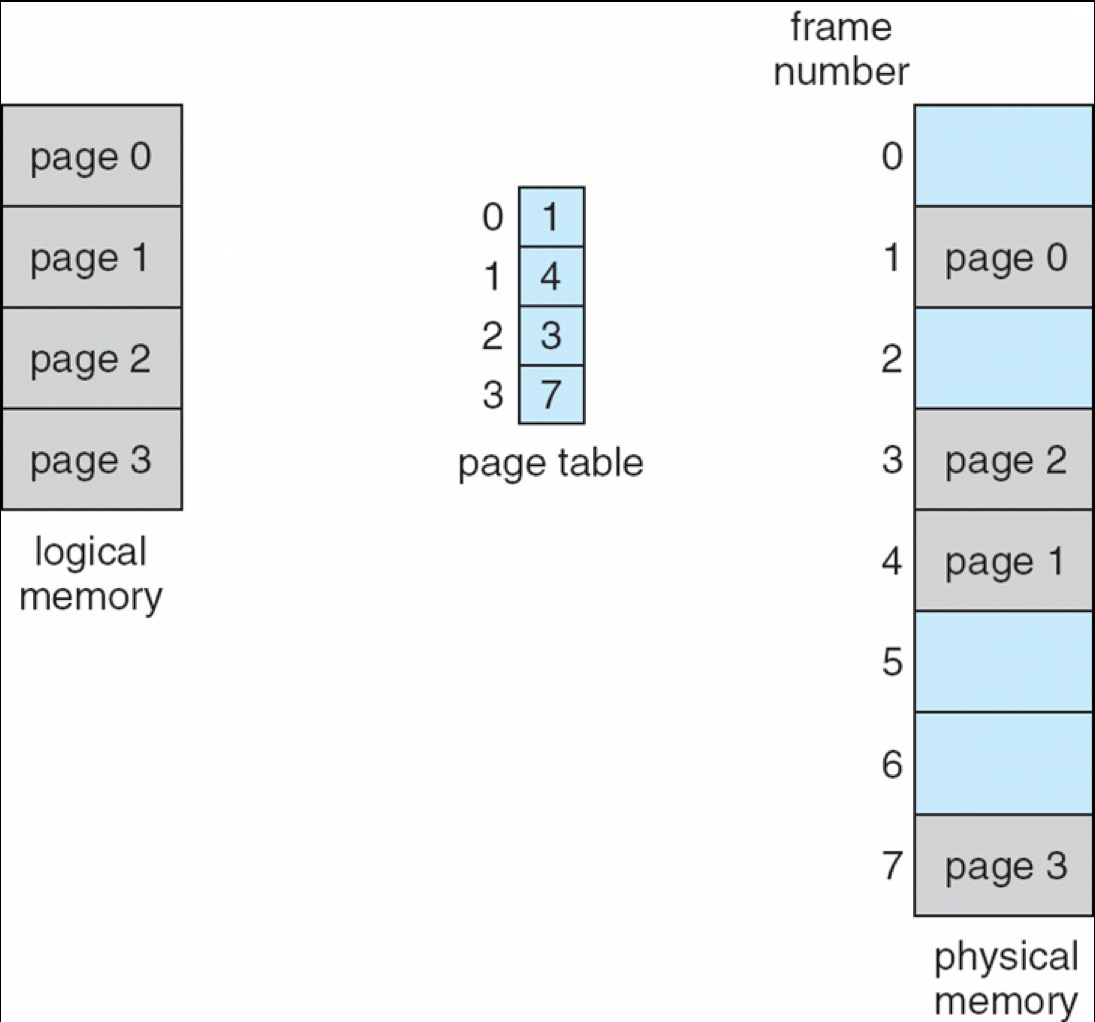
What is the page table?
设逻辑地址宽度 \(m = 4\),page size 为 \(4 \, \text{bytes} = 2^2\),则高 \(2\) 位是 page number,低 \(2\) 位是 offset。
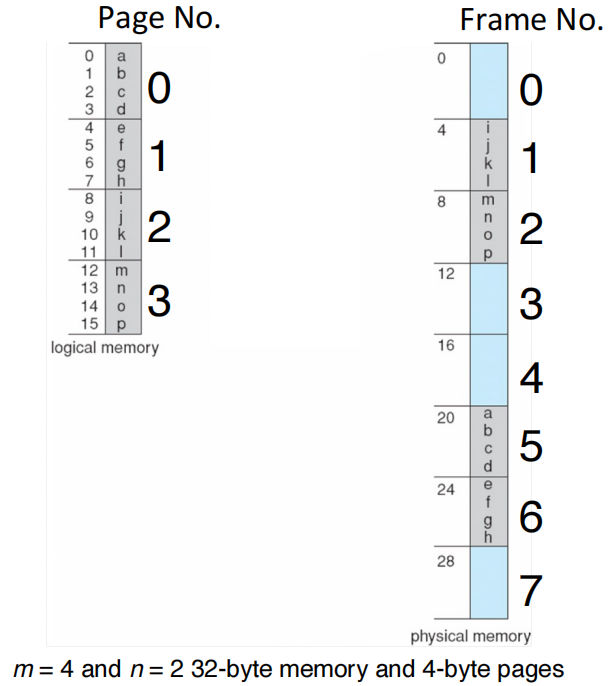
答案
| 逻辑页号(Page No.) | 物理帧号(Frame No.) |
|---|---|
| 0 | 5 |
| 1 | 6 |
| 2 | 1 |
| 3 | 2 |
6 Paging Hardware, TLB and EAT¶
6. 1 Page Table Hardware Support¶
Simplest Case
把整个 page table 放到一组专用寄存器里。
- 优点:访问寄存器非常快,因此地址翻译效率高。
- 缺点:寄存器数量有限,只适合非常小的页表,且 context switch 时还要保存 / 恢复整组寄存器,代价较高
更常见的做法是把 page table 放在主存中:
- PTBR(Page-Table Base Register):指向当前进程页表的起始地址
- PTLR(Page-Table Length Register):指出页表长度
Does PTBR contain physical or logical address?
