Chapter 5 Advanced SQL¶
1 Accessing SQL from a Programming Language¶
数据库应用通常不会只停留在交互式 SQL 界面,而是要由 C / Java / C# 等宿主语言(host language) 调用数据库,完成参数传递、结果处理、事务控制与异常处理。
1. 1 Embedded SQL¶
嵌入式 SQL(Embedded SQL)
SQL 标准允许将 SQL 嵌入到宿主语言中,例如 C、Java、Cobol 等。
被嵌入 SQL 的语言称为 宿主语言(host language),宿主语言中允许出现的 SQL 结构统称为 嵌入式 SQL。
- 典型形式:
EXEC SQL <embedded SQL statement> END_EXEC - 嵌入式 SQL 的核心问题:
- 参数交换:宿主语言变量如何传入 SQL
- 结果返回:查询结果如何映射回程序变量
- 集合与标量的差异:SQL 返回的是关系,程序变量往往是单值
- 执行状态获取:如何判断语句成功、失败或“无更多结果”
- 编译方式:通常需先经过预处理器(preprocessor),再编译为宿主语言代码
1. 2 Cursors¶
当查询结果包含多行元组时,程序通常通过 游标(cursor) 逐行读取。
游标的基本流程
EXEC SQL declare c cursor for
select ID, name
from student
END_EXEC
EXEC SQL open c END_EXEC
EXEC SQL fetch c into :si, :sn END_EXEC
EXEC SQL close c END_EXEC
open c:执行查询,生成结果集fetch c into ...:每次提取一行结果,放入宿主语言变量,多次调用fetch可依次取得后续元组close c:释放保存查询结果的临时关系/游标资源- 若已无更多元组,SQL 通信区中的
SQLSTATE通常会被设为02000
学生学分筛选工具
void getStudentInfo()
{
int credit_amount; // 存储用户输入的学分阈值
char sId[16]; // 存储学生ID
char sName[16]; // 存储学生姓名
// 声明游标:查询总学分 > credit_amount 的学生 id 和 name
EXEC SQL declare c cursor for select id, name from student where tot_cred> :credit_amount END_EXEC;
printf("Please input the credit amount: ");
scanf("%d",&credit_amount); // 获取用户输入的学分阈值
EXEC SQL open c END_EXEC; // 打开游标,执行查询
while (1)
{
// 从游标结果集里读一行,存入 sId 和 sName
EXEC SQL fetch c into :sId, :sName END_EXEC;
// 如果 SQLSTATE 是 02000,说明没有更多数据了,跳出循环
if (!strcmp(SQLSTATE,"02000"))
break;
// 打印当前读取的学生信息
printf("%s %s\n",sId,sName);
}
EXEC SQL close c END_EXEC; // 关闭游标
}
通过游标更新当前元组
-- 声明游标为可更新类型
declare c cursor for
select *
from instructor
where dept_name = 'Music'
for update;
-- 更新 instructor 表,将游标 c 当前所指向教师的薪资增加 100
update instructor
set salary = salary + 100
where current of c;
- 适用于“先读取,再按复杂业务逻辑决定是否更新”的场景。
1. 3 API: ODBC / ADO.NET / JDBC¶
数据库编程接口(API)
API(Application Program Interface)用于让应用程序与数据库服务器交互。典型流程是:
- 建立连接
- 发送 SQL 命令
- 逐行提取结果元组
- 关闭语句对象和连接
1. 3. 1 ODBC¶
ODBC(Open Database Connectivity) 是面向 C / C++ / C# / Visual Basic 的数据库访问接口。
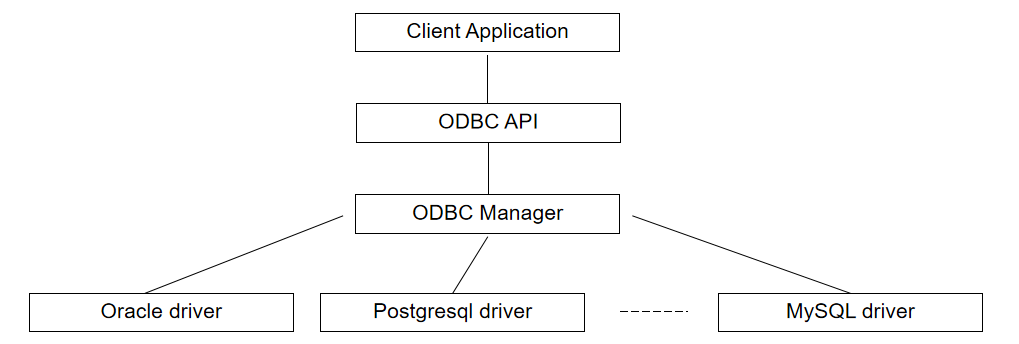
建立连接前,往往需要先完成 Driver 与 DSN(Data Source Name) 配置。
Driver and DSN Configuration
[PostgreSQL]
Description=PostgreSQL driver for Mac
Driver=/usr/local/Cellar/psqlodbc/12.01.0000/lib/psqlodbcw.so
Setup=/usr/local/Cellar/psqlodbc/12.01.0000/lib/psqlodbcw.so
[Mike] // Data Source Name(数据源名称,应用程序通过此名称连接)
Description=Mike
Driver=PostgreSQL
Database=mike
Servername=localhost
UserName=mike
Password=
Port=5432
ODBC 编程通常围绕环境句柄(HENV)、连接句柄(HDBC)、语句句柄(HSTMT)三类句柄展开。
ODBC 程序会先分配一个 SQL 环境(SQL environment),再分配一个数据库连接句柄(database connection handle),通过 SQLConnect() 函数建立数据库连接。
注:SQL_NTS 标记表示前一个参数是一个以 null 结尾的字符串(即 C 语言风格的字符串,以 \0 结束)。
ODBC 连接示例
int ODBCexample() {
RETCODE error;
HENV env;
HDBC conn;
SQLAllocEnv(&env);
SQLAllocConnect(env, &conn);
SQLConnect(conn,
(SQLCHAR *)"Mike", SQL_NTS,
(SQLCHAR *)"avi", SQL_NTS,
(SQLCHAR *)"avipasswd", SQL_NTS);
/* 执行查询或更新,通常需要再分配一个 statement handle */
SQLDisconnect(conn); // 断开连接
SQLFreeConnect(conn); // 释放连接句柄
SQLFreeEnv(env); // 释放环境句柄
}
成功建立数据库连接后,程序会先分配一个语句句柄(statement handle),再通过 SQLExecDirect 或 SQLExecute 函数向数据库发送 SQL 命令,常见函数包括:
