Chapter 3 Hazard of Pipelining¶
1 结构冒险(Structural Hazards)¶
- 问题:流水线中的两条或多条指令竞争对单一物理资源的访问
- 解决方案:
- 指令轮流使用资源,一些指令不得不暂停
- 给机器添加更多硬件(通过添加更多硬件,总能解决结构冒险)
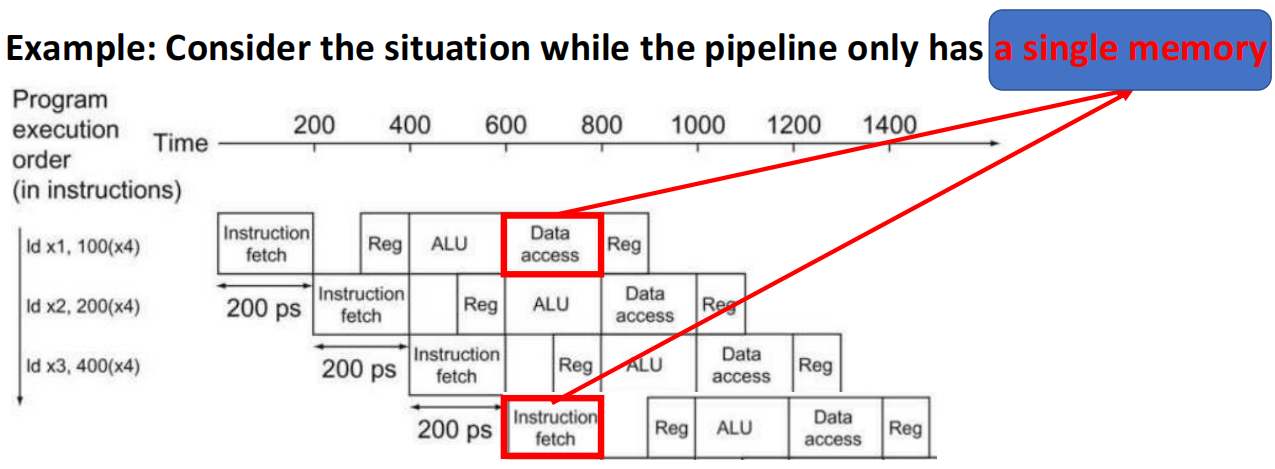
2 数据冒险(Data Hazards)¶
当指令间存在数据依赖时,若前一条指令还未完成数据的读 / 写,后续指令就需要等待,导致流水线停顿,效率下降。
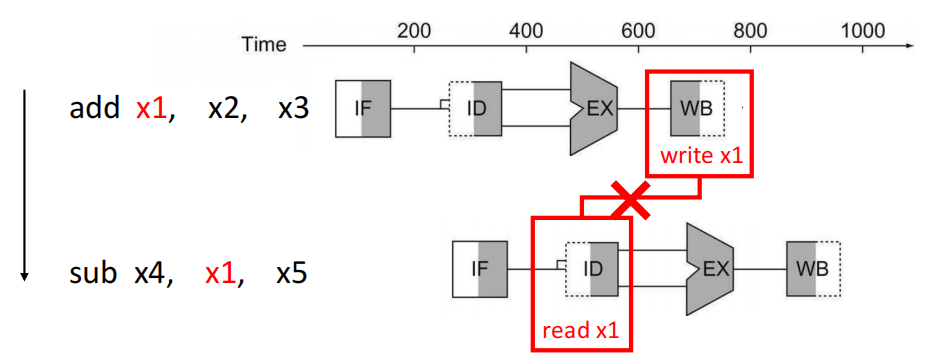
2. 1 转发(Forwarding)¶
转发(Forwarding)通过额外硬件提前从流水线的内部寄存器中获取所需数据,减少了等待时间。
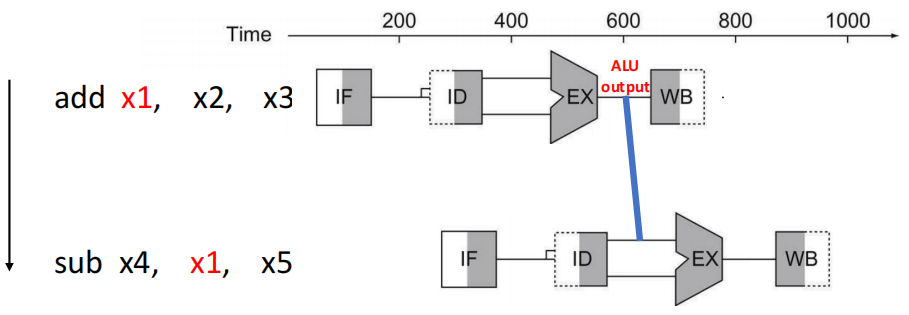
若前一条指令是算术逻辑运算(如 add、sub、and 等),其结果在 EX 阶段就可以获取,此时后续指令可直接从 EX/MEM 寄存器中转发结果,无需等待 WB 阶段。