物理地址。否则为了找到页表本身,又要先做一次地址翻译,就会出现递归依赖。
若页表放在主存中,则一次普通内存访问通常需要:
- 先访问页表,找到 frame number
- 再访问目标数据 / 指令
也就是说,每次访问可能需要两次主存访问,这就是引入 TLB 的直接动机。
6. 2 TLB¶
TLB(Translation Look-aside Buffer)是页表项的高速缓存,可理解为 page table 的 cache。
TLB 的基本作用
- 若 page number 已经在 TLB 中,则无需再访问主存中的 page table,直接得到 frame number
- 若不在,则发生 TLB miss,需要访问 page table,并把相应翻译结果装入 TLB
TLB 通常很小,但速度极快,常见规模是 64 ~ 1024 entries。
TLB 常由 associative memory(联想存储器 / CAM)实现,能在很短时间内完成地址翻译匹配。
Associative Memory 的关键特征
- 它不是按地址访问,而是按内容是否匹配访问
- 给定 key(如 page number),硬件并行比较所有候选项
- 若匹配成功,直接返回对应 value(如 frame number)
每个进程都有自己的 page table,因此进程切换时,TLB 中缓存的翻译结果也可能随之失效。
| 方案 | 做法 | 特点 |
|---|---|---|
| Flush TLB | 每次 context switch 直接清空 TLB | 简单,但会增加后续 miss |
| ASID | 给每个 TLB entry 打上 Address-Space Identifier(ASID) | 切换进程时不必全部清空,性能更好 |
为什么内核映射常能保留在 TLB 中
某些 TLB 项可以被标成 global,表示这类映射对多个进程都成立,例如内核空间的固定映射,因此 context switch 时不必移除。
不同体系结构对 TLB miss 的处理
- MIPS:TLB miss 通常由 OS 处理异常
- x86:TLB miss 后的 page table walk 通常由硬件自动完成
现代处理器中的 TLB 通常不止一层,也不只缓存一种页大小。
现代 TLB 的常见组织
- Instruction micro TLB:专门缓存取指地址翻译
- Data micro TLB:专门缓存数据访问翻译
- Main TLB:容量更大,作为更靠后的翻译缓存层
以 ARM Cortex-A73 为例,不同 TLB 还能同时缓存 4 KB / 16 KB / 64 KB 页面以及 1 MB / 2 MB / 1 GB 等大块映射。
TLB 的匹配并不只看虚页号,往往还会一起检查页大小、ASID、是否 global、虚拟化场景下的 VMID、当前访问所处的 memory space / privilege state等。
6. 3 Effective Access Time (EAT)¶
TLB 的价值可以用 EAT(Effective Access Time)衡量。
示例
设主存访问时间为 \(100 \, \text{ns}\),TLB hit ratio 为 \(80 \, \%\),则:
- TLB hit:只需一次主存访问,总计 \(100 \, \text{ns}\)
- TLB miss:需要访问页表再访问目标,总计 \(200 \, \text{ns}\)