SQLAllocStmt():分配语句句柄SQLExecDirect():直接执行 SQL 字符串SQLFetch():把游标推进到结果集的下一行SQLGetData():读取当前行指定列的值
More ODBC Features
- 元数据特性(Metadata features)
- 查找数据库中的所有关系(表)
- 查找查询结果或数据库中某一关系(表)的列名与列类型
- 事务管理(Transaction Management)
- 默认情况下,每条 SQL 语句都被视为一个独立的事务,会自动提交(auto-commit)
- 可以调用函数
SQLSetConnectOption(conn, SQL_AUTOCOMMIT, 0)在一个数据库连接上关闭自动提交 - 关闭自动提交后,事务必须显式提交或回滚:
- 提交事务:
SQLTransact(conn, SQL_COMMIT) - 回滚事务:
SQLTransact(conn, SQL_ROLLBACK)
- 提交事务:
1. 3. 2 ADO.NET¶
ADO.NET 是面向 Visual Basic .NET / C# 的数据库访问接口,提供了与 JDBC / ODBC 类似的能力。
ADO.NET 示例
using System;
using System.Data;
using System.Data.SqlClient;
SqlConnection conn = new SqlConnection(
"Data Source=<IPaddr>; Initial Catalog=<Catalog>");
conn.Open();
SqlCommand cmd = new SqlCommand(
"select * from students", conn);
SqlDataReader rdr = cmd.ExecuteReader();
while (rdr.Read()) {
Console.WriteLine(rdr[0], rdr[1]);
}
rdr.Close();
conn.Close();
- 典型对象包括:
SqlConnection、SqlCommand、SqlDataReader ExecuteReader()返回结果读取器,Read()用于逐行移动游标- 除关系数据库外,ADO.NET 还可访问 OLE-DB、XML 数据 等非关系型数据源
- 在 .NET 生态中也常与 Entity Framework 等更高层框架配合使用
1. 3. 3 JDBC¶
JDBC(Java Database Connectivity) 是 Java 访问支持 SQL 的数据库系统的标准 API。
- 支持 查询(query)、更新(update)、结果获取(result retrieval)
- 支持 元数据(metadata) 获取,如数据库中有哪些关系、各属性名称与类型等
- 典型通信模型为:
- 打开连接
- 创建
Statement对象 - 通过
Statement执行查询并获取结果 - 使用异常机制处理错误
JDBC 基本结构
public static void JDBCexample(String userid, String passwd) {
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
Connection conn = DriverManager.getConnection(
"jdbc:oracle:thin:@db.yale.edu:2000:univdb",
userid, passwd);
Statement stmt = conn.createStatement();
// Do actual work
stmt.close();
conn.close();
} catch (SQLException sqle) {
System.out.println("SQLException: " + sqle);
}
}
JDBC 执行更新与查询
try {
stmt.executeUpdate(
"insert into instructor values ('77987', 'Kim', 'Physics', 98000)");
} catch (SQLException sqle) {
System.out.println("Could not insert tuple. " + sqle);
}
ResultSet rset = stmt.executeQuery(
"select dept_name, avg(salary) " +
"from instructor group by dept_name");
while (rset.next()) {
System.out.println(
rset.getString("dept_name") + " " + rset.getFloat(2));
}
executeUpdate()常用于insert / update / deleteexecuteQuery()返回ResultSet- JDBC 中可通过
rset.getString("dept_name")或rset.getString(1)读取列值 - 若列值可能为
null,可先读取,再调用wasNull()判断
JDBC 处理 null 值
int a = rs.getInt("salary");
if (rs.wasNull()) {
System.out.println("Got null value");
}
JDBC 元数据(Metadata)
DatabaseMetaData dmd = connection.getMetaData();
ResultSet rs = dmd.getPrimaryKeys(null, null, tableName);
while (rs.next()) {
System.out.println(
rs.getString("KEY_SEQ") + " " +
rs.getString("COLUMN_NAME"));
}
getMetaData()可用来读取主键、表结构、属性类型等信息getPrimaryKeys(catalog, schema, tableName)中:- 传入空值/当前上下文时,可表示当前 catalog / schema
null也常用于表示“匹配所有 catalog / schema”
KEY_SEQ表示该属性在复合主键中的位置次序
Metadata Features 查询的不是业务数据,而是数据库自身的结构信息,因而常被用于:
- 自动读取表结构
- 判断主键/外键组成
- 支持数据库管理工具、代码生成器、ORM 等程序动态适配数据库模式
JDBC 默认采用自动提交(auto-commit),每条 SQL 语句执行成功后都会立即提交,每条语句本身就构成一个独立事务,可以改为手动控制事务边界。
JDBC 手动提交/回滚
// 关闭自动提交
conn.setAutoCommit(false);
// 若希望恢复默认行为,可再调用 setAutoCommit(true)
// executeUpdate(...)
