Chapter 2 Instruction-Level Parallelism (ILP)¶
Data Hazards
FADD.D F6,F0,F12
FSUB.D F8,F6,F14
# Name dependence: anti-dependence(WAR)
FDIV.D F2, F6, F4
FADD.D F6, F0, F12
FDIV.D F2, F0, F4
FSUB.D F2, F6, F14
Code Scheduling 避免停顿
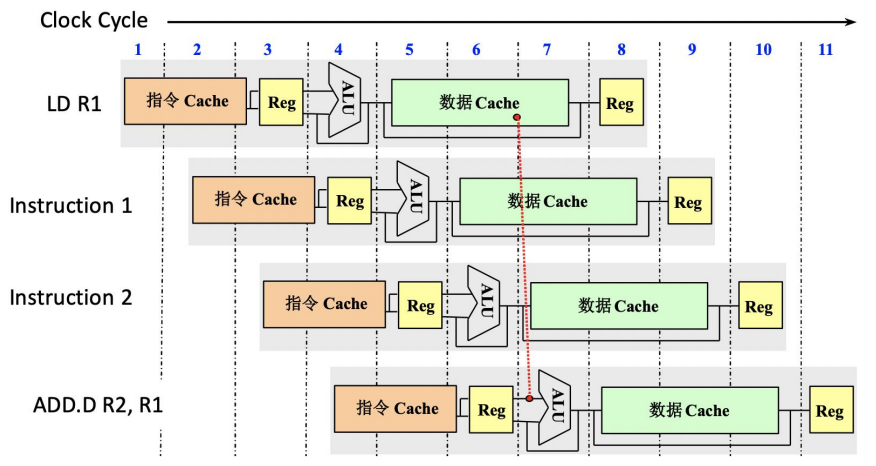
编译器/程序员可以把独立指令插入 load 和 use 之间,隐藏访存延迟。

1 Dynamic Scheduling¶
为什么需要动态调度
简单流水线采用按序发射、按序执行(in-order issue and execution),若某条指令停滞,后续所有指令都会被堵住,即使它们之间根本没有数据相关。
FDIV.D F4, F0, F2
FSUB.D F10, F4, F6
FADD.D F12, F6, F14
这里 FADD.D 与 FDIV.D 无关,但会因为 FSUB.D 等待 FDIV.D 而被迫停住。
乱序执行带来的新问题
五级按序整数流水线中主要处理 RAW,但在乱序执行下,WAW 和 WAR 会变成真正需要硬件处理的问题:
# WAW
FDIV.D F10, F0, F2
FSUB.D F10, F4, F6
# WAR
FADD.D F6, F8, F14
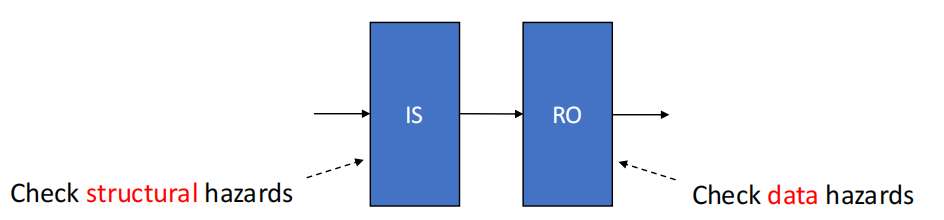
为了支持乱序,我们把 ID 阶段拆为两段:
- Issue (IS):译码并检查结构冒险,仍然按序发射
- Read Operands (RO):等待数据就绪后读取操作数,可乱序进入
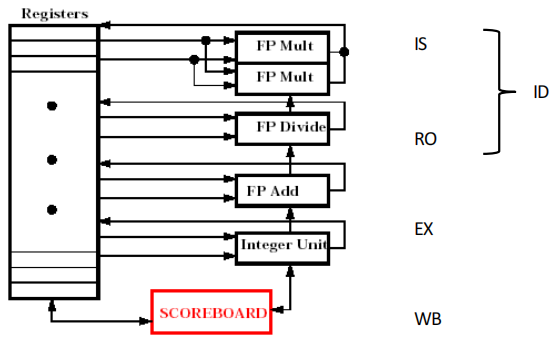
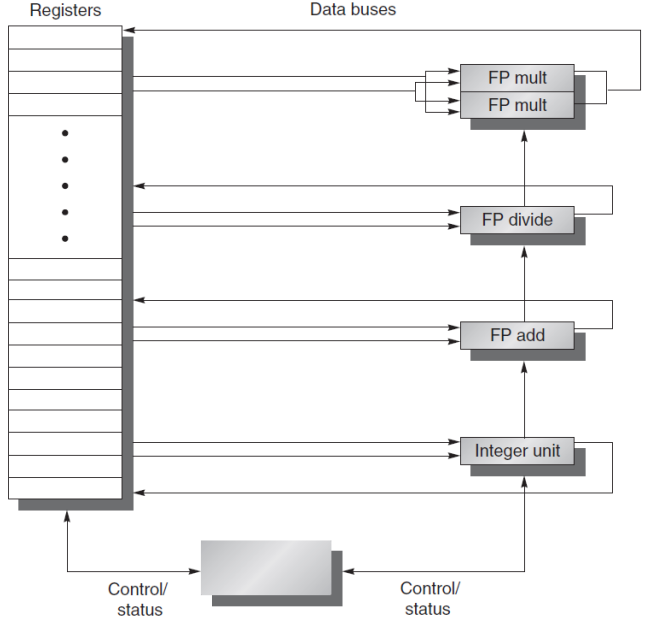
1. 1 Scoreboard Algorithm¶
Scoreboard 通过三张表跟踪指令、功能部件和寄存器的状态。
示例
FLD F6, 34(R2) // 加载浮点到 F6
FLD F2, 45(R3) // 加载浮点到 F2
FMUL.D F0, F2, F4 // F0 = F2 × F4