因此 \(EAT = 0.80 \times 100 + 0.20 \times 200 = 120 \, \text{ns}\),平均访问时间比理想情况慢了约 \(20 \, \%\)
若 hit ratio 为 \(99 \, \%\),则 \(EAT = 0.99 \times 100 + 0.01 \times 200 = 101 \, \text{ns}\),这时额外开销只有约 \(1 \, \%\),说明 TLB 命中率对性能非常敏感。
多级页表下的代价
若没有 TLB 命中,且页表是 k 级,则硬件 page walk 可能需要多达:
次内存访问(k 次查页表,1 次访问目标数据)。因此层次越深,就越依赖高命中率的 TLB。
7 Memory Protection and Page Sharing¶
Paging 中的保护通常是按页完成的,每个 page table entry(PTE)里除了 frame number,还会包含一组控制位。若访问违反这些约束,就会触发 trap / fault 进入内核。
常见 PTE 控制位
- present / valid bit:该页当前是否有合法物理映射
- R / W / X:可读、可写、可执行
- user / kernel:用户态能否访问
- accessed / dirty 等附加状态位(不同体系结构细节不同)
present / valid bit 的意义
- present = 1:该页当前有合法的物理 frame,可继续访问
- present = 0:该页当前不可直接访问,可能是未映射,也可能是尚未装入内存
除了传统的 R/W 权限,现在的体系结构还普遍支持禁止执行权限:
| 名称 | 含义 |
|---|---|
| XD / NX / XN | 该页不可执行,常用于保护数据页 |
| PXN | 特权态不可执行,常用于防止内核去执行本应只给用户态使用的页 |
这些位实现了代码页和数据页的严格分离,防止把普通数据当成指令执行,减少了代码注入、ROP 等攻击面的可用空间。
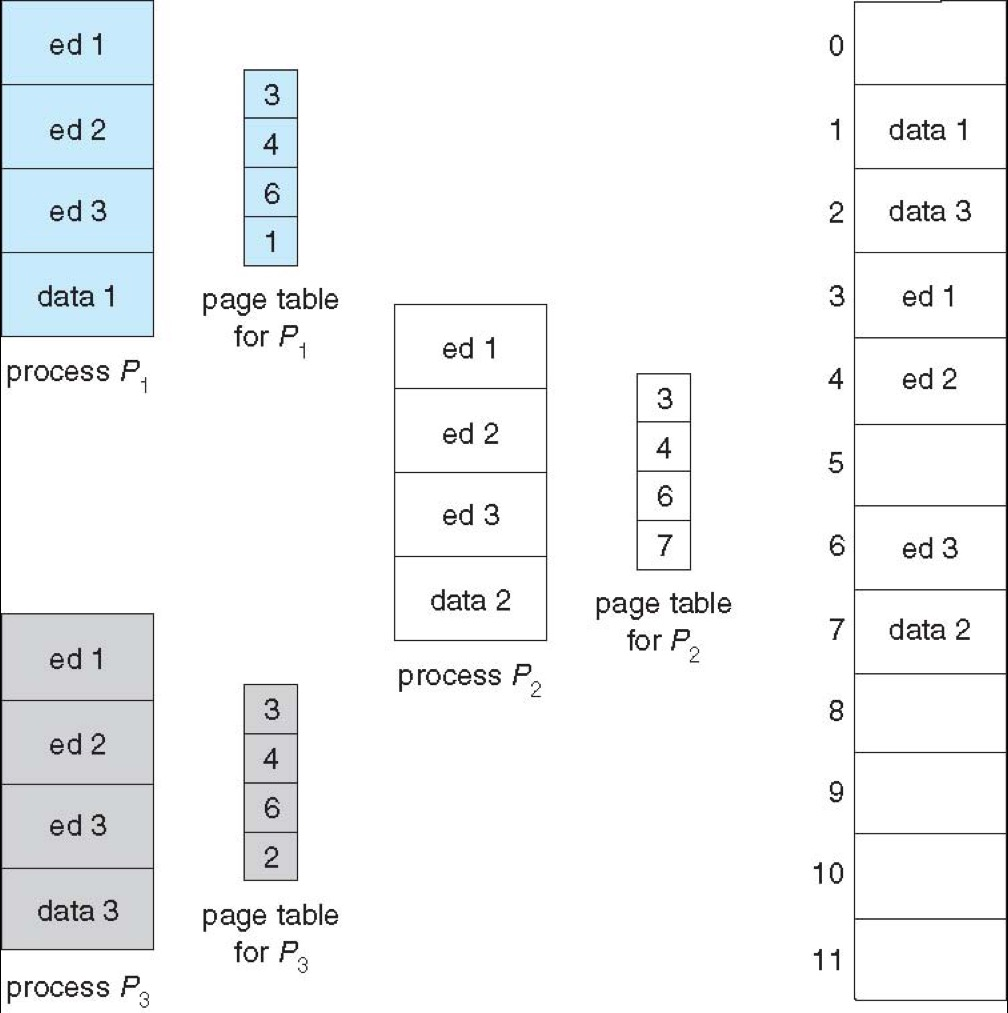
Paging 天然支持页级共享,共享的典型场景包括:同一个程序的只读代码段、shared libraries、进程间通信中的 shared memory。
只要代码是 reentrant code(可重入、非自修改代码),多个进程就可以共享同一份物理页,而各自的数据页仍保持私有,这也是为什么多个进程运行同一程序时,系统通常不需要为每个进程复制一整份只读代码。
8 Structure of Page Table¶
8. 1 One-Level Page Table¶
单级页表的优点是概念简单,但在大地址空间下会占用大量内存。
示例:32-bit logical address space and 4KB page size
\(4 \, \text{KB} = 2^{12} \, \text{bytes}\),故页表一共有 \(2^{32} / 2^{12} = 2^{20}\) 项 entries
每个 PTE 为 \(4 \, \text{bytes}\),则页表大小 = \(2^{20} \times 4 = 2^{22} \, \text{bytes} = 4 \, \text{MB}\),也就是说,每个进程仅页表就要 4 MB
单级页表的问题
- 每个进程都需要自己的整张页表
- 即使进程只用了很少一部分虚拟地址空间,也要预留整张大表
- 大页表本身通常还要求物理上连续
真实程序的逻辑地址空间往往有很多 holes,例如 ELF 可执行文件通常只用到少量离散区域,而单级页表却必须为整个虚拟空间的每一页都保留表项,故会造成浪费。