// executeUpdate(...)
conn.commit(); // 把当前事务中的更新永久写入数据库
// 或者在异常处理中:
conn.rollback(); // 撤销当前事务中尚未提交的更新
JDBC 可以通过 CallableStatement 调用数据库中的函数(function)和过程(procedure)。
CallableStatement 的典型形式
// 调用的是函,通常要为返回值预留一个参数位置
CallableStatement cStmt1 =
conn.prepareCall("{? = call some_function(?)}");
// 调用的是过程,只需要传入过程参数
CallableStatement cStmt2 =
conn.prepareCall("{call some_procedure(?, ?)}");
JDBC 还支持对大对象类型进行读取与更新,如二进制大对象(Blob)和字符大对象(Clob)。
- 读取时,可通过类似
getBlob()、getClob()的接口获得对象 - 取得
Blob / Clob后,还可继续读取其内部内容,例如通过getBytes()等方式提取数据 - 更新时,JDBC 也支持把输入流与大对象参数或列关联起来,例如通过
blob.setBlob(int parameterIndex, InputStream inputStream)将输入流关联到指定参数位置,实现对 Blob 类型数据的更新
SQLJ 的基本思想
JDBC 更偏向动态 SQL:程序在运行时构造 SQL 字符串,再通过 API 执行,编译器无法捕获其中的错误
SQLJ 则更接近在 Java 中嵌入 SQL,允许把 SQL 直接写进 Java 程序中,再通过预处理/编译机制与 Java 代码结合。
SQLJ 迭代器示例
// 定义迭代器类型,用于承载查询结果(部门名称、平均薪资)
#sql iterator DeptInfoIter(String dept_name, float avg_salary);
DeptInfoIter iter;
// 把 SQL 查询直接嵌入 Java 代码
#sql iter = {
select dept_name, avg(salary)
from instructor
group by dept_name
};
// 遍历查询结果
while (iter.next()) {
System.out.println(iter.dept_name() + " " + iter.avg_salary());
}
iter.close();
1. 4 Prepared Statements and SQL Injection¶
如果程序通过字符串拼接构造 SQL,用户可能把输入变成恶意 SQL 片段,造成 SQL 注入(SQL injection)。
危险写法
gets(sCreditAmount); // dangerous
strcpy(sqlquery, "select id, name, tot_cred from student where tot_cred > ");
strcat(sqlquery, sCreditAmount); // dangerous
如果用户输入恶意内容 3; update student set tot_cred=200 where ID = '19001',最终执行的 SQL 会变成:
select id, name, tot_cred from student where tot_cred> 3;
update student set tot_cred=200 where ID = '19001'
使用带占位符的 SQL 模板,再将用户输入绑定到参数位置,可以避免注入风险,并支持重复执行。
ODBC 中的预编译语句
// 传入语句句柄和带占位符的 SQL 字符串,完成语句预编译
SQLPrepare(stmt, (SQLCHAR *)"insert into account values(?,?,?)", SQL_NTS);
// 绑定参数
SQLBindParameter(stmt, 1, ...);
SQLBindParameter(stmt, 2, ...);
SQLBindParameter(stmt, 3, ...);
// 执行
SQLExecute(stmt);
用 ODBC 预处理语句实现的安全版学生信息查询函数
int getStudentInfo(HDBC conn)
{
// 业务变量
int creditAmount; // 用户输入的学分阈值
char sId[24]; // 存储学生ID
char sName[24]; // 存储学生姓名
int totalCredit; // 存储学生总学分
// ODBC 变量
SQLLEN lenOut1, lenOut2, lenOut3; // 存储结果列的实际长度
HSTMT stmt; // 语句句柄
RETCODE error; // 函数执行返回码
// 带占位符的 SQL 查询语句
char* sqlquery = "select id, name, tot_cred from student where tot_cred> ? ";
// 1. 获取用户输入
printf("Please input the credit amount: ");
scanf("%d", &creditAmount);
// 2. 分配语句句柄
SQLAllocStmt(conn, &stmt);
// 3. 预处理 SQL(编译带占位符的语句,不包含用户输入)
SQLPrepare(stmt, (SQLCHAR*)sqlquery, SQL_NTS);
// 4. 绑定参数:将占位符 ? 与 C 变量 creditAmount 绑定
SQLBindParameter(
stmt, // 语句句柄
1, // 参数序号(第1个占位符)
SQL_PARAM_INPUT, // 参数方向:输入
SQL_C_SLONG, // C 语言数据类型(长整型)
SQL_INTEGER, // SQL 数据类型(整数)
0, 0, // 精度、小数位数(此处用默认值)
(SQLPOINTER)&creditAmount, // 绑定的变量地址
sizeof(int), // 变量长度
NULL // 长度指示器(无)
);
// 5. 执行预处理语句
error = SQLExecute(stmt);
// ......(后续省略:绑定结果列、循环读取数据、释放资源)
}
JDBC 中的预编译语句
PreparedStatement pStmt = conn.prepareStatement(