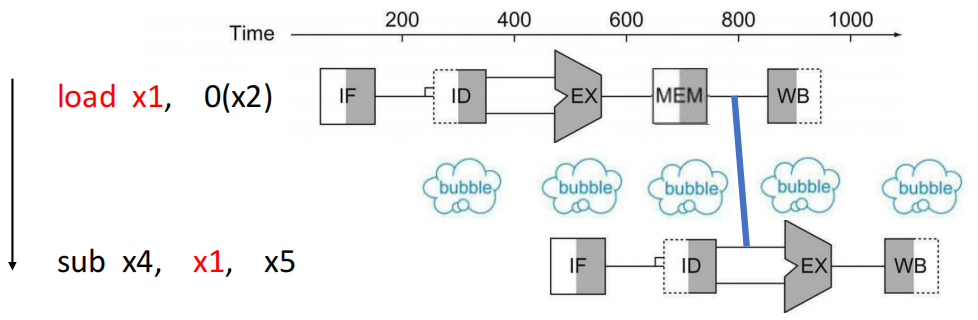
然而,转发无法解决所有流水线停顿,若前一条指令是 load ,其有效数据要到 MEM 阶段才可用,后续依赖该数据的指令仍需停顿。
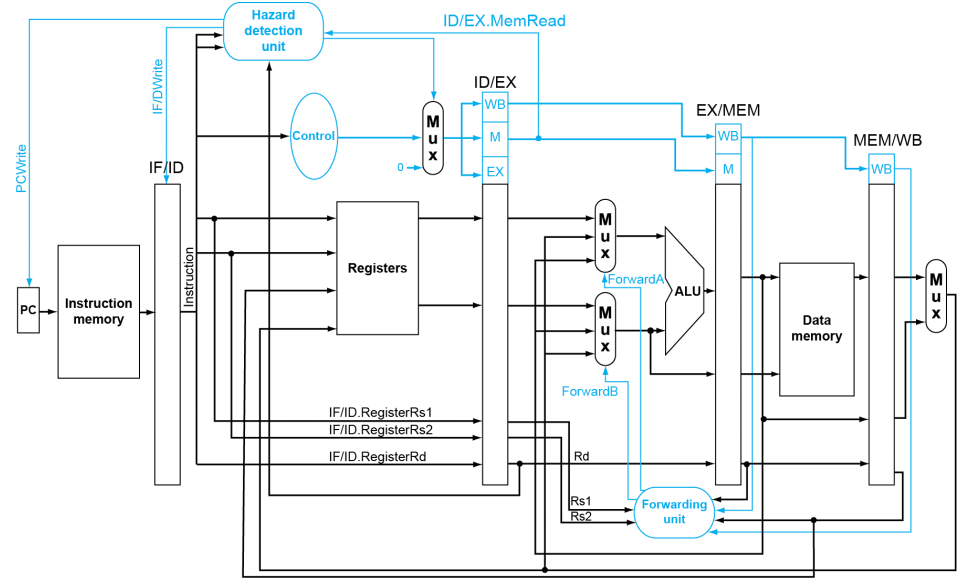
- EX Hazard:若
EX/MEM.RegWrite = 1 && EX/MEM.Rd ≠ 0,且EX/MEM.Rd = ID/EX.Rs1/Rs2,则ForwardA/B = 10,从前一条 ALU 指令的结果转发操作数 - MEM Harzard:若
MEM/WB.RegWrite = 1 && MEM/WB.Rd ≠ 0 && not(EX Hazard),且MEM/WB.Rd = ID/EX.Rs1/Rs2,则ForwardA/B = 01,从内存数据或更早的 ALU 结果转发操作数 - Load-Use Hazard:若
ID/EX.MemRead = 1且ID/EX.Rd = IF/ID.Rs1/Rs2,需要让流水线停顿并插入气泡(空指令)
2. 2 Stall 机制¶