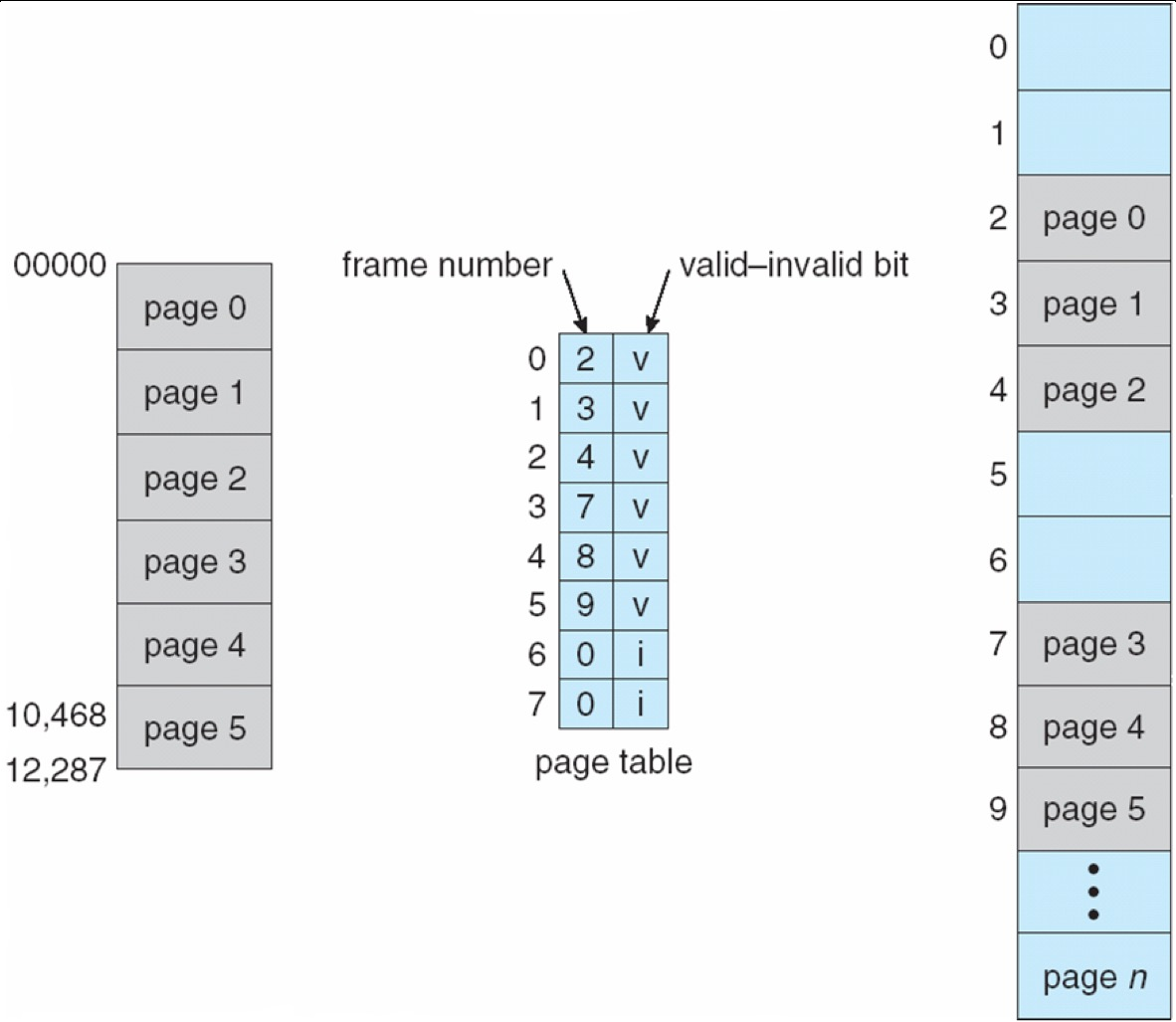
Can we break down page table into pages? Page size is 4KB, how many entries can fit in one page?
单页可容纳的表项数 \(= 2^{12} \div 4 = 2^{10} = 1 \text{K}\) 个
页目录(Page Directory)本身也是一个页(4KB),里面有 1024 个目录项,每个项指向一个小页表
8. 2 Hierarchical Page Tables¶
为了节省页表空间,可以把页表本身也继续分页,只在真正需要时分配相应的下级页表页。
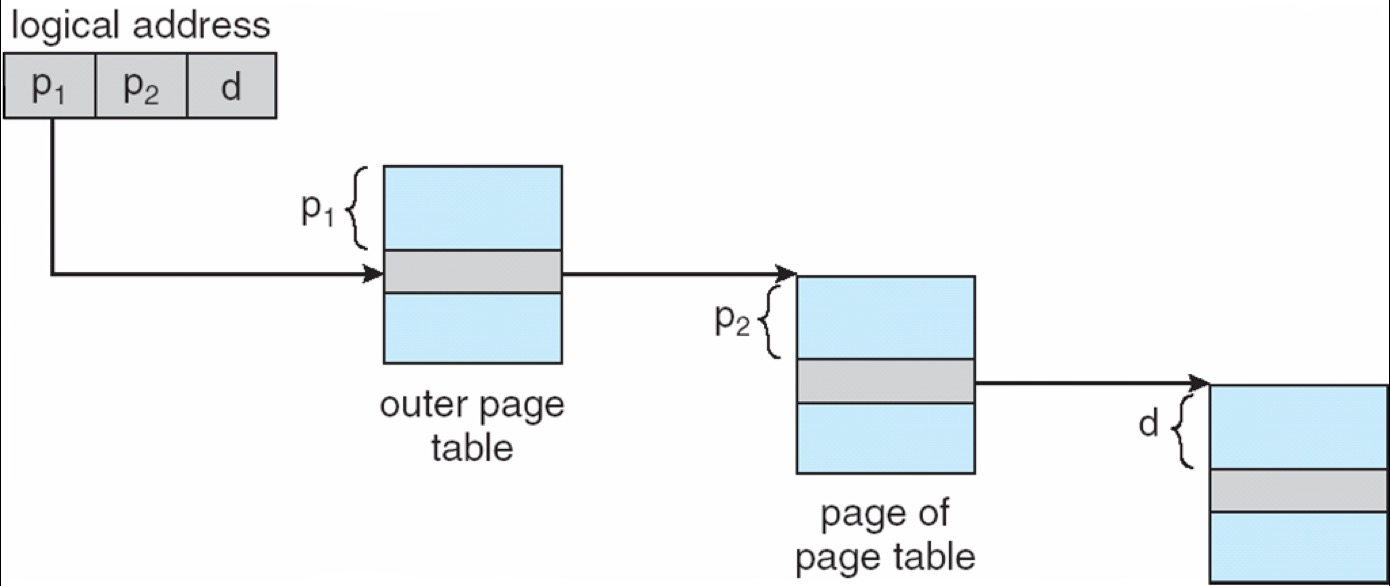
8. 2. 1 Two-Level Paging¶
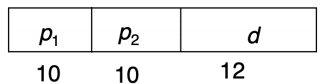
在两级页表中,逻辑地址通常拆成三段:
- \(p_1\):索引一级页表(page directory)
- \(p_2\):索引二级页表
- \(d\):页内偏移
示例:32-bit + 4 KB page + 4-byte PTE
页面大小是 \(4\ \text{KB} = 4 \times 1024 = 2^{12} \, \text{bytes}\),页内偏移 \(d\) 占 12 位。
逻辑地址总长度是 32 位,减去 12 位的页内偏移,剩下的高位全部是页号,即 \(32 - 12 = 20\) 位,整张单级页表总共有 \(2^{20}\) 个表项。
一个页表页能装 \(2^{12} \div 4 = 2^{10} = 1 \text{K}\) 个 表项,总表项数 \(2^{20}\) ÷ 每个页表页装 \(2^{10}\) 项 = \(2^{10}\) 个二级页表页。
这就得到经典的 \(10 + 10 + 12\) 地址划分:
为什么多级页表能省内存
因为只有虚拟地址空间中实际用到的那部分区域,才需要分配对应的二级页表。
若一个程序只用到前几个页面和最后几个页面,就只需少量二级页表,而不必为整个中间空洞都分配表项。
注意最坏情况
若整个虚拟地址空间都被密集使用,多级页表并不会减少所有 PTE 的总数。
它节省的是稀疏地址空间下未使用区域对应的页表页;在最坏情况下,两级页表的总大小甚至会比单级略大(因为还多了一层目录)。
8. 2. 2 64-bit Logical Address Space¶
地址空间扩大到 64-bit 后,虚拟页总数急剧增长,而每一页页表能容纳的表项数仍受 page size / PTE size 限制,因此只能通过增加页表层数来覆盖更大的地址空间,常见切分方式包括:
- x86-64 / AMD64(48-bit VA):常见为 \(9 + 9 + 9 + 9 + 12\)
- ARM64(39-bit VA):常见为 \(9 + 9 + 9 + 12\)
- ARM64(48-bit VA):常见为 \(9 + 9 + 9 + 9 + 12\)
其中 \(12\) 是 4 KB 页的 offset,\(9\) 对应一级页表索引,因为一个 4 KB 页表页若每项 8 bytes,正好可容纳 \(2^{12} \div 8 = 2^{9}\) 个表项
8. 3 Hashed Page Table¶
- 基本思路:将 virtual page number 经过 hash 映射到某个桶,桶中维护冲突链表,每个元素至少包含 virtual page number、frame number 和 ext pointer,沿链查找匹配项,找到后返回 frame number