FSUB.D F8, F6, F2 // F8 = F6 − F2
FDIV.D F10, F0, F6 // F10 = F0 ÷ F6
FADD.D F6, F8, F2 // F6 = F8 + F2
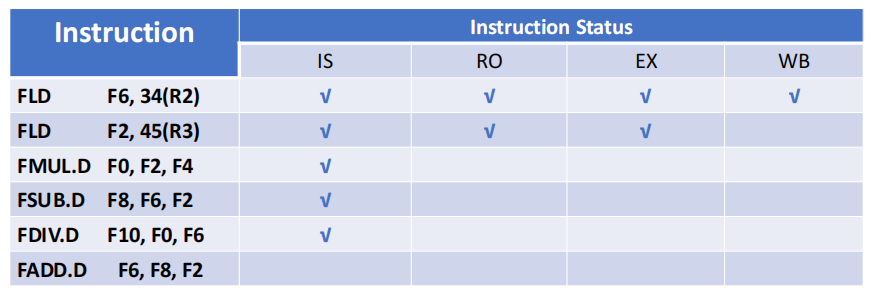
- 阶段一:仅第一条
FLD F6完成写回
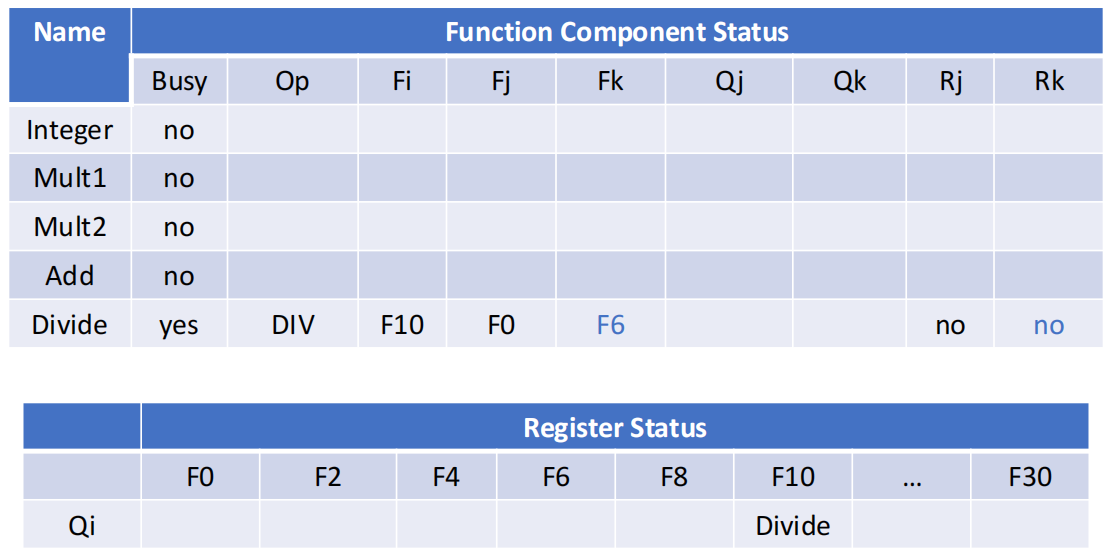
Function Unit Status 典型字段
- \(Qj/Qk\):将产生源操作数 \(Fj/Fk\) 的功能部件
Rj/Rk:yes:操作数已经就绪但还没读no且Qj/Qk = null:操作数已读走no且Qj/Qk != null:操作数还没就绪
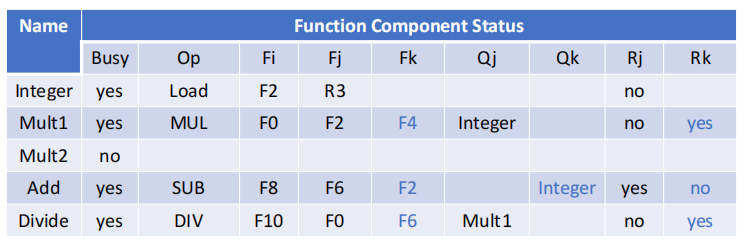
Register Status
记录某个寄存器将由哪个功能部件写回。

- 阶段二:
FMUL.D F0准备写回
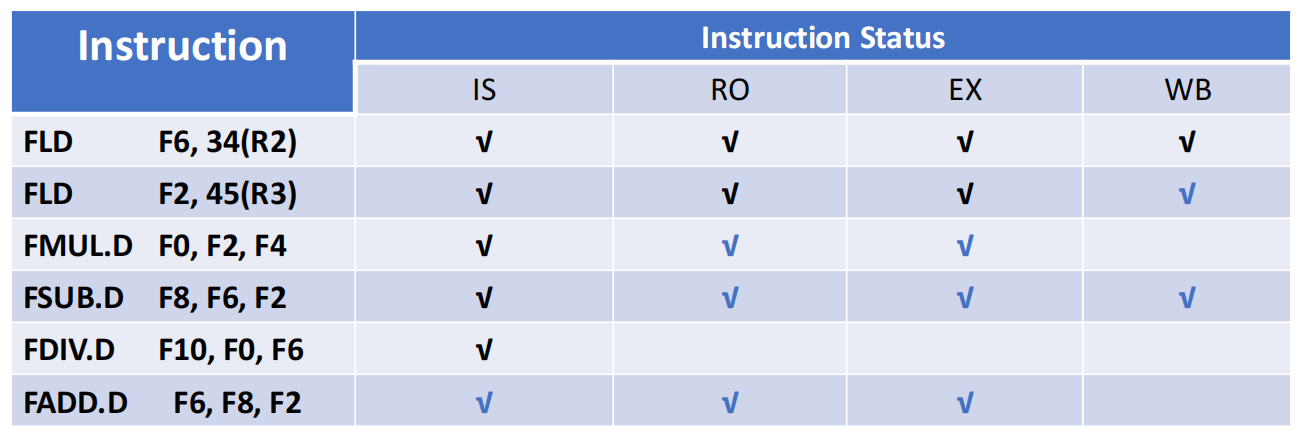
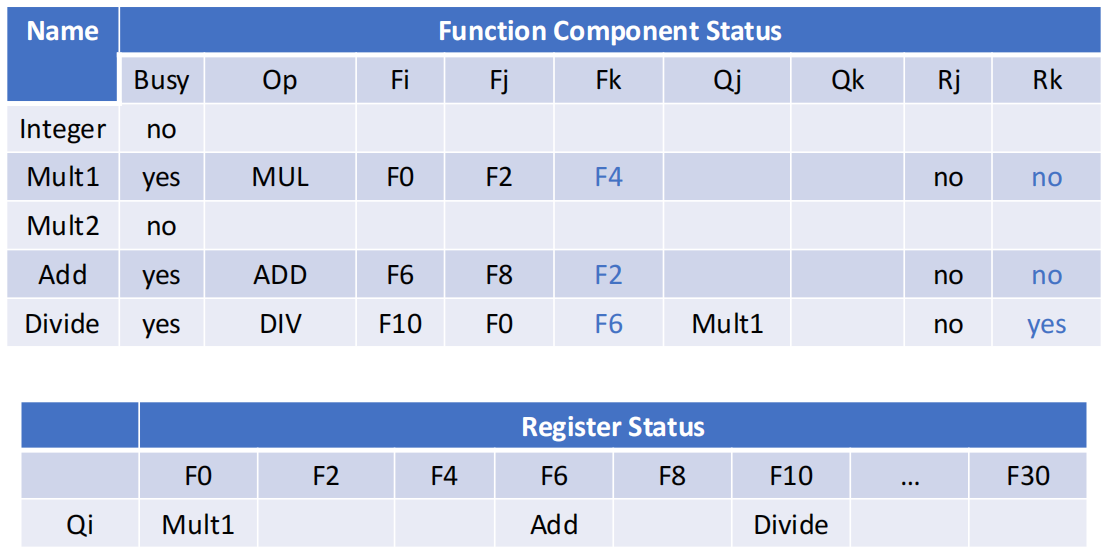
- 阶段三:
FDIV.D F10准备写回
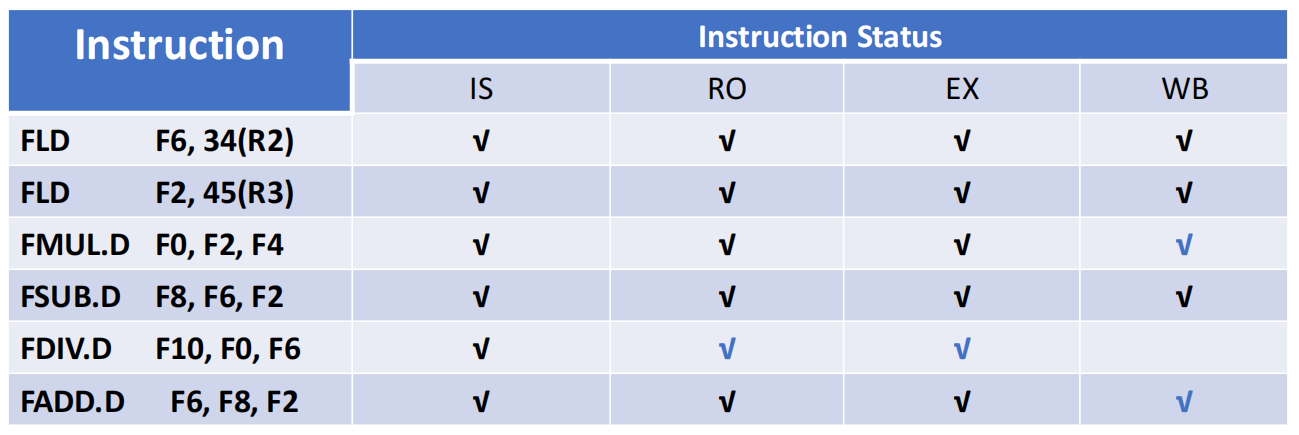
- IS 阶段:按序发射,同时检查结构冒险与 WAW 冒险,均无冲突则分配功能部件并更新状态。
- RO 阶段:乱序等待,仅检查 RAW 冒险,源操作数全部就绪则读取并进入执行(可同步)。
- EX 阶段:不同功能部件按各自延迟执行,完成后通知记分牌。
- WB 阶段:仅检查 WAR 冒险,等冲突指令完成 RO 后再执行 WB,避免覆盖尚未被读取的旧值。
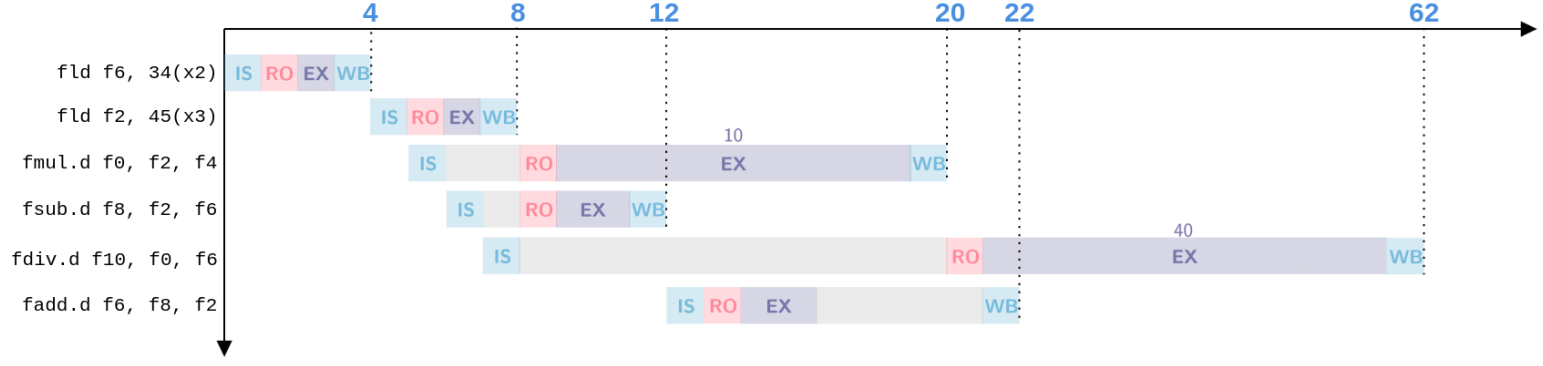
Practice in class
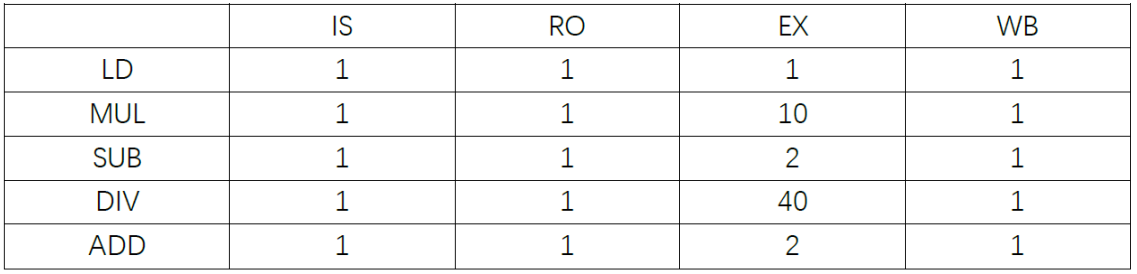
Suppose: Add instruction needs 2 clock cycles. Multiply instruction needs 10 clock cycles. Division instruction needs 40 clock cycles. LD instruction need 1 clock cycles.
FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F6, F2
FDIV.D F10, F0, F6
FADD.D F6, F8, F2
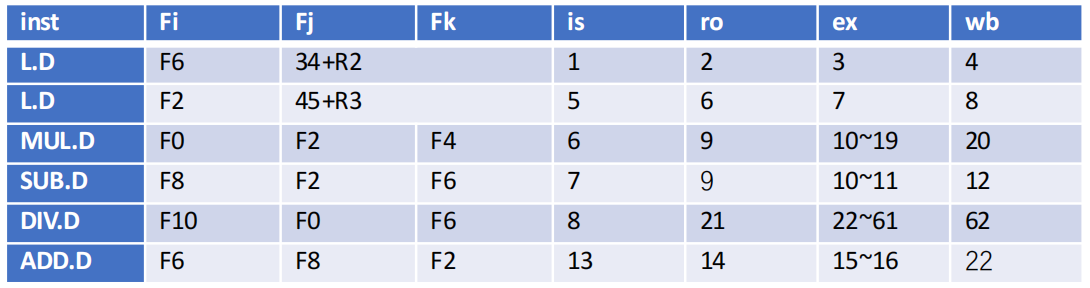
How many clock cycles does it take to finish each instruction using scoreboard algorithm?
答案
1. 2 Tomasulo's Approach¶
引入

对于以上序列,若引入临时寄存器 S、T,可重写为:
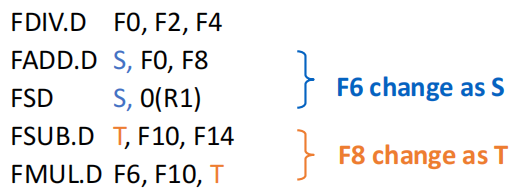
从而消除了名字相关。
Tomasulo 算法在动态调度基础上加入硬件寄存器重命名(register renaming),从而大幅缓解 WAR / WAW,效果通常优于 Scoreboard 算法,该算法主要分为以下三个阶段:
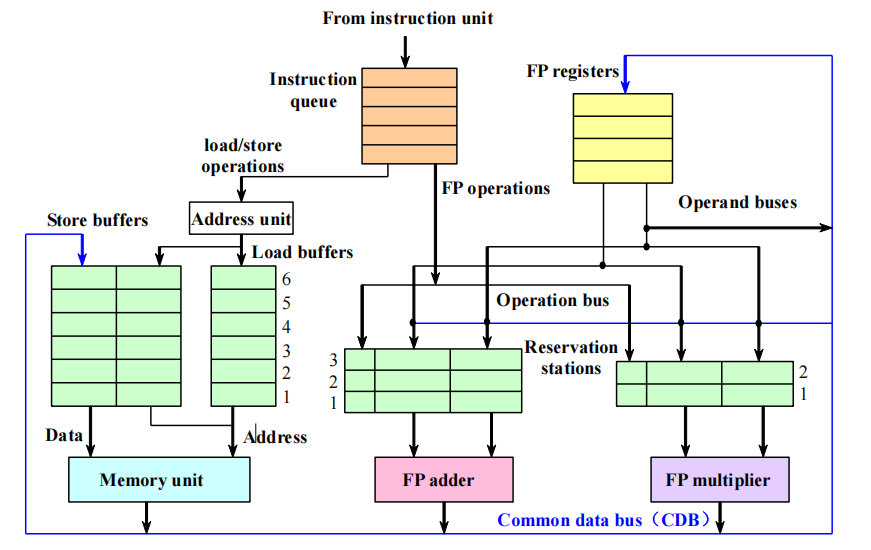
- IS 阶段:按序取指,分配对应保留站,无空闲保留站则结构冒险阻塞,就绪操作数直接下发,未就绪则跟踪生成该操作数的功能单元,通过寄存器重命名消除 WAR、WAW 冒险。
- EX 阶段:操作数全部就绪后乱序执行,
Load/Store指令先计算有效地址(额外 \(1\) 拍),再存入加载/存储缓冲区。 - WB 阶段:运算结果经公共数据总线(CDB)广播,同时写入目标寄存器与所有等待该结果的保留站(包括存储缓冲区),
Store指令需地址、数据均就绪且内存空闲时才写入内存。
Tomasulo 算法处理流程示例
- 初始状态:指令队列存放待发射的两条指令,浮点寄存器、寄存器状态表 Qi、保留站和功能单元均空闲。
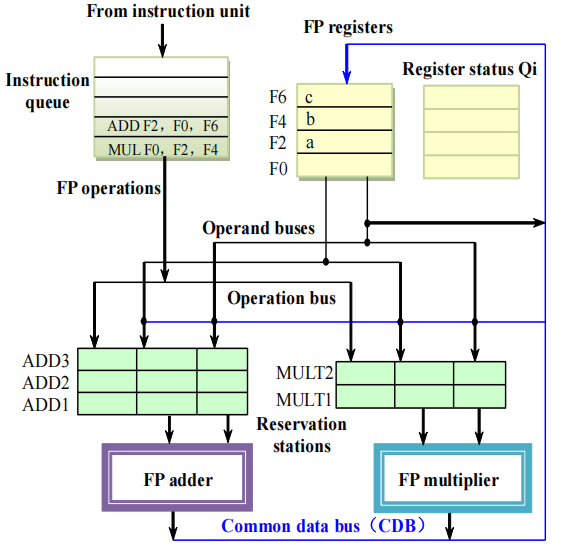
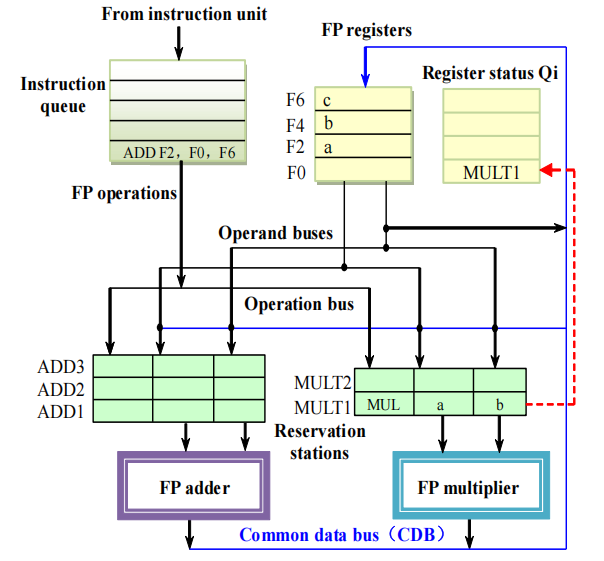
- 发射乘法指令
MUL F0, F2, F4:F2、F4 的值都在寄存器中就绪,直接存入 MULT1,操作类型标记为 MUL,目标寄存器 F0 的 Qi 标记为 MULT1,指令被发送到 FP multiplier 开始执行。
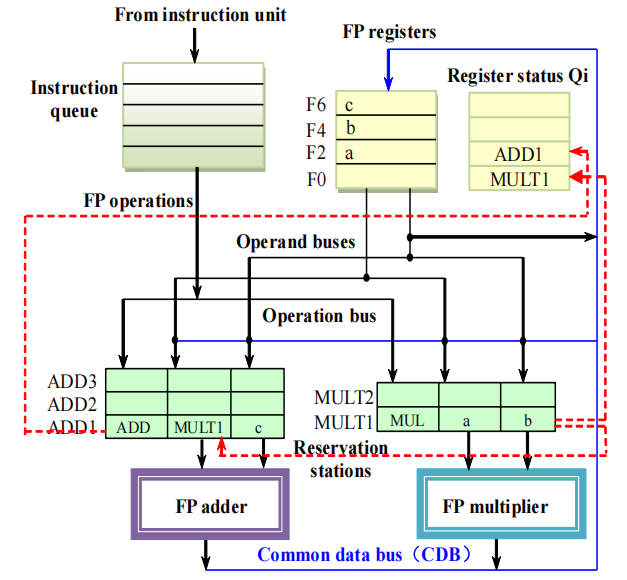
- 发射加法指令
ADD F2, F0, F6:F6 的值在寄存器中就绪,存入 ADD1,F0 的 Qi 是 MULT1,所以 ADD1 把第一个操作数标记为 MULT1,操作类型标记为 ADD,目标寄存器 F2 的 Qi 标记为 ADD1,等待 MULT1 执行完毕。