"insert into instructor values (?, ?, ?, ?)");
pStmt.setString(1, "88877");
pStmt.setString(2, "Perry");
pStmt.setString(3, "Finance");
pStmt.setInt(4, 125000);
pStmt.executeUpdate();
pStmt.setString(1, "88878");
pStmt.executeUpdate();
- 对查询,使用
pStmt.executeQuery(),返回ResultSet - 对更新,使用
pStmt.executeUpdate() - 结论:凡是把用户输入带入 SQL,都应优先使用
PreparedStatement / SQLPrepare
字符串条件中的 SQL 注入
假设程序这样拼接查询条件:
"select * from instructor where name = '" + name + "'"
如果用户输入:
X' or 'Y' = 'Y
那么拼接后的条件会变成一个恒真谓词,从而返回超出预期的数据。若用户继续注入 ; update ... -- 一类片段,还可能把“查询”变成“查询 + 更新”。
预编译语句会把输入当作参数值处理,而不是 SQL 语法的一部分,因此即使输入中包含引号、分号或关键字,也不会改变原查询的语法结构。
2 Functions and Procedures¶
SQL:1999 起支持在数据库内部定义 函数(function) 和 过程(procedure),把常用逻辑封装到数据库侧执行。
2. 1 SQL Functions¶
函数可以返回单个值,也可以返回表(table-valued function),SQL:2003 明确加入了返回关系的函数支持。
返回单个值的函数
-- 定义一个函数:接收院系名称作为参数,返回该院系的教师人数
create function dept_count(dept_name varchar(20))
returns integer
begin
declare d_count integer;
select count(*)
into d_count
from instructor
where instructor.dept_name = dept_count.dept_name;
return d_count;
end
-- 查询教师人数超过 12 人的所有院系的名称和预算
select dept_name, budget
from department
where dept_count(dept_name) > 12;
返回一个关系的函数
-- 返回某一院系的所有教师
create function instructors_of(dept_name char(20))
returns table (
-- 声明返回值为表结构,包含字段:ID、姓名、院系、薪资
ID varchar(5),
name varchar(20),
dept_name varchar(20),
salary numeric(8,2)
)
return table
(
-- 从教师表中查询出与参数指定院系匹配的所有教师数据
select ID, name, dept_name, salary
from instructor
where instructor.dept_name = instructors_of.dept_name
);
-- 调用表函数,查询音乐系(Music)的所有教师信息
select *
from table(instructors_of('Music'));
2. 2 SQL Procedures¶
过程与函数类似,但通常更强调执行动作,可通过 in / out / inout 参数与外部交换数据。
示例
-- 创建存储过程 dept_count_proc
create procedure dept_count_proc(
in dept_name varchar(20),
out d_count integer
)
begin
select count(*)
into d_count
from instructor
where instructor.dept_name = dept_count_proc.dept_name;
end
-- 声明变量接收输出结果
declare d_count integer;
-- 调用存储过程,传入院系名称 Physics,并将结果存入 d_count
call dept_count_proc('Physics', d_count);
- 过程既可以从另一个 SQL 过程内部调用,也可以通过
call由嵌入式 SQL 调用 - 许多系统也支持在动态 SQL 环境中调用过程或函数
- SQL:1999 允许同名重载(name overloading),只要参数个数不同或类型不同,就可定义多个同名函数/过程
PostgreSQL 风格的过程示例
-- 创建或替换存储过程 findNumOfStudent
CREATE OR REPLACE PROCEDURE findNumOfStudent(
creditAmount in INT, -- 输入参数:指定学分阈值
numOfStudent inout INT -- 输入输出参数:存储符合条件的学生数量
)
LANGUAGE plpgsql -- 指定使用 PL/pgSQL 过程化语言
AS $$
BEGIN
-- 统计 student 表中总学分大于阈值的学生总数,结果存入 numOfStudent
SELECT count(*) INTO numOfStudent
FROM student
WHERE tot_cred > creditAmount;
END;
$$;
-- 创建或替换存储过程 callExample
CREATE OR REPLACE PROCEDURE callExample(cAmount in INT)
LANGUAGE plpgsql
AS $$
DECLARE
noStudent INT := 0; -- 声明变量并初始化,用于接收统计结果
BEGIN
-- 调用 findNumOfStudent,传入阈值 cAmount,结果存入 noStudent
CALL findNumOfStudent(cAmount, noStudent);
-- 向客户端输出通知信息(相当于打印结果到屏幕)
RAISE NOTICE '%', noStudent; -- //output to screen
END;
$$;
2. 3 Flow Control in SQL Procedures¶