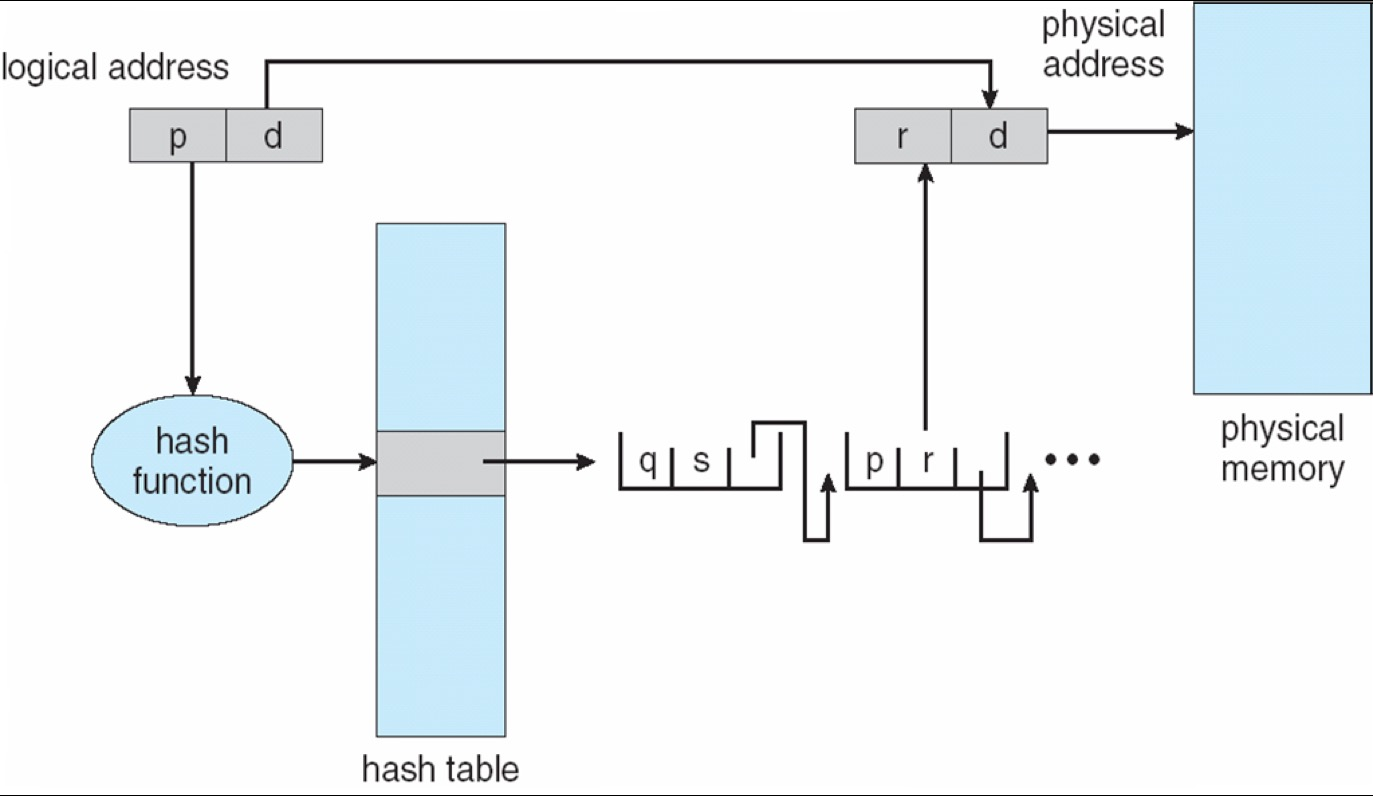
Hashed page table 特别适合大于 32-bit 的稀疏地址空间,因为不必像传统数组页表那样为巨大虚拟空间预留整张稠密表。
Clustered page tables
一个哈希表项可以覆盖多个相邻页面,以减少元数据开销。
8. 6 Inverted Page Table¶
倒排页表(Inverted page table) 的出发点是:与其按每个进程的每个虚页建表,不如按每个物理 frame 建表。
- 整个系统只有一张 Inverted page table,每个物理 frame 对应一个表项,每项记录该 frame 属于哪个进程以及对应哪个 virtual page。
- 页表大小与物理内存大小成正比,而不是与巨大的虚拟地址空间成正比,因此内存开销更可控。
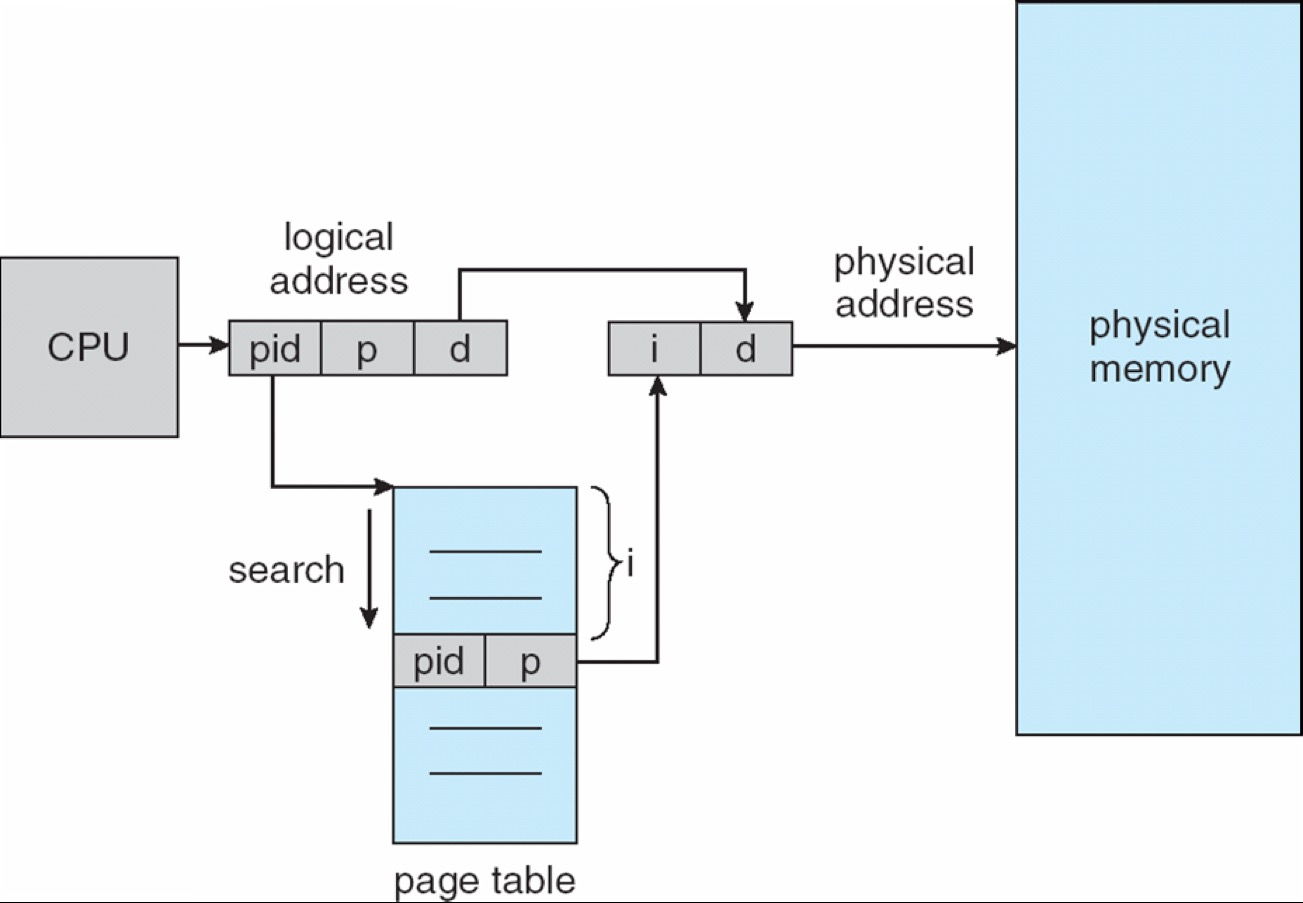
代价
- 从虚拟地址翻译到物理地址时,不能像普通页表那样直接索引
- 需要查找有没有某个
(pid, vpn)对应的物理 frame - 若没有额外加速,TLB miss 代价会非常高
为什么共享内存在反置页表里更麻烦?
因为一个物理页可能被多个进程、多个虚拟页同时映射,而每个物理 frame 只有一个表项的结构天然不擅长表达这种一对多关系,所以需要额外机制补充。
9 Swapping¶
Swapping 的目标是用磁盘上的 backing store(通常是磁盘上的 swap 区域)暂时扩展物理内存容量,某个进程可以暂时从内存换出到磁盘,之后再从磁盘换回内存继续执行。
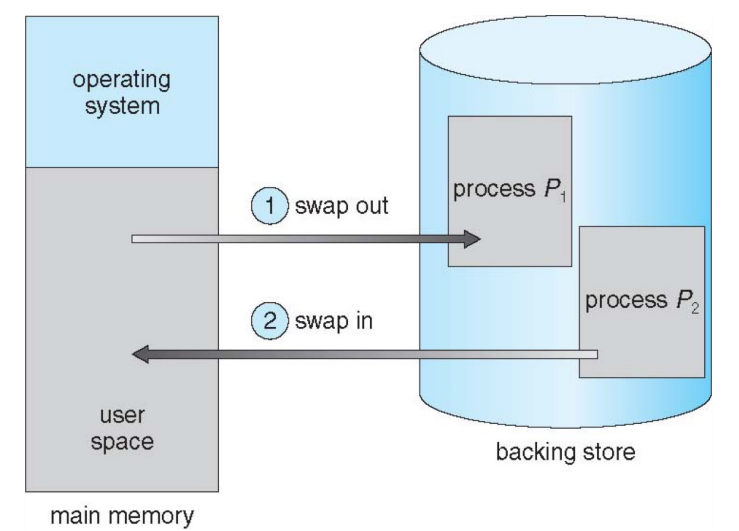
换回时必须回到原来的物理地址吗?
不需要。只要仍然通过 execution-time binding / page table 来完成地址翻译,换入后的物理位置可以改变,更新映射关系即可。
Swapping 一般只会在 memory pressure 下发生,由于涉及磁盘 I/O,其延迟远高于主存访问,若调度器选中的下一个进程不在内存中,就必须先换入,context switch 时间会急剧上升。
示例:100MB process swapping to hard disk with transfer rate of 50MB/sec
仅换出操作就需要 2000 毫秒,再加上换入一个同等大小进程的耗时,光是交换环节的上下文切换耗时就达到了 4000 毫秒,这说明整进程 swapping 会让 context switch 变得极其昂贵。
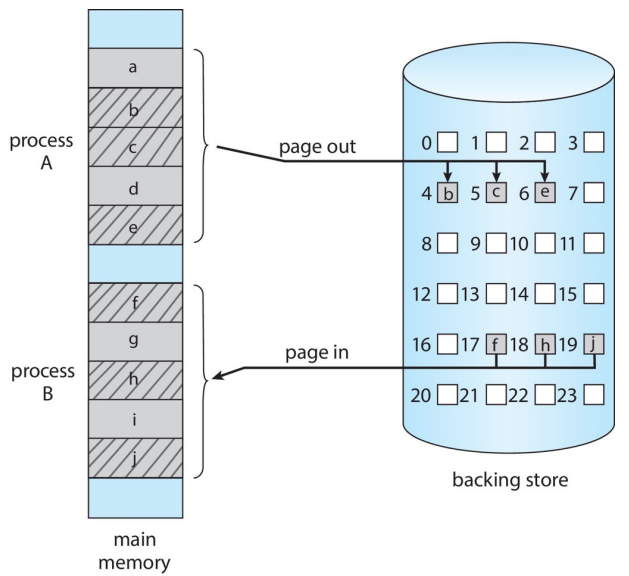
可以通过优化降低耗时:只交换进程真正正在使用的内存数据,而非整个进程,以此减少实际交换的数据量。
分页系统中,通常不再整进程换入换出,而是按页交换,只把当前不活跃的 pages 换出,只在需要时再把对应 pages 换回,这样能显著降低一次换页所需的 I/O 量,也是 demand paging / virtual memory 的基础前提之一。
由于 Flash 空间有限且有写入寿命限制,且 Flash 与 CPU 之间吞吐较差,频繁 swapping 会带来明显功耗与性能问题,所以移动设备通常不太采用传统 swapping。
移动系统常见替代策略
- iOS:要求应用在内存紧张时主动释放可回收内存;只读数据可丢弃,需要时再从 flash 载回;若应用不配合,可能被终止