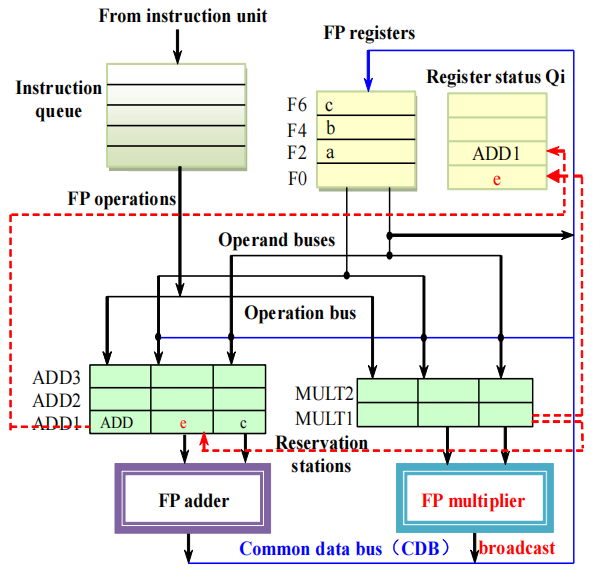
- 乘法指令完成,结果广播:FP multiplier 算完 MULT1 后,结果通过 CDB 广播到所有需要它的地方,更新 F0 的值并清除 F0 的 Qi 标记,更新 ADD1 里等待 MULT1 的操作数,MULT1 保留站被释放,变回空闲,ADD1 操作数就绪,可发送到 FP adder 开始执行,F2 仍标记为 ADD1。
Tomasulo 算法的三张表
- Instruction status table:只用于理解流程,不一定真是硬件的一部分
- Reservation stations table:记录每条已发射操作的状态
- Register status table(Field Qi):记录哪个 RS 最终会把结果写到该寄存器
Reservation Station 的 7 个字段
| 字段 | 含义 |
|---|---|
Busy |
该 RS 是否被占用 |
Op |
操作类型 |
Vj, Vk |
已经可用的源操作数值 |
Qj, Qk |
未来会产生对应源操作数的 RS 编号 |
A |
访存地址相关信息(load/store 用) |
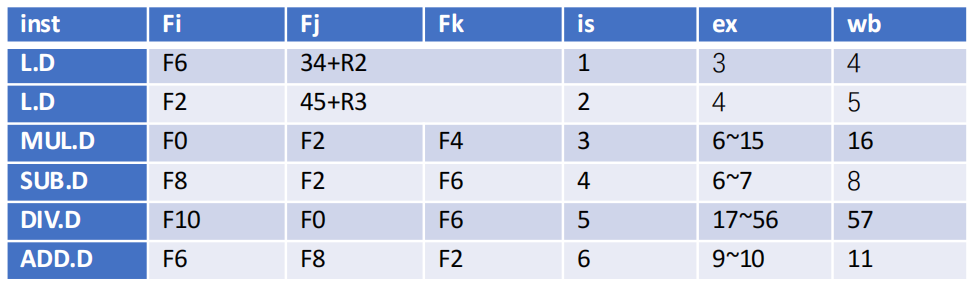
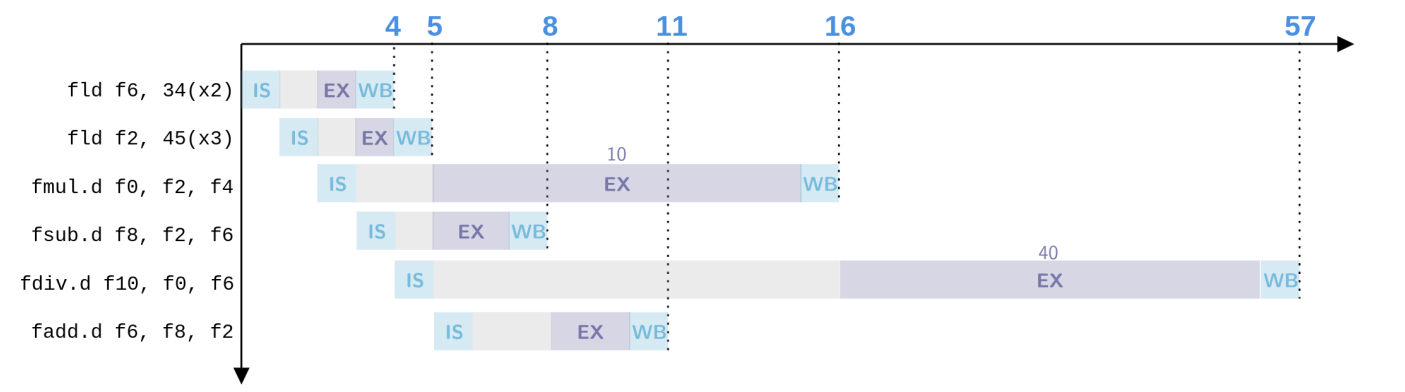
示例
FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F6, F2
FDIV.D F10, F0, F6
FADD.D F6, F8, F2
- 阶段一:仅第一条
FLD F6完成写回
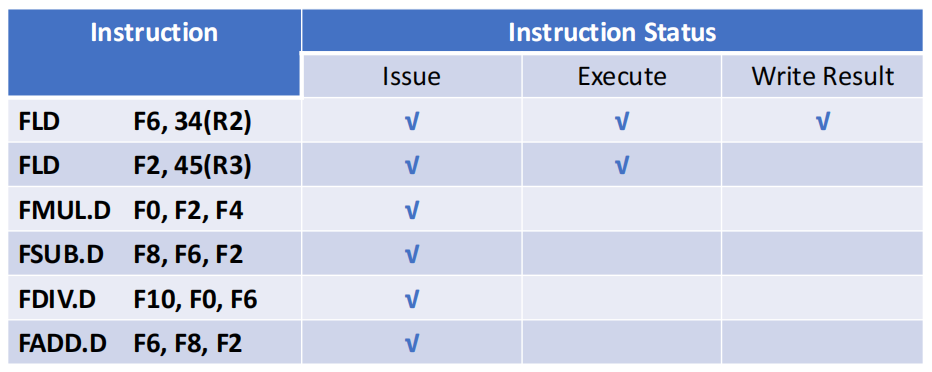
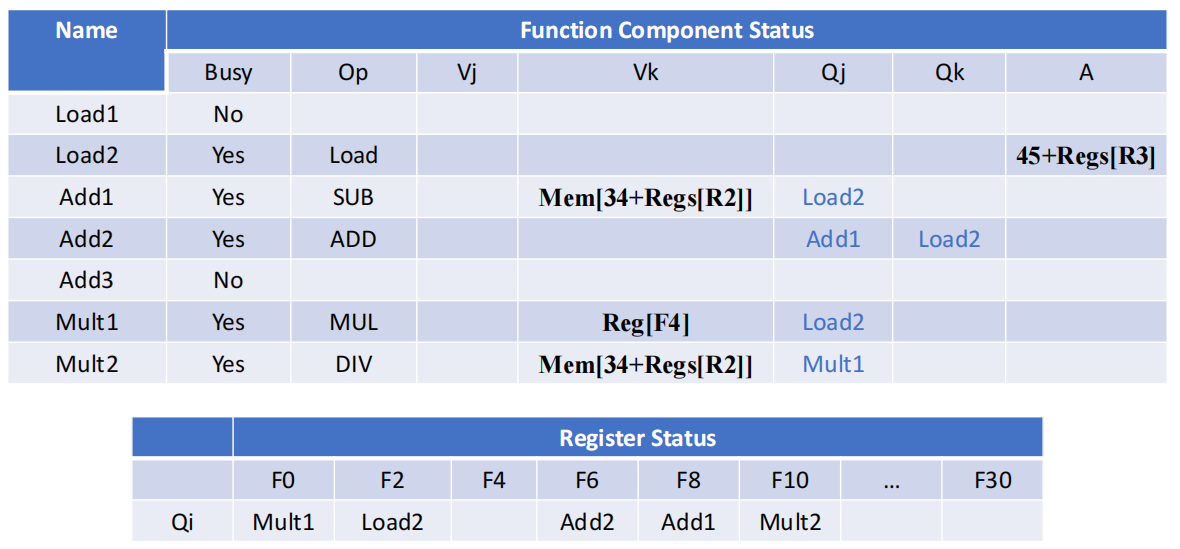
- 阶段二:
FMUL.D F0准备写回
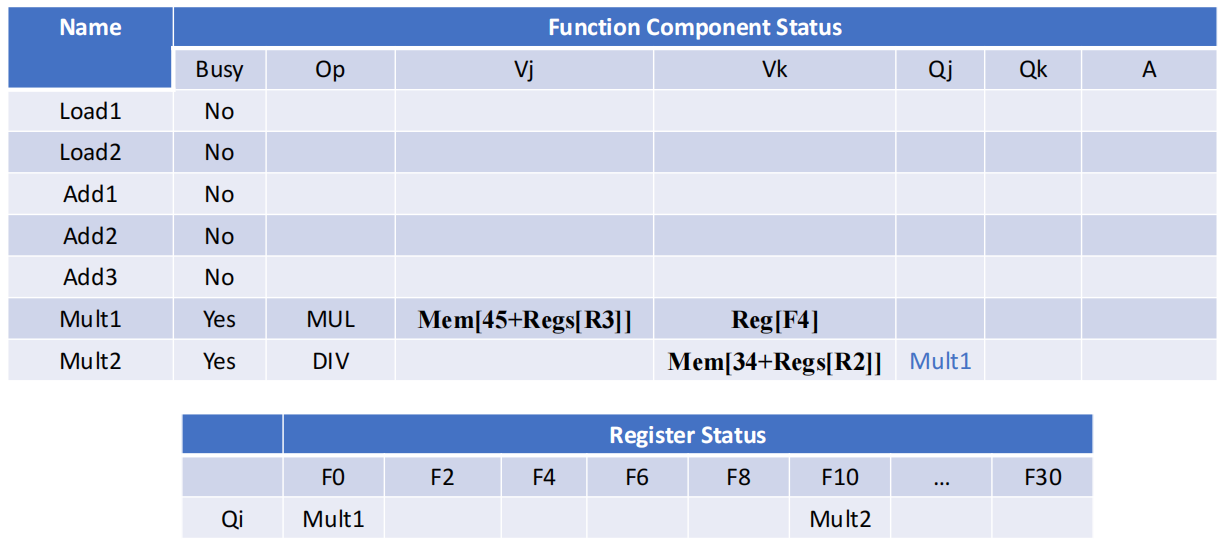
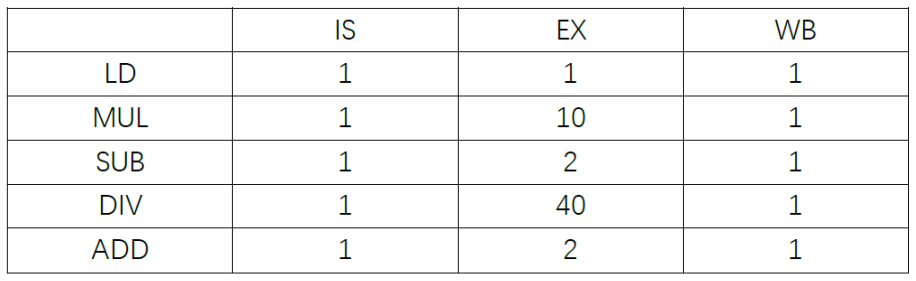
Practice in class
Suppose: Add instruction needs 2 clock cycles. Multiply instruction needs 10 clock cycles. Division instruction needs 40 clock cycles. LD instruction need 1 clock cycles.
FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F6, F2
FDIV.D F10, F0, F6
FADD.D F6, F8, F2
How many cycles does it take to finish each instruction using Tomasulo's approach?
答案
局限
- 硬件结构复杂
- CDB 可能成为性能瓶颈
load与store访问不同地址时,可以安全乱序,但若访问同一地址:load在前、store在后:交换会造成WARstore在前、load在后:交换会造成RAW- 两个
store写同一地址:会造成WAW
ILP 的继续提升越来越受限于可挖掘的指令级并行本身有限及硬件复杂度持续上升,这也是后来走向多核(multicore)的重要原因之一。
Does out-of-order execution mean out-of-order completion?
不一定。在原始 Tomasulo 中,写结果本身可能乱序,但加入 ROB 后,可以做到乱序执行(out-of-order execution)、按序提交(in-order commit)。
2 Hardware-Based Speculation¶
为什么需要 ROB
Tomasulo 可以很好地解决寄存器相关并支持乱序执行,但如果直接把结果写回寄存器:
- 分支预测失败时很难撤销已经写入的结果
- 异常可能变得不精确(imprecise exception)
store一旦提前写内存,也无法轻易回滚
因此需要加入 Reorder Buffer(ROB),把尚未提交的结果先缓存在硬件里,等轮到它按序提交时,再真正更新寄存器或内存。
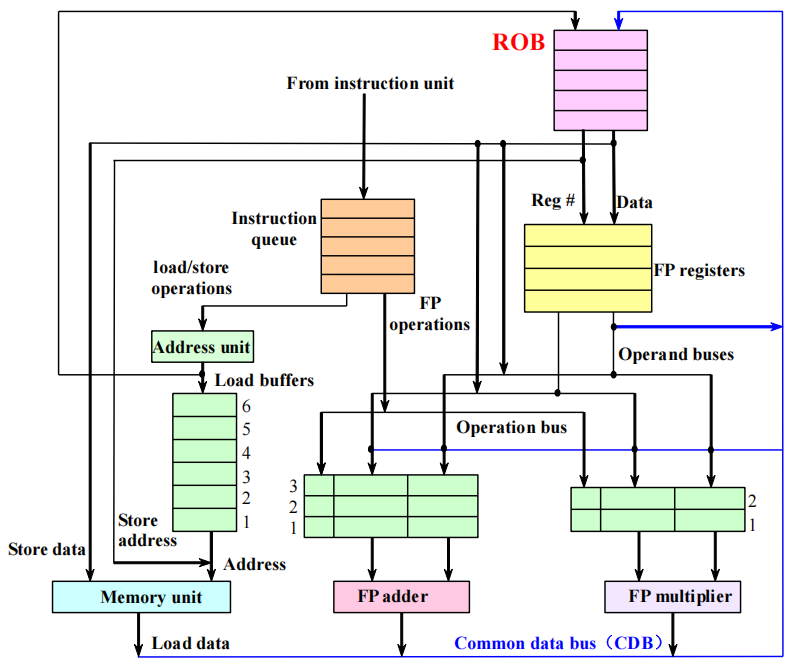
核心思想
Hardware-based speculation 把以下三件事结合在一起:
- 动态分支预测(dynamic branch prediction):先猜接下来该执行哪条路径
- 推测执行(speculation):在控制相关尚未真正解决前,先执行后续指令
- 动态调度(dynamic scheduling):让来自不同基本块的指令也能被硬件重新安排
关键目标是:允许乱序执行,但必须按序提交(commit),这样一旦分支预测失败或发生异常,只需要丢弃 ROB 中尚未提交的年轻指令就能恢复到正确的体系结构状态,store 也要等到提交时才真正写内存,因此更容易恢复。
- IS 阶段:从指令队列取指,分配保留站(RS)和一个新的 ROB 表项,目标寄存器不再直接绑定功能部件,而是记录为某个
ROB#。 - EX 阶段:当源操作数就绪后开始执行,操作数既可能来自寄存器,也可能来自保留站或 ROB 的广播结果。
- WB 阶段:执行完成后结果先写入 ROB,并通过 CDB 广播给等待它的保留站,但此时还不更新体系结构寄存器。
- Commit 阶段:只有当指令来到 ROB 队首且结果已经准备好时,才按程序顺序把结果真正写入寄存器或内存。
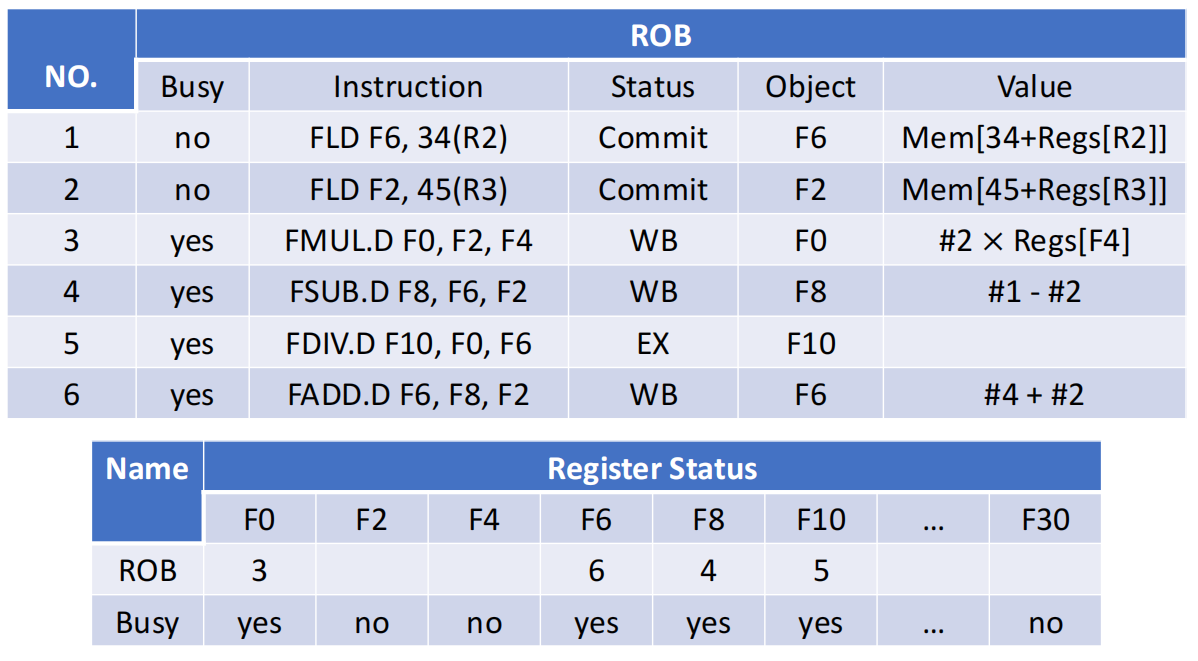
Show what the status tables look like when the FMUL.D is ready to commit.
FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F6, F2
FDIV.D F10, F0, F6
FADD.D F6, F8, F2
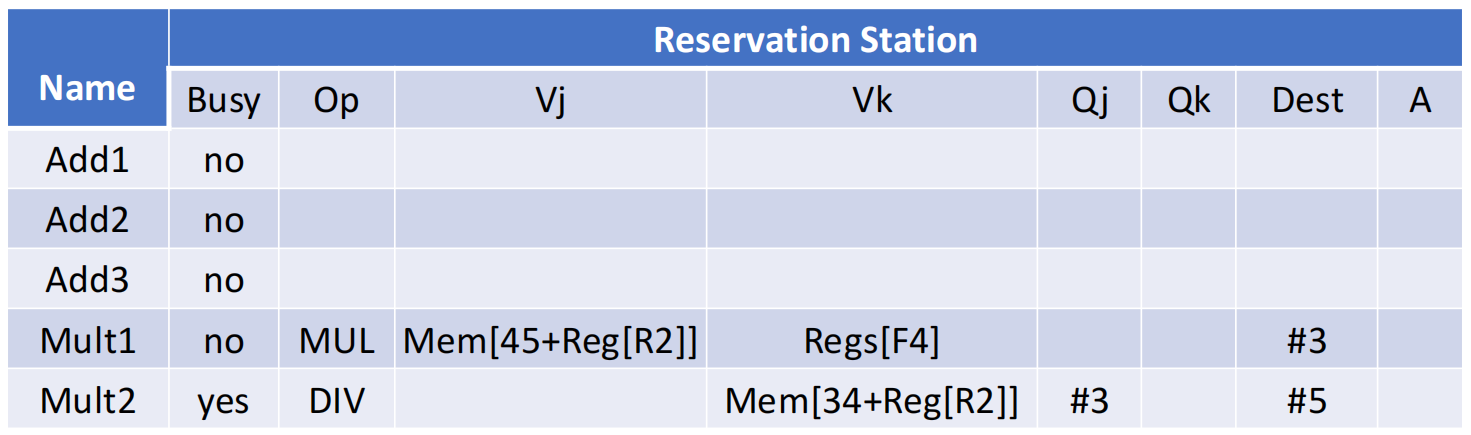
ROB#1、ROB#2对应两条FLD,已经完成并可提交ROB#3对应FMUL.D,结果已经写入 ROB,下一步即可提交到F0ROB#4对应FSUB.D,虽然已经WB,但仍要等待更老的指令先提交ROB#5对应FDIV.D,仍在执行ROB#6对应FADD.D,结果也已经写好,但同样不能越过前面的指令提交
Practice in class
Suppose: Add instruction needs 2 clock cycles. Multiply instruction needs 10 clock cycles. Division instruction needs 40 clock cycles. LD instruction need 1 clock cycles.
FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F6, F2
FDIV.D F10, F0, F6
FADD.D F6, F8, F2
How many cycles does it take to finish each instruction by hardware-based speculation?
答案
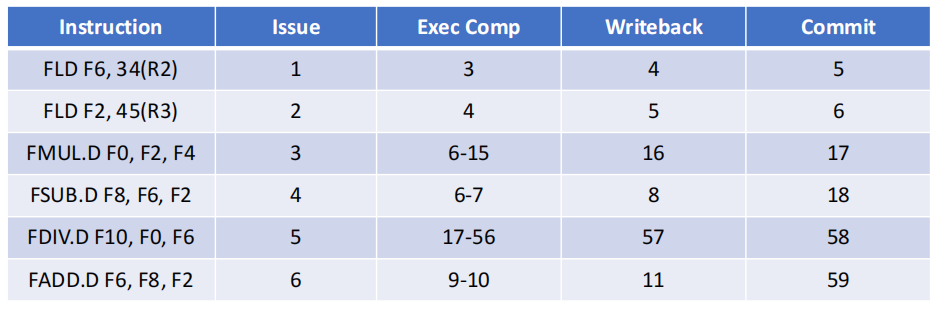
ROB 让处理器在保留乱序执行能力的同时,恢复按序完成的外部语义,这使得异常精确、分支回滚容易,也更容易把同样的方法扩展到整数寄存器和整数功能部件,但硬件更复杂,ROB、CDB、提交逻辑都会增加实现成本。
3 Exploiting ILP Using Multiple Issue and Static Scheduling¶
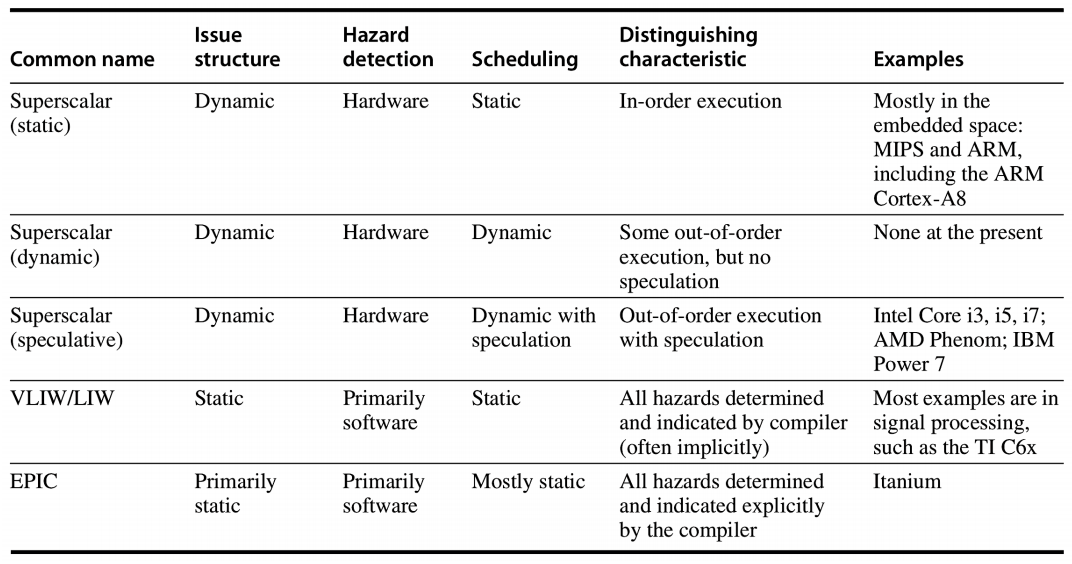
两类典型的多发射处理器
| 类型 | 发射宽度 | 调度方式 |
|---|---|---|
| Superscalar | 每周期发射条数不固定,但有上限 n |
可静态,也可动态 |
| VLIW | 每周期发射条数固定,共同组成一条长指令(指令包),常见为 4-16 |
主要靠编译器静态调度 |
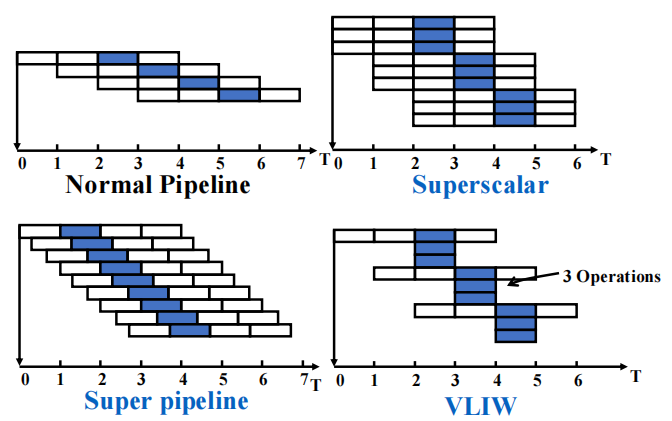
- Superscalar:对程序员透明,硬件自己判断哪些指令当前可以并行发射,因此对旧代码更友好
- VLIW:指令包中显式表达并行性,编译器提前把可并行操作打包好,硬件更简单,但编译器压力更大
3. 1 Multi-Issue Technology Based on Static Scheduling¶
在典型的超标量处理器中,每个周期可发射 1-8 条指令,但这些指令仍然通常按序发射,并在发射时进行冲突检测。
常见做法是把同一周期取来的若干条指令看成一个发射包(issue packet),然后分两步检查:
- 先检查这个发射包内部是否互相冲突,初步筛选出可以流出的指令
- 再检查这些候选指令与流水线中正在执行的旧指令是否冲突
MIPS 风格的双发射假设
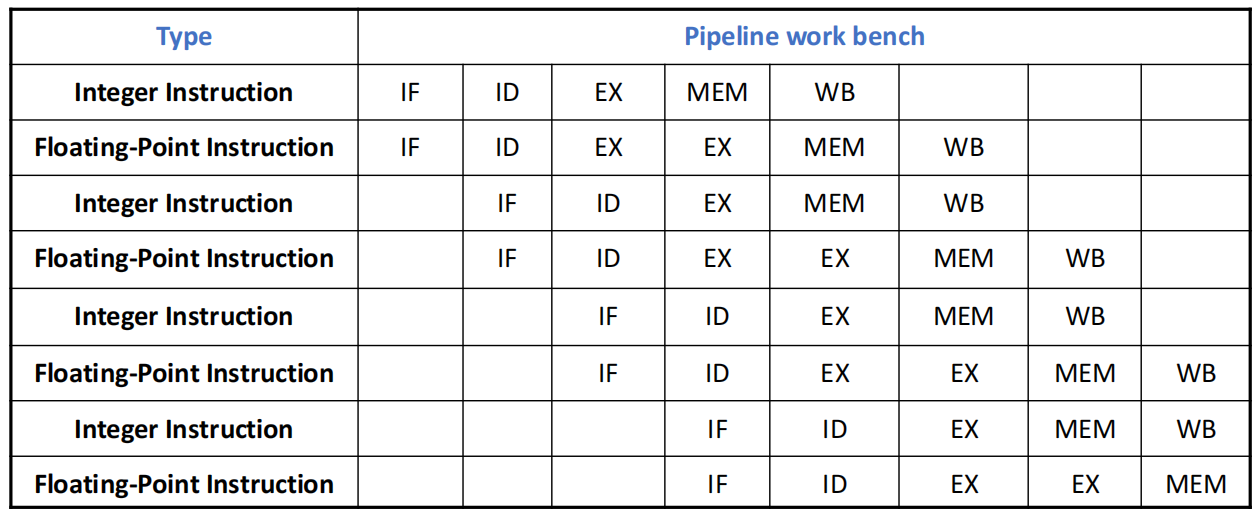
为了降低硬件复杂度,限制每周期最多发射两条指令,一条是整数类指令,另一条是浮点类指令,其中 load / store / branch 也归到整数类指令中。
指令处理包含从 Cache 中取指、确定可流出指令和将指令发送到对应功能部件三个步骤。
假设所有浮点指令均为加法指令,且执行时间为两个时钟周期,则有多发射超标量流水线的指令执行过程示例图如下(为简化起见,图中整数指令总是被放置在浮点指令之前):