不同数据库实现差异很大
标准 SQL 给出了过程化扩展语法,但实际数据库往往采用各自的变体,写存储过程时,必须查阅当前 DBMS 的手册。
- 复合语句(compound statement):
begin ... end - 局部变量声明:
declare 变量名 类型 [default 初值] - 循环结构:
while、repeat、for - 条件结构:
if ... then ... else、case - 异常处理:
declare handler、signal
条件与异常控制补充
if ... then ... else常用于容量检查、业务规则分支等场景case语句适合表达多分支选择,风格类似通用编程语言中的switch- 可先
declare 条件名 condition,再通过signal主动触发异常 declare exit handler for ...表示异常发生后退出当前begin ... end复合语句
while / repeat 示例
declare n integer default 0;
while n < 10 do
set n = n + 1;
end while;
repeat
set n = n - 1;
until n = 0
end repeat;
for 循环遍历查询结果
declare n integer default 0;
for r as
select budget
from department
where dept_name = 'Music'
do
set n = n + r.budget;
end for;
自定义条件与退出处理器
declare out_of_classroom_seats condition;
declare exit handler for out_of_classroom_seats
begin
-- 记录失败信息 / 清理状态 / 返回错误码
end;
-- 当教室容量不足时
signal out_of_classroom_seats;
游标 + 循环的函数示意
-- 创建或替换函数 findStudentsWithAdvisor
CREATE OR REPLACE FUNCTION findStudentsWithAdvisor(credAmount Integer)
RETURNS Integer
LANGUAGE plpgsql
AS $$
DECLARE
num Integer DEFAULT 0; -- 总计数器:符合条件的学生总数
numOfAdvisor Integer DEFAULT 0; -- 临时计数器:单个学生的导师数量
sId char(12) DEFAULT ''; -- 临时变量:存储当前遍历的学生 ID
-- 声明游标:查询总学分大于指定值的学生 ID
curStudent CURSOR (cAmount Integer)
FOR SELECT ID
FROM student
WHERE tot_cred > cAmount;
BEGIN
-- 打开游标,传入参数 credAmount
OPEN curStudent(credAmount);
-- 开始循环遍历游标
LOOP
-- 提取当前行数据到变量 sId
FETCH curStudent INTO sId;
-- 退出条件:未获取到数据(游标遍历完毕)
EXIT WHEN NOT FOUND;
-- 业务逻辑:查询该学生是否有导师
SELECT count(*) INTO numOfAdvisor
FROM advisor
WHERE s_id = sId;
-- 如果有导师(计数器大于 0),则总计数器加 1
IF numOfAdvisor > 0 THEN
num := num + 1;
END IF;
END LOOP;
-- 关闭游标,释放资源
CLOSE curStudent;
-- 返回结果:总共有多少名学生满足条件
RETURN num;
END;
$$;
异常处理:转账过程
CREATE OR REPLACE PROCEDURE transfer_funds(
source_account_id INT,
destination_account_id INT,
amount DECIMAL
)
LANGUAGE plpgsql
AS $$
BEGIN
IF (SELECT balance
FROM accounts
WHERE id = source_account_id) < amount THEN
RAISE EXCEPTION 'Insufficient funds';
END IF;
UPDATE accounts
SET balance = balance - amount
WHERE id = source_account_id;
UPDATE accounts
SET balance = balance + amount
WHERE id = destination_account_id;
INSERT INTO transfers(
source_id, destination_id, amount, transaction_date)
VALUES (
source_account_id, destination_account_id,
amount, CURRENT_TIMESTAMP);
COMMIT;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
RAISE;
END;
$$;
2. 4 External Language Routines¶
SQL:1999 允许函数/过程用 C、C++ 等外部语言编写,再注册到数据库中。
示例
create procedure dept_count_proc(
in dept_name varchar(20),
out count integer
)
language C
external name '/usr/avi/bin/dept_count_proc';
create function dept_count(dept_name varchar(20))
returns integer
language C
external name '/usr/avi/bin/dept_count';
| 方面 | 优点 | 风险 |
|---|---|---|
| 外部语言例程 | 执行效率高、表达能力强 | 可能破坏数据库内部结构,带来安全问题 |
| 沙箱 / 独立进程执行 | 更安全 | 进程隔离和通信会带来性能开销 |
- 常见安全措施:
- 使用 Java 等更安全的语言
- 在独立进程中运行外部函数/过程,通过进程间通信与数据库交互