- Android:低内存时可能直接终止应用,但通常会先把应用状态写回 flash,以便后续快速恢复
10 Paging in Real Systems¶
10. 1 Intel IA-32¶
Intel IA-32 同时支持 segmentation 和 segmentation + paging 两种内存管理模式。
单个段的最大容量为 4GB,每个进程最多可拥有 16K 个段,这些段被分为两类:
- 进程私有段:最多 8K 个,存放在局部描述符表(Local Descriptor Table, LDT)中
- 所有进程共享的全局段:最多 8K 个,存放在全局描述符表(Global Descriptor Table, GDT)中
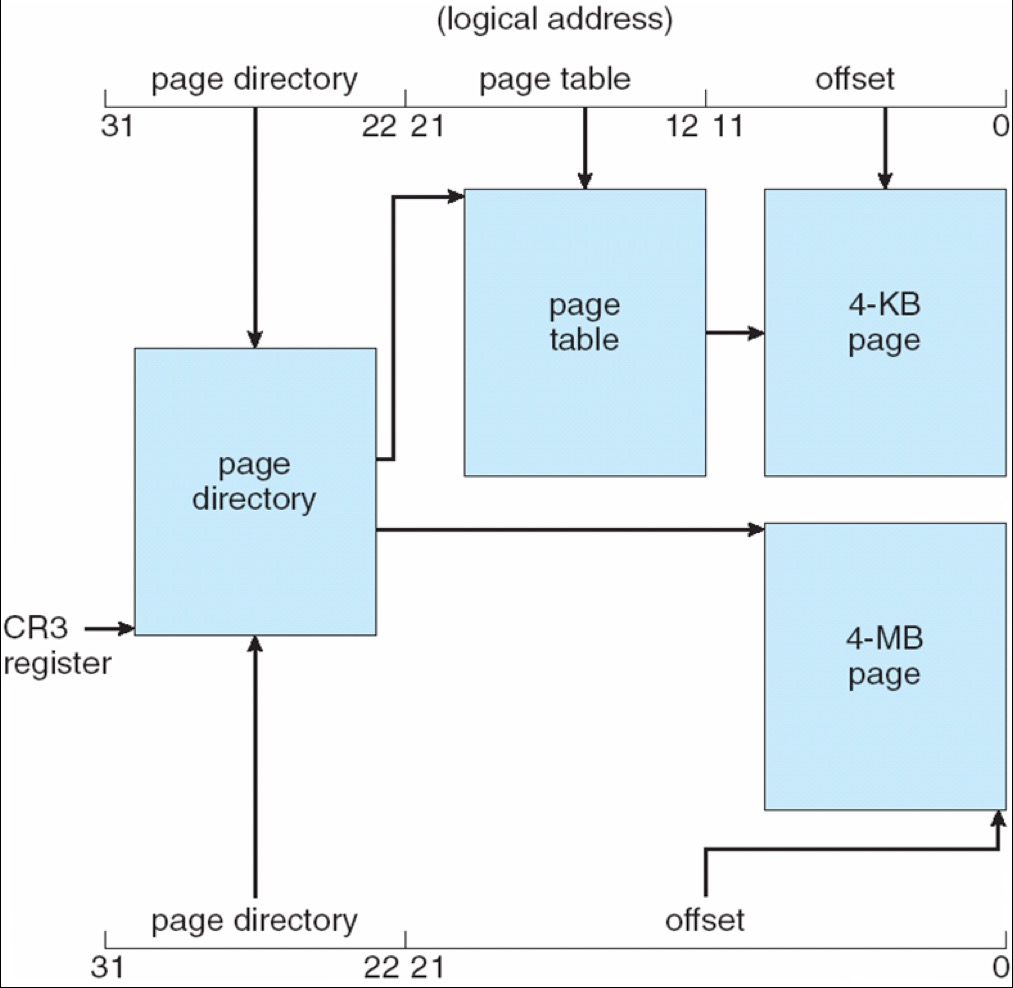
CPU 运行时会生成逻辑地址,其中的段选择符(Selector)会被送入分段单元(segmentation unit),先转换为线性地址(linear address),再由 paging unit 转成最终物理地址:
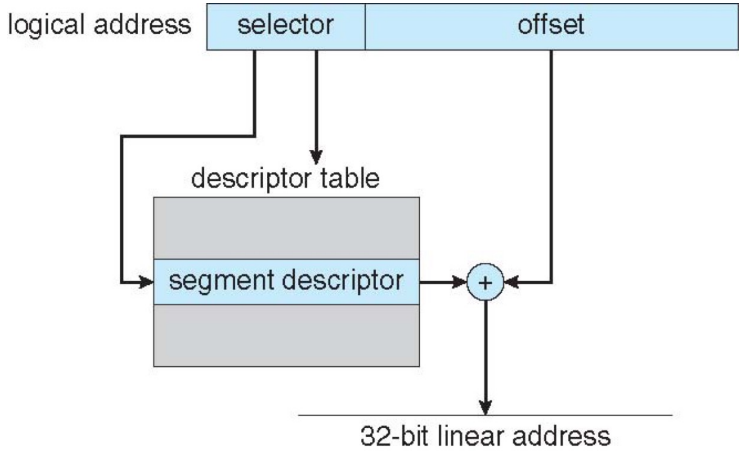
段选择符由三部分组成:13 位的段号(s)、1 位的局部/全局标识位(g)、2 位的保护权限位(p):
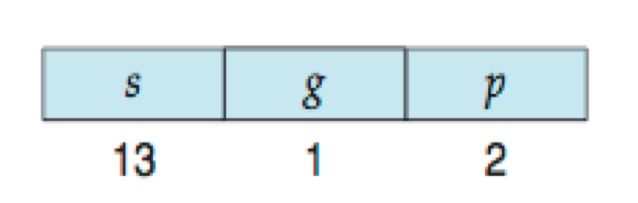
段的基地址存放在段寄存器中,其中 CS(代码段寄存器)负责记录当前执行指令的代码段地址,DS(数据段寄存器)负责记录数据段地址。
此外,GDTR 和 LDTR 寄存器分别存放 GDT 和 LDT 的基地址。
在启用 paging 后,IA-32 常见页大小为 4 KB 和 4 MB。
10. 2 Intel PAE and x86-64¶
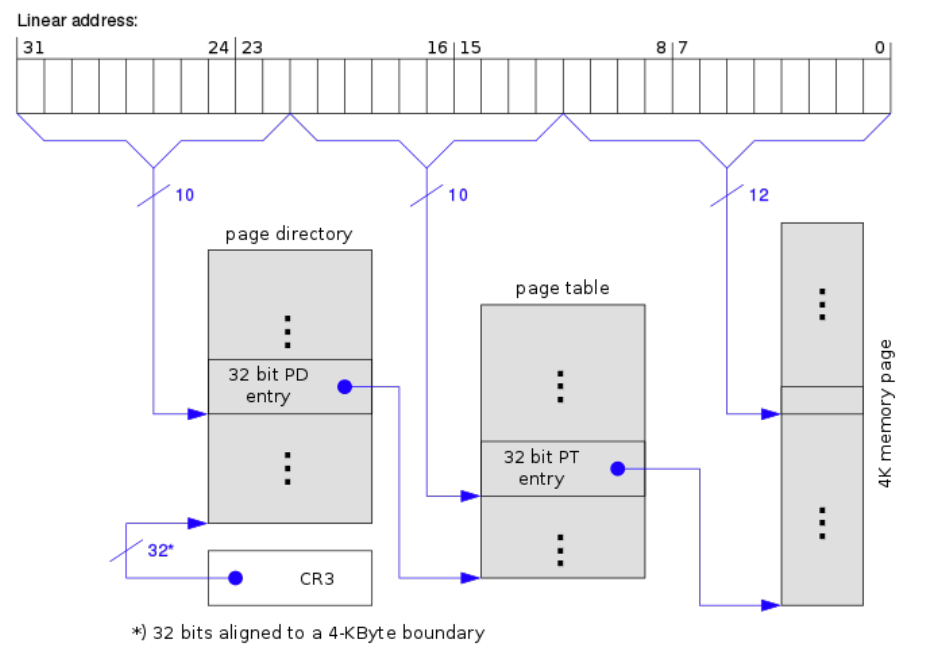
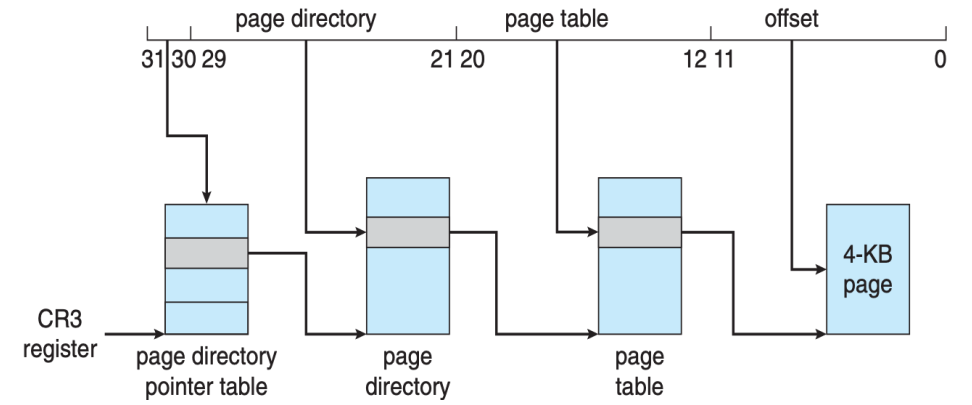
为突破 32-bit 物理地址的 4GB 限制,Intel 引入了 物理地址扩展(PAE, Physical Address Extension)技术。
PAE 将页目录项与页表项扩展到64 位,同时把线性地址的最高两位用于索引页目录指针表,形成 3-level paging,使得物理地址空间可扩展到 36 位,可支持最高 64GB 的物理内存。
但 32 位进程的虚拟地址空间仍保持为 4GB,而 64 位的页表项则可支持寻址 36 位(64GB)的物理地址。
Intel x86-64 架构是当前主流的 Intel x86 处理器架构,名义上是 64-bit 架构,但实际常见只实现 48-bit 虚拟地址。
它支持 4KB、2MB、1GB 三种页大小,采用四级分页层次结构,由于原生支持大内存寻址,通常不再需要物理地址扩展(PAE)技术。

10. 3 Linux 中的页表¶
Linux 在 IA-32 架构下仅使用 6 个段:包括内核代码段、内核数据段、用户代码段、用户数据段,以及任务状态段(TSS)和默认 LDT 段。
特权级上,Linux 仅使用了 x86 架构提供的 4 个特权级中的两级:内核态运行在 Ring 0,用户态运行在 Ring 3。
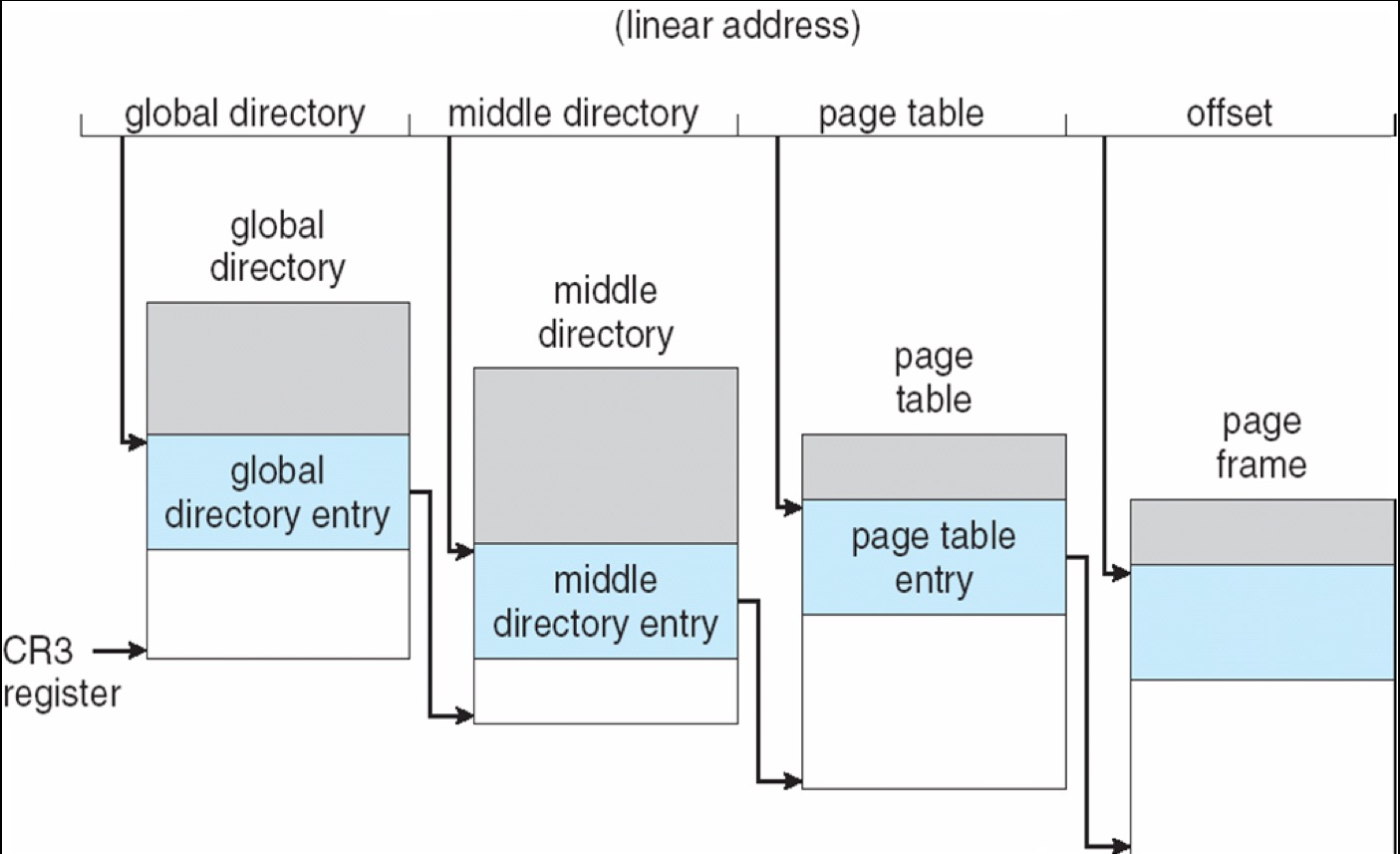
分页机制上,Linux 为 32 位与 64 位系统设计了通用的四级分页模型,会根据不同场景进行简化适配:
- 在普通 32 位系统的两级分页场景中,会省略中间目录与上级目录;
- 在带 PAE 的 32 位系统的三级分页场景中,会省略上级目录。