开销与优化
- 硬件增量相对较小
- 浮点
load/store会占用整数部件,带来新的结构冲突,需为浮点寄存器增设一组读 / 写端口 - 发射宽度翻倍后,流水线中的在途指令数也随之上升,控制逻辑更复杂,用于数据转发的定向路径(directional path)也必须相应增加
3. 2 Multi-Issue Technology Based on Dynamic Scheduling¶
扩展 Tomasulo 支持双发射
动态调度版本可以看成是带多发射能力的 Tomasulo,一种较简单的实现方法是:
- 每周期最多发射两条指令(一条整数指令 + 一条浮点指令)
- 指令仍按序进入各自的保留站,否则会破坏程序语义
- 整数和浮点部分使用分离的表结构与功能部件
循环示例
Loop: # 把标量加到数组每个元素上
LD X2, 0(X1) # X2 = array element
ADDI X2, X2, 1 # increment X2
SD X2, 0(X1) # store result
ADDI X1, X1, 8 # increment pointer
BNE X2, X3, Loop # branch if not last
现做出如下假设:
- 每个时钟周期可流出一条整数指令和一条浮点指令,即便二者存在依赖关系。
- 设有一个整数部件,用于执行整数 ALU 运算与地址计算;针对每类浮点运算,均配备一个独立的流水线化浮点功能部件。
- 指令流出与结果写回各耗时一个时钟周期。
- 配备动态分支预测部件,以及一个独立的功能部件用于计算分支条件。
- 分支指令单独流出,不采用延迟分支,但分支预测完全准确。在分支指令执行完成前,其后续指令仅可被取指与流出,不可进入执行阶段。
由于结果写回需要占用一个时钟周期,因此结果生成的延迟为:整数运算 1 个周期、加载操作 2 个周期、浮点加法 3 个周期。
若不做推测,程序前三次循环每条指令的运行结果如下:
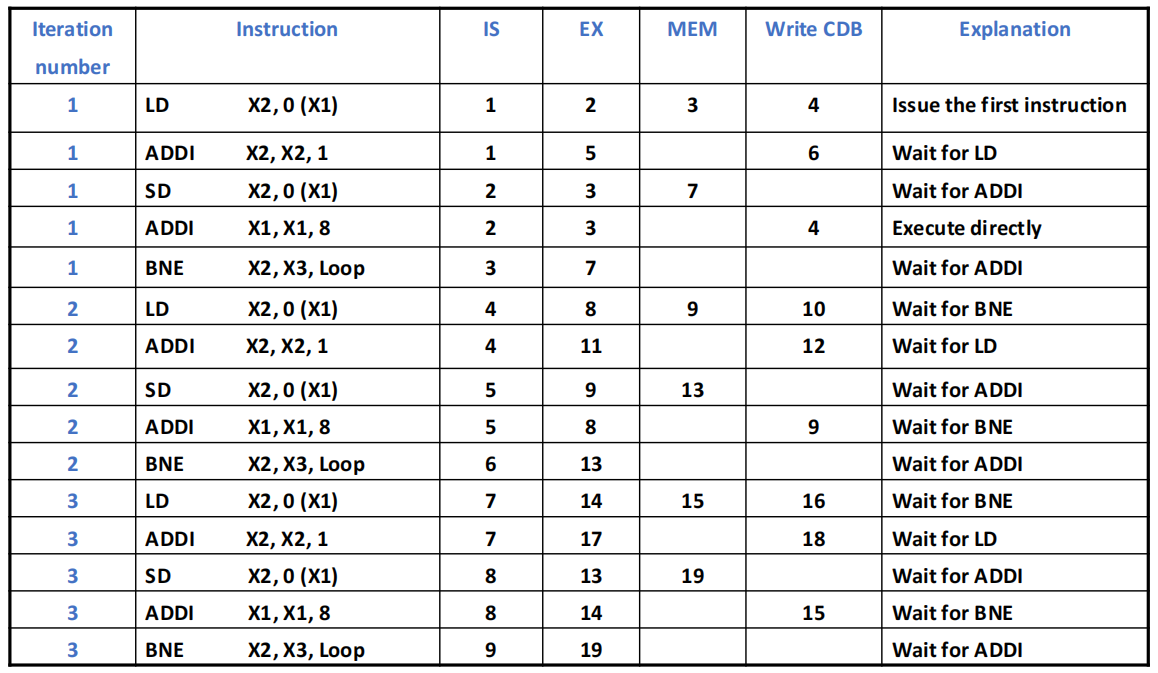
可以看出,尽管指令流出率相对较高,但执行效率并不理想,IPC 仅为 0.79,原因在于存在数据依赖型分支,且地址计算与整数运算共用 ALU,可以新增一个加法器,将 ALU 运算功能与地址计算功能分离。
如果允许结合分支预测 + ROB 提交进行硬件推测,后续迭代的指令可以更早进入执行,具体运行结果如下:
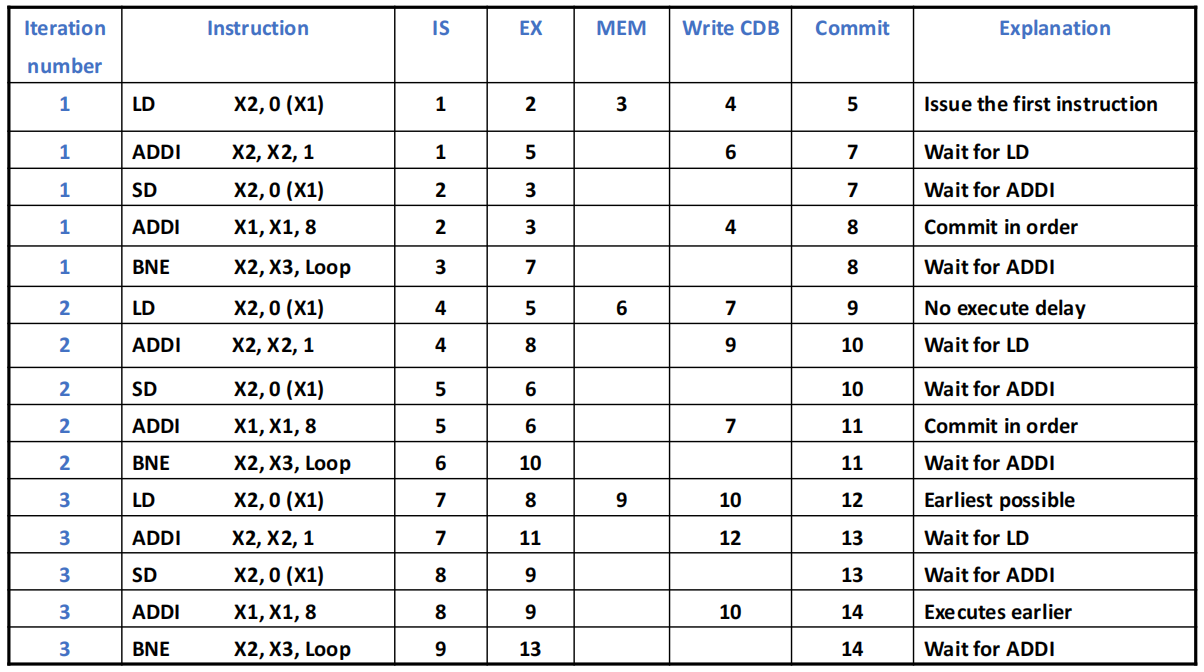
相较非推测流水线,由于等待分支而产生的停顿显著减少,当分支确实高度可预测时,性能会明显提升。
但这一优势依赖于预测准确率,错误推测不仅不能提高性能,还会带来额外能耗和回滚开销。
3. 3 Very Long Instruction Word (VLIW)¶
VLIM 会把多条可并行执行的操作打包成一条超长指令,并划分为多个字段,每个字段称为一个操作槽(operation slot),可直接、独立地控制一个功能单元。
所有的指令处理与排布工作均由编译器完成,故并行性由编译器显式表达,调度主要在编译期完成,硬件在运行时不必像 superscalar 那样做复杂的动态判定。
存在问题
- 程序代码长度增加:
- 为了暴露更多并行性,经常需要大量循环展开(loop unrolling)
- 很多时候指令字中的 slot 填不满,即存在空槽
- 常采用压缩存储、共享立即数字段等办法缓解代码膨胀
- 存在锁步机制(Lockstep mechanism):某个操作槽停顿时,整个处理器都必须同步暂停
- 机器码兼容性差,不同实现之间很难直接复用二进制程序
What are the limitations of the instruction multi-flow processor?