- 必要时才允许例程在数据库进程地址空间中直接执行
3 Triggers¶
触发器(Trigger)是在特定数据库事件发生时自动执行的语句集合,可用于实现审计、派生属性维护、额外约束检查等逻辑。
Trigger Example
time_slot_id 并非 timeslot(时间段)表的主键,因此我们无法从 section(课程段)表到 timeslot 表创建外键约束。作为替代方案,可以在 section 表和 timeslot 表上使用触发器来强制实施完整性约束。
create trigger timeslot_check1 after insert on section
referencing new row as nrow
for each row
when (nrow.time_slot_id not in (
select time_slot_id
from time_slot))
begin
rollback
end;
create trigger timeslot_check2 after delete on timeslot
referencing old row as orow
for each row
when (orow.time_slot_id not in (
select time_slot_id
from time_slot)
/* last tuple for time slot id deleted from time slot */
and orow.time_slot_id in (
select time_slot_id
from section)) /* and time_slot_id still referenced from section*/
begin
rollback
end;
- 触发事件(triggering event)可以是:
insert、delete、update - 对
update触发器,可限制只在某些属性更新时触发,触发时间可为before(事件执行前)或after(事件执行后) - 可以引用更新操作前后的属性值:
referencing old row as:用于删除和更新操作,引用更新 / 删除前的旧行数据referencing new row as:用于插入和更新操作,引用插入 / 更新后的新行数据
- 触发器可以在事件发生前激活,以此作为额外的约束
将空白成绩改写为 null
create trigger setnull_trigger
before update of grade on takes
referencing new row as nrow
for each row
when (nrow.grade = ' ')
begin atomic
set nrow.grade = null;
end;
学生获得成绩后,自动累计学分
create trigger credits_earned
after update of grade on takes
referencing new row as nrow
referencing old row as orow
for each row
when (
nrow.grade <> 'F'
and nrow.grade is not null
and (orow.grade = 'F' or orow.grade is null)
)
begin atomic
update student
set tot_cred = tot_cred +
(select credits
from course
where course.course_id = nrow.course_id)
where student.id = nrow.id;
end;
- 该触发器体现的是派生数据维护
- 只有当学生从“未通过/未录入成绩”变为“通过”时,才应累计学分
- 语句级触发器(Statement Level Triggers)
- 对一个事务中所有受影响的行仅执行一次统一的动作
- 使用
for each statement替代for each row - 使用
referencing old table或referencing new table来引用临时表,这些表称为过渡表(transition tables),包含了所有受影响的行数据 - 在处理批量更新大量行的 SQL 语句时,语句级触发器的执行效率更高
触发器的可能风险
- 从备份副本加载数据时或在远程站点同步复制更新时,存在意外执行风险,执行此类操作前可先禁用触发器
- 触发器内部错误会导致触发它的关键事务失败
- 存在 级联执行(cascading execution) 风险(一个触发器触发另一个触发器,引发连锁反应)
4 Recursive Queries¶
SQL:1999 允许递归视图/递归公共表达式,用于表达传递闭包(transitive closure)、组织结构层级、先修课链等递归关系。
查询某课程的直接或间接先修课
-- 定义递归视图 rec_prereq,包含字段 course_id(课程 ID)、prereq_id(先修课 ID)
with recursive rec_prereq(course_id, prereq_id) as (
-- 锚点成员:查询直接先修课程
select course_id, prereq_id
from prereq
union
-- 递归成员:递归查询间接先修课程
select rec_prereq.course_id, prereq.prereq_id
from rec_prereq, prereq
where rec_prereq.prereq_id = prereq.course_id
)
-- 查询递归视图结果
select *
from rec_prereq;
若不使用递归或迭代,传递闭包查询无法实现
- 若不使用递归,非递归、非迭代的程序仅能对
prereq(先修课关系)执行固定次数的自连接操作,仅能查询固定层级的先修课 / 管理层级。 - 替代方案:编写存储过程,按需求迭代执行任意次数。
- 迭代过程的每一步,都会根据递归定义构建
rec_prereq的扩展版本,最终结果被称为递归视图定义的不动点(fixed point) - 递归视图要求是单调(monotonic)的,即如果向
prereq表中添加新元组,rec_prereq视图会保留之前所有的元组,并在此基础上可能新增更多元组(不会删除或修改已有元组)
5 Advanced Aggregation Features¶
高级 SQL 不仅能做事务处理,还能支持分析型查询,如排名、滑动窗口统计、运行总计、多维聚合等。
5. 1 Ranking¶
- 需要结合