10. 4 ARM32 and ARM64¶
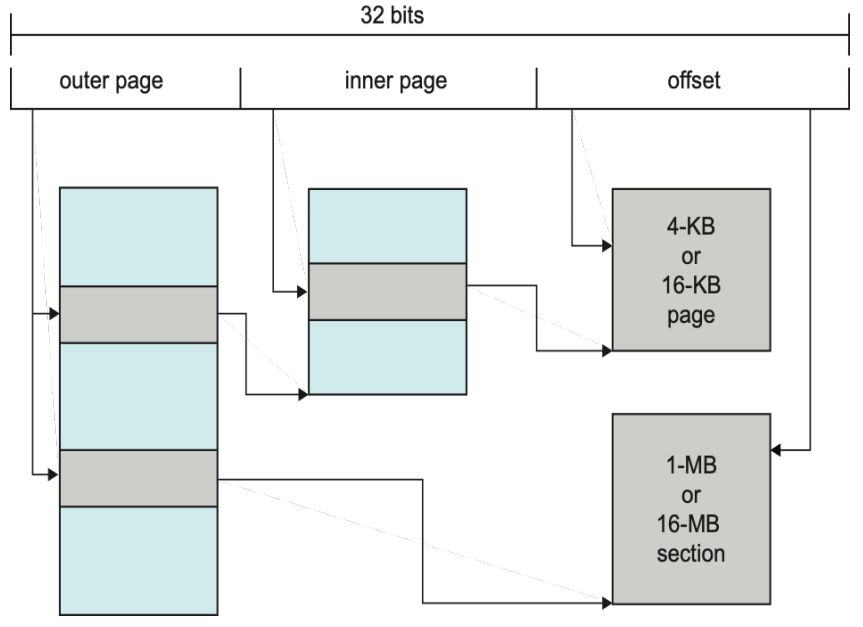
ARM32 是一款低功耗 32 位 CPU,其内存管理特性如下:
- 支持多种页大小:4KB/16KB 的标准页,以及 1MB/16MB 的大页
- 分页机制:大页(sections)采用一级分页,标准小页采用两级分页
- TLB(转换旁视缓冲器)采用两级结构,外层包含两个微型 TLB(micro TLB),分别用于数据和指令地址,内层为一个主 TLB
- TLB 查找流程:优先查询内层主 TLB;若未命中,再查询外层的两个微型 TLB;若仍未命中,则由 CPU 执行页表遍历(page table walk)
ARM64 是当前移动平台的主流芯片架构,广泛应用于苹果 iOS、谷歌安卓等设备中,在寻址与页表结构上,它支持两种配置:
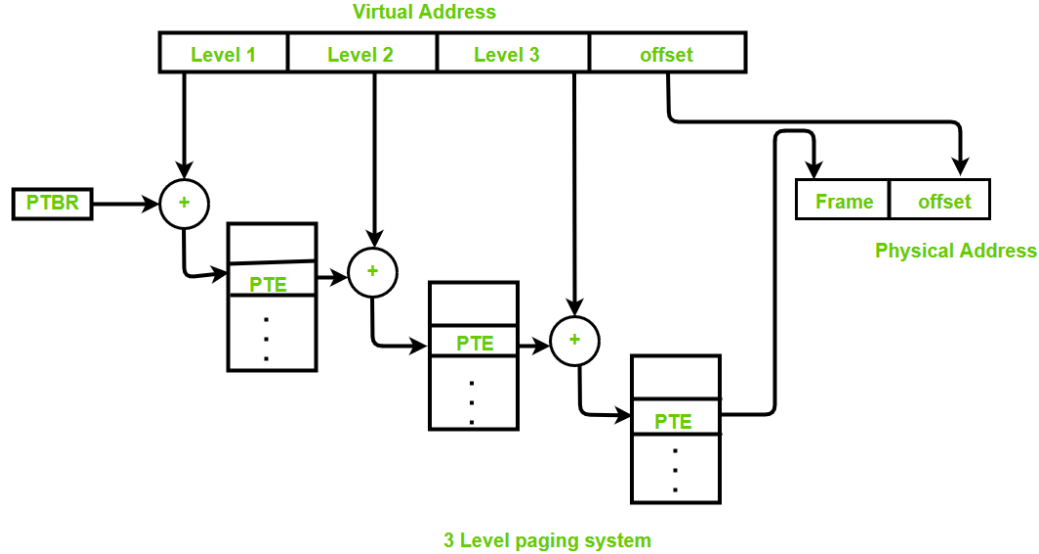
- 39 位寻址:虚拟地址划分为 \(9+9+9+12\) 位,对应三级页表结构
- 48 位寻址:虚拟地址划分为 \(9+9+9+9+12\) 位,对应四级页表结构
11 Segmentation vs Paging¶
Why was Segmentation implemented earlier than Paging?
- 硬件复杂度更低
- OS 需要承担的管理复杂度较小
- 更贴近程序的逻辑结构,比较直观
但随着地址空间增大、多道程序并发加强、外部碎片问题越来越突出,paging 在通用系统中逐渐成为更主流的底层内存管理机制。
| 对比项 | Segmentation | Paging |
|---|---|---|
| 划分依据 | 按逻辑模块划分 | 按固定大小划分 |
| 地址形式 | ⟨segment, offset⟩ |
⟨page, offset⟩ |
| 用户可见性 | 较强,段通常有语义 | 较弱,页主要服务实现 |
| 碎片问题 | 易有 external fragmentation | 无 external fragmentation,但有 internal fragmentation |
| 保护 / 共享 | 适合按逻辑模块控制 | 适合按固定粒度统一管理 |
In 32-bit architecture, for 1-level page table, how large is the whole page table?(32-bit VA + 4 KB page + 4-byte PTE)
页面大小为 \(4\ \text{KB} = 4 \times 1024 = 2^{12} \, \text{bytes}\),因此一共有 \(2^{32} \div 2^{12} = 2^{20}\) 个页表项,每个页表项(PTE)占 \(4\) 字节,因此整张页表的总大小为 \(2^{20} \times 4 = 4 \, \text{MB}\)。
In 32-bit architecture, for 2-level page table, how large is the whole page table? How large for the 1st level PGT? How large for the 2nd level PGT?
\(10+10+12\),第一级页表的大小和第二级页表的大小均为 \(2^{10} \times 4 \, \text{bytes} = 4 \, \text{KB}\)。