- 程序本身固有的指令级并行度(ILP)
- 硬件实现层面的困难
- 超标量与超长指令字(VLIW)处理器自身固有的技术限制
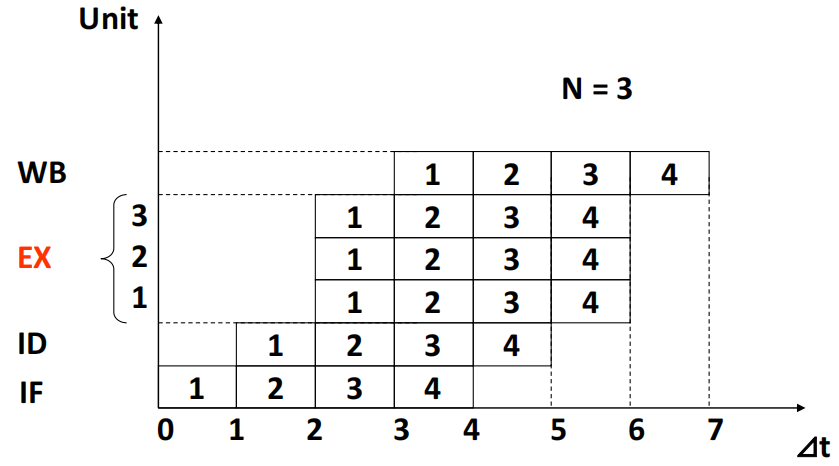
3. 4 Superpipelining¶
超流水线的思想是将每个流水线阶段进一步细分,使得多条指令可以在一个时钟周期内分时复用。拥有 8 个或更多指令流水线阶段的流水线处理器被称为超流水线处理器。
对于每个时钟周期可流出 \(n\) 条指令的超流水线计算机,这 \(n\) 条指令并非同时流出,而是每隔 \(1/n\) 个时钟周期流出一条指令。
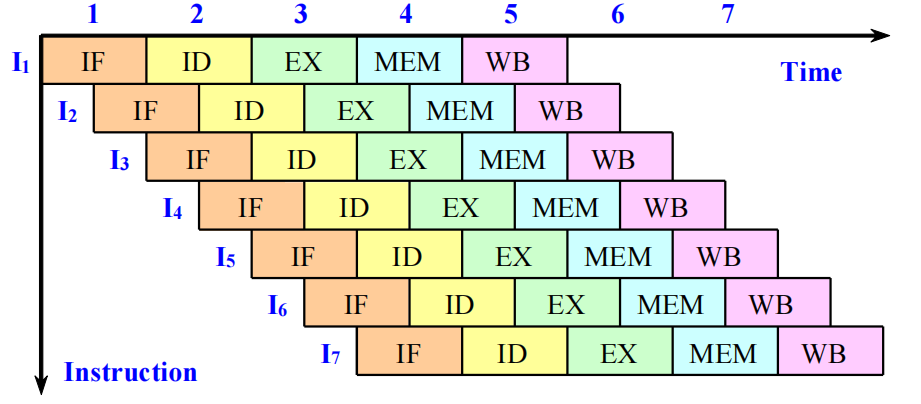
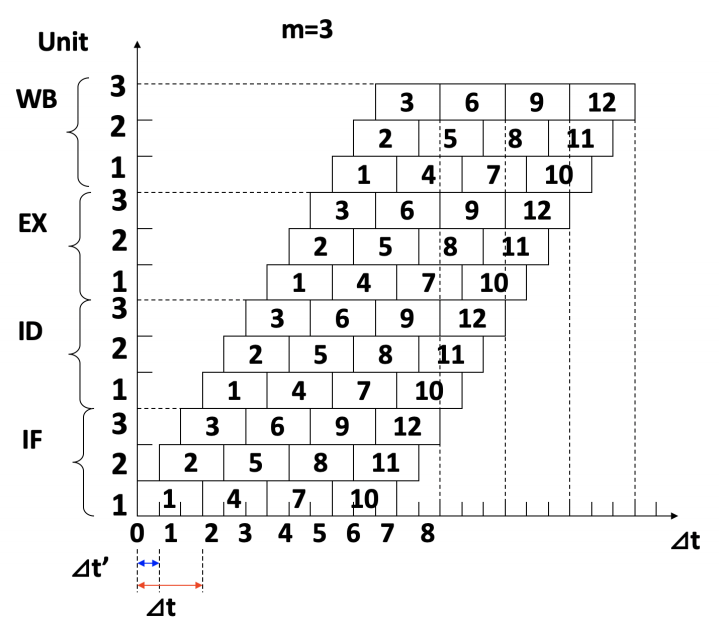
MIPS R4000 的 8 级流水
R4000 微处理器芯片内包含 2 个 Cache,分别是指令缓存(Instruction Cache)与数据缓存(Data Cache),容量均为 8 KB,每个缓存的数据位宽为 64 位。
R4000 的核心处理部件(整数部件)包括:一个 32×32 位的通用寄存器组、ALU 和专用的乘 / 除法单元。
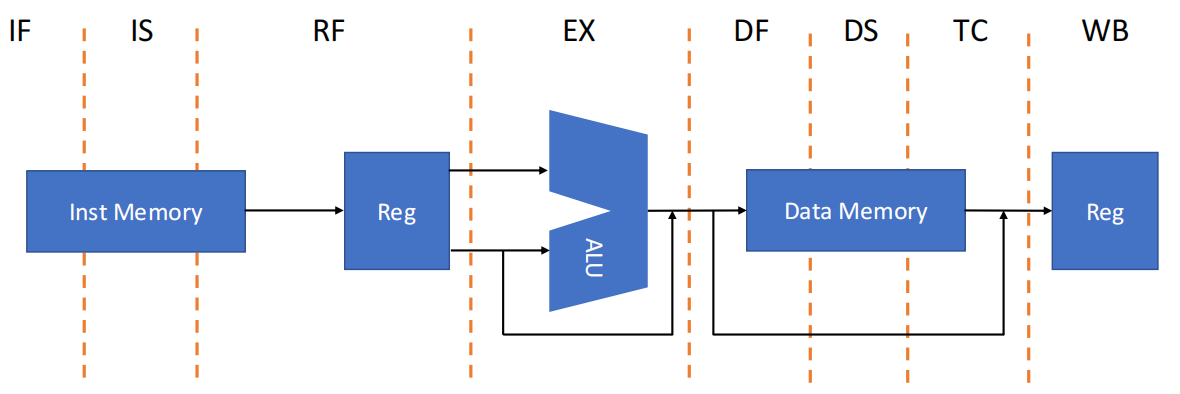
- IF:取指前半段,同时进行 PC 选择并启动指令 Cache 访问
- IS:取指后半段,完成指令 Cache 访问
- RF:译码、读寄存器、冒险检查、检测指令 Cache 是否命中
- EX:执行阶段,包含地址计算、ALU 运算、分支目标与条件判断
- DF:数据 Cache 访问前半段
- DS:数据 Cache 访问后半段
- TC:Tag Check,判断数据 Cache 是否命中
- WB:写回
load结果或寄存器-寄存器运算结果
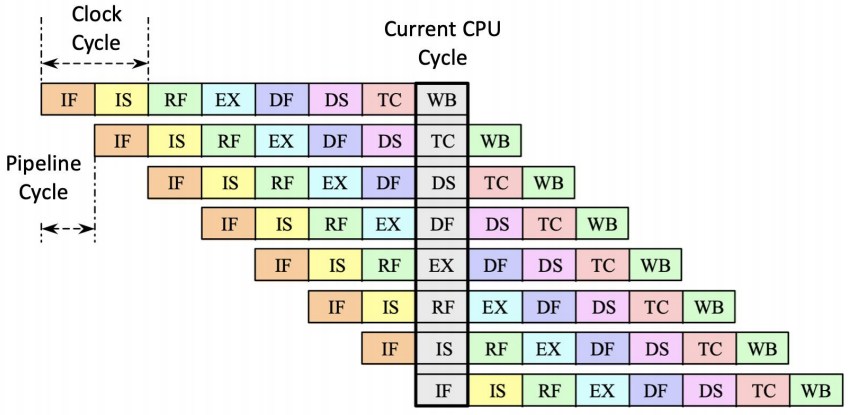
这种深流水设计能提高频率,但也会让 load delay、分支代价和冒险处理更加敏感。