order by子句来指定排序规则。
按院系给学生 GPA 排名
select ID, dept_name,
rank() over (
partition by dept_name
order by GPA desc
) as dept_rank
from dept_grades
order by dept_name, dept_rank;
rank()排名可能会产生间隙,例如:若 2 名学生 GPA 并列第一,两人排名均为 1,下一名学生的排名会直接跳到 3dense_rank()则不会产生间隙,因此下一名学生的密集排名会是 2
- 排名可以通过基础的 SQL 聚合操作实现,但生成的查询效率极低。
示例
-- 对每个学生 A,统计 GPA 比 A 高的学生数量,加 1 后作为 A 的排名
select ID, (1 + (select count(*)
from student_grades B
where B.GPA > A.GPA)) as s_rank
from student_grades A
order by s_rank;
- 可以在数据分区(partition)内完成排名。
查询每个系内部学生的排名
select ID, dept_name,
rank() over (partition by dept_name order by GPA desc) as dept_rank
from dept_grades
order by dept_name, dept_rank;
- 单个
select子句中可包含多个排名函数 - 排名计算发生在
group by/ 聚合操作完成之后 - 可用于查找 Top-N 结果,相比很多数据库提供的
limit n子句更通用,因为它支持每个分区内部取 Top-N
其他排名函数
percent_rank():(若使用分区,则在分区内)计算百分比排cume_dist():累积分布,求值小于等于当前行值的元组在分区中所占的比例row_number():行号函数,在存在重复值时,行号分配具有非确定性(即重复值的行号顺序不固定)ntile(n):分桶函数,将有序数据集划分为 n 个数量尽可能均等的组,每组分配一个从 1 到 n 的桶号。
- SQL:1999 标准允许用户指定空值(NULL)的排序位置
nulls first:空值排在最前nulls last:空值排在最后
示例
select ID,
rank() over (order by GPA desc nulls last) as s_rank
from student_grades
select ID, ntile(4) over (order by GPA desc) as quartile
from student_grades;
5. 2 Windowing¶
窗口函数用于在不丢失明细行的前提下,对当前行附近的一组行做聚合计算。
示例
select date, sum(value) over (
order by date rows between 1 preceding and 1 following
) as local_sum
from sales;
若改为 avg(value) over (...),就得到了三天移动平均。
其他窗口规范示例
between rows unbounded preceding and current:从分区的第一行(无界前置)到当前行,常用于计算累计聚合(如累计求和、累计计数),可简写为rows unbounded precedingrange between 10 preceding and current row:按值域而非行数定义窗口,包含所有排序字段值在「当前行值 - 10」到当前行值之间的行range interval 10 day preceding:按时间区间定义窗口,包含当前行日期之前 10 天内的所有行,不包含当前行
rows是按物理行数取窗口,range是按排序键的取值范围取窗口- 某些窗口定义还可以显式不包含当前行,具体取决于
between ... and ...的边界写法
账户余额的运行总计
设关系为 transaction(account_number, date_time, value),其中存款为正、取款为负:
select account_number, date_time,
sum(value) over (
partition by account_number
order by date_time
rows unbounded preceding
) as balance
from transaction
order by account_number, date_time;
5. 3 Cube Aggregation¶
联机分析处理(OLAP, Online Analytical Processing)
- 对数据进行交互式分析,支持以在线方式(延迟可忽略不计)对数据进行汇总,并从不同视角查看数据。
- 可被建模为维度属性和度量属性的数据,称为多维数据。
- 度量属性(Measure attributes):用于度量某个数值,可对其进行聚合计算(如求和、平均值等),例如销售关系表中的
number属性(代表销售数量等可聚合指标) - 维度属性(Dimension attributes):定义查看度量属性(或其聚合结果)的分析维度,例如销售关系表中的
item_name(商品名)、color(颜色)和size(尺寸)属性
交叉表(cross-tabulation, cross-tab)/ 透视表(pivot-table)
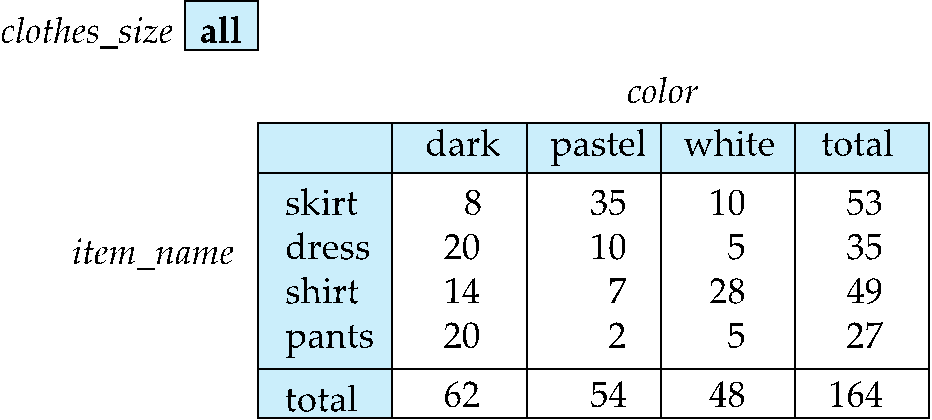
- 一个维度属性的取值构成行表头(
item_name) - 另一个维度属性的取值构成列表头(
color) - 其他维度属性列在表格顶部(
clothes_size,取值为all,代表统计全部尺码的销售数据) - 单元格中的值是该单元格对应维度组合下度量值的聚合结果(各商品名称 + 颜色组合的销售总量)
数据立方体(Data Cube)
- 数据立方体是交叉表(cross-tab)的多维泛化形式,可以包含 n 个维度
- 交叉表可以作为数据立方体的视图来使用(即从多维立方体中切出一个二维平面进行展示)
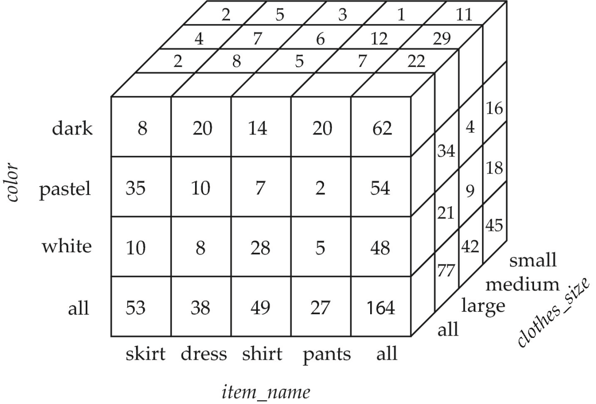
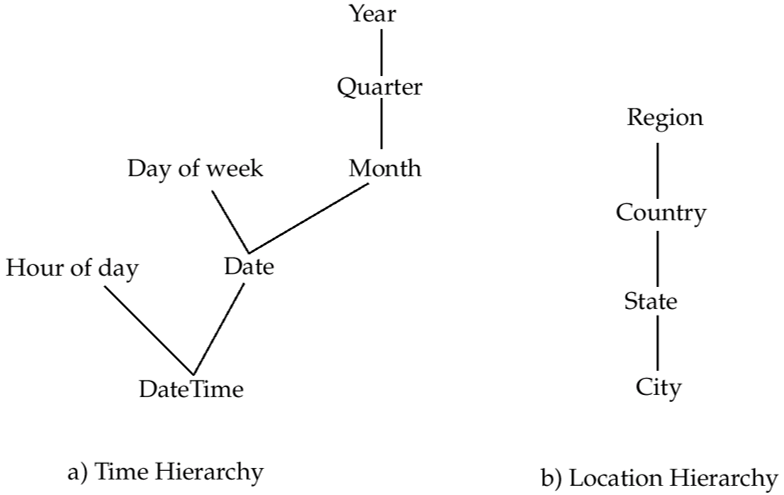
- 维度上的层次结构(Hierarchies on Dimensions):允许在不同细节层级下查看和分析维度数据,例如
DateTime维度可以按小时、日期、星期、月份、季度或年份等不同粒度进行聚合计算。