Page table base register holds 0x0061 9000, Virtual address is 0xf201 5202?
- VA \(= 0xf201 5202 = 1111 0010 00 | 00 0001 0101 | 0010 0000 0010\)
- 页内偏移 Offset(低 12 位)\(= 0x202\)
- 一级页号(高 10 位)\(p_1 = 0x3C8\)
- 二级页号(中 10 位)\(p_2 = 0x15\)
- 一级 PTE 地址 \(= \text{PTBR} + p_1 × 4 = 0x00619F20\)
- 从物理地址
0x00619F20读取 \(4\) 字节,得到二级页表的物理页号 PFN1,二级页表的起始物理地址为 \(\text{PFN1} << 12\)(一页 4KB,页起始地址低 12 位全为 0) - 二级 PTE 地址 \(= (\text{PFN1} << 12) + p_2 \times 4 = (\text{PFN1} << 12) + 0x54\)
- 从二级 PTE 地址读取 \(4\) 字节,得到的就是最终数据页的物理页号 PFN2
- PFN2 左移 12 位得到页起始地址,加上页内偏移就是最终的物理地址 \(\text{PA} = \text{PFN2} << 12 + 0x202\)
Page table base register holds 0x1051 4000, Virtual address is 0x2190 7010
- VA \(= 0x2190 7010 = 0010 0001 10 | 01 0000 0111 | 0000 0001 0000\)
- 页内偏移 Offset(低 12 位)\(= 0x10\)
- 一级页号(高 10 位)\(p_1 = 0x86\)
- 二级页号(中 10 位)\(p_2 = 0x107\)
- 一级 PTE 地址 \(= \text{PTBR} + p_1 × 4 = 0x10514218\),读取二级页表的物理页号 PFN1
- 二级 PTE 地址 \(= (\text{PFN1} << 12) + p_2 \times 4 = (\text{PFN1} << 12) + 0x41C\),读取最终数据页的物理页号 PFN2
- 物理地址 \(\text{PA} = \text{PFN2} << 12 + 0x10\)
常见虚拟地址格式
- 32-bit + 4 KB page:\(20 + 12\)
- 32-bit + 64 KB page:\(16 + 16\)
- 39-bit + 4 KB page:\(9 + 9 + 9 + 12\)
- 48-bit + 4 KB page:\(9 + 9 + 9 + 9 + 12\)
How about page size is 64KB? What is the virtual address format for 32-bit? What is the virtual address format for 64-bit?
若 page size \(= 64 \, \text{KB} = 2^{16}\),PTE \(= 8 \, \text{bytes}\),
则一个页表页可容纳:\(2^{16} / 2^3 = 2^{13}\) 个表项,因此每一级通常可索引 13 bits
常见结果可写成:
- 39-bit VA:\(10 + 13 + 16\)
- 48-bit VA:\(6 + 13 + 13 + 16\)
其中最高层索引位数不一定与中间层相同,本质上只是把剩余虚页号位数分配给若干级页表索引。