- 交叉表可以很容易地扩展,以处理维度层次结构,可以在层次结构上执行 下钻(Drill-down)或上卷(Roll-up) 操作。
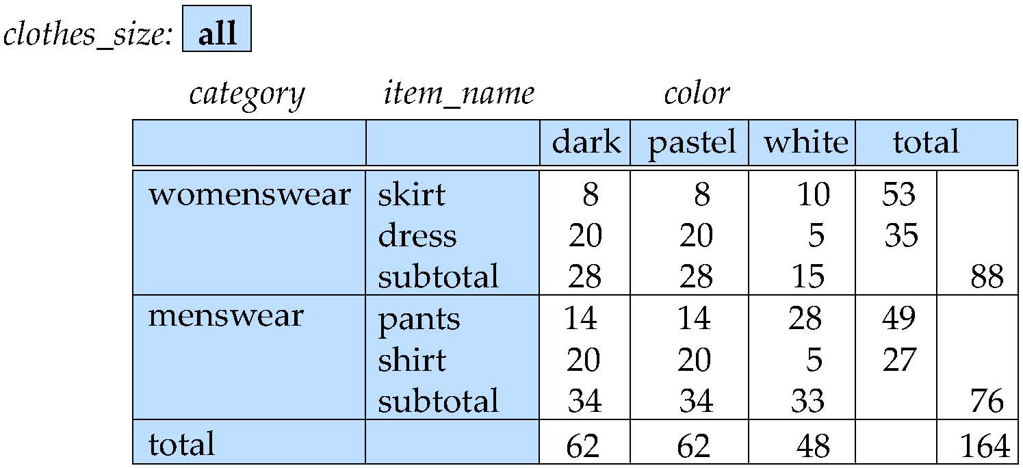
- 交叉表可以用 关系(表) 的形式来表示,我们使用值 all 来表示聚合(汇总)结果,SQL 标准实际上用 NULL 值替代 all,尽管这会和普通的空值(代表数据缺失)产生混淆。
cube 会对指定属性集合的每个子集都做一次 group by,适合多维分析(OLAP)。
对商品销售做多维汇总
设关系为 sales(item_name, color, clothes_size, quantity):
select item_name, color, clothes_size, sum(quantity)
from sales
group by cube(item_name, color, clothes_size);
该语句等价于对如下 8 种分组求并:
(item_name, color, clothes_size)(item_name, color)(item_name, clothes_size)(color, clothes_size)(item_name)(color)(clothes_size)()
- 若某个维度未参与当前分组,对应属性值会显示为
null -
可结合
grouping()、decode()或 DBMS 提供的同类函数,把这些null替换为all -
grouping()函数可以作用于某个属性:- 若该属性的值是代表 “全部(all)” 的 NULL,则返回 1
- 其他所有情况(包括真实数据缺失的 NULL)返回 0
示例
select item_name, color, size, sum(number),
grouping(item_name) as item_name_flag,
grouping(color) as color_flag,
grouping(size) as size_flag
from sales
group by cube(item_name, color, size)
- 可以在
select子句中使用decode()函数,将这类代表 “全部(all)” 的NULL值替换为 all 这样的显式文本。
示例
decode(grouping(item_name), 1, 'all', item_name)
如果 grouping(item_name) 返回 1(代表该 NULL 是汇总标记),则显示为 all;否则显示原始的 item_name 业务值。
rollup:会生成指定属性列表的所有前缀分组结果的并集,可用于生成层次结构中多个层级的聚合结果。
示例
select item_name, color, size, sum(number)
from sales
group by rollup(item_name, color, size)
{ (item_name, color, size), (item_name, color), (item_name), () }
注:rollup 按属性顺序,从最细粒度逐步上卷,依次去掉最后一个属性,最终到空分组(全表总计)。
假设表 itemcategory(item_name, category) 存储了每个商品对应的类别,执行以下查询:
select category, item_name, sum(number)
from sales, itemcategory
where sales.item_name = itemcategory.item_name
group by rollup(category, item_name)
会得到按商品名称和类别分层的汇总结果(先按商品+类别汇总,再按类别汇总,最后全表总计)。
- 在单个
group by子句中可以使用多个rollup(上卷)和cube(立方体)结构,每个结构会生成一组group by分组列表,这些分组列表集合的笛卡尔积构成最终的完整group by分组列表集合。
示例
select item_name, color, size, sum(number)
from sales
group by rollup(item_name), rollup(color, size)
该语句会生成如下分组:
{item_name, ()} × {(color, size), (color), ()}
= { (item_name, color, size), (item_name, color), (item_name),
(color, size), (color), () }
注:() 代表空分组(即全表总计),笛卡尔积 × 表示将两个 rollup 各自生成的分组列表两两组合,得到所有可能的分组方式。
- OLAP 操作
- 透视(Pivoting):改变交叉表中所使用的维度。
例:把“商品名称”作为行、“颜色”作为列,切换为“颜色”作为行、“尺码”作为列,重新生成交叉表。
- 切片(Slicing):仅针对固定维度取值生成交叉表,当多个维度的取值被固定时,该操作有时也称为切块(Dicing)。
例:只看“尺码=全部、颜色=深色”的商品销售数据,生成对应的交叉表。
- 上卷(Rollup):从细粒度数据向粗粒度数据聚合(提升分析层级)。
例:从“每日销量”汇总到“每月销量”,再汇总到“每年销量”。
- 下钻(Drill down):上卷的逆操作——从粗粒度数据向细粒度数据钻取(展开查看更细节的数据)。
例:从“年度总销量”下钻到“季度销量”,再下钻到“每月销量”,最后到“每日销量”。
- 透视(Pivoting):改变交叉表中所使用的维度。
| 类型 | 存储方式 | 优点 | 缺点 |
|---|---|---|---|
| MOLAP | 内存多维数组 | 查询速度极快,适合多维分析 | 数据量较大时内存占用高 |
| ROLAP | 关系型数据库表 | 灵活、可扩展,适合大数据量 | 查询性能相对较慢 |
| HOLAP | 内存+关系库混合 | 兼顾性能与灵活性,是主流方案 | 架构相对复杂 |
OLAP 实现补充
- 若有 \(n\) 个分析维度,则
cube在理论上对应 \(2^n\) 种分组组合 - 早期 OLAP 系统常预先计算所有可能聚合,以换取在线查询响应速度,但这样做的空间与预处理时间代价都可能很高
- 实际系统通常只预计算部分聚合,其余聚合在查询时由更细粒度结果继续汇总得到
- 这种复用对
sum、count、avg等可分解聚合尤其有效 - 对
median等不易分解的聚合,直接复用已有聚合结果就不那么容易 - 多层级聚合常可借助一次排序联合计算,而不必对底层数据重复排序多次