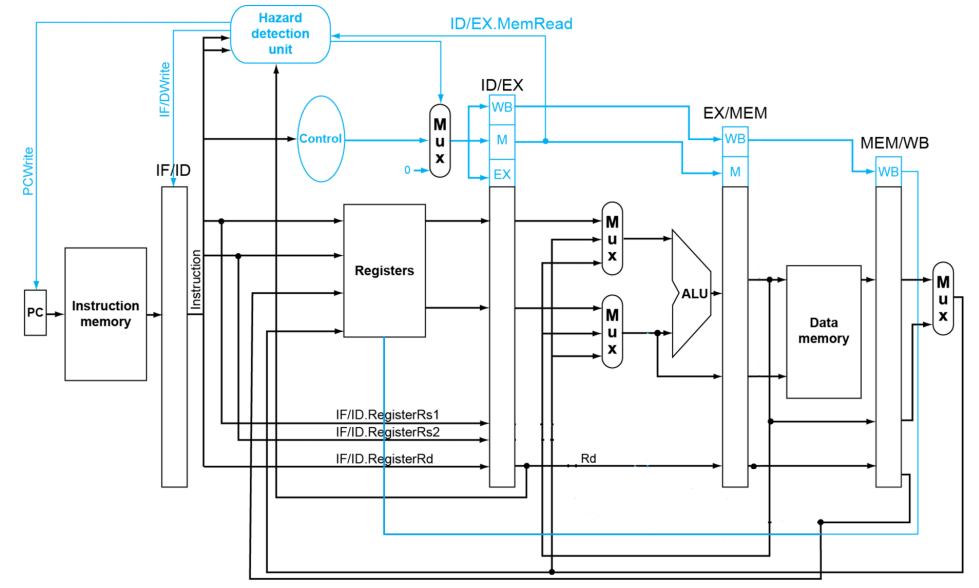
nop 指令表示 ADDI x0,x0,0,相当于空指令,可用于 stall 机制

- 将 ID/EX 寄存器中的控制值强制置 0
- EX、MEM 和 WB 阶段执行空操作(nop)
- 阻止 PC,IF/ID 寄存器及 ID/EX 寄存器的更新
- 当前使用的指令被再次解码
- 后续的指令被再次取指
- 1 个周期的停顿使 MEM 阶段能够为
ld指令读取数据,随后可以 forward到 EX 阶段
- stall 会降低性能,但为了得到正确结果,stall 是必需的
- 编译器可调整代码以避免冒险和停顿
3 控制冒险(Control Harzards)¶
当程序的执行流依赖于前一条指令(通常是分支指令)时,在分支结果确定前,流水线无法确定下一条该取哪条指令,从而引发冒险。
3. 1 Stall¶
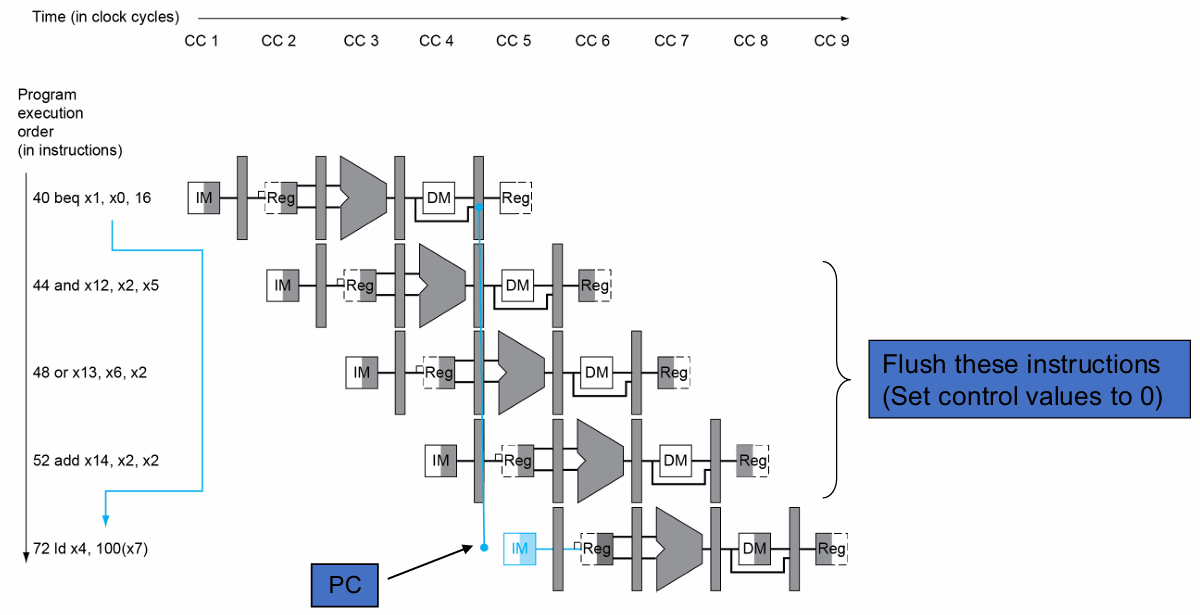
假设分支结果在 MEM 阶段确认,若直接 stall,等待分支结果确定后再取后续指令,这会造成 3 个时钟周期的浪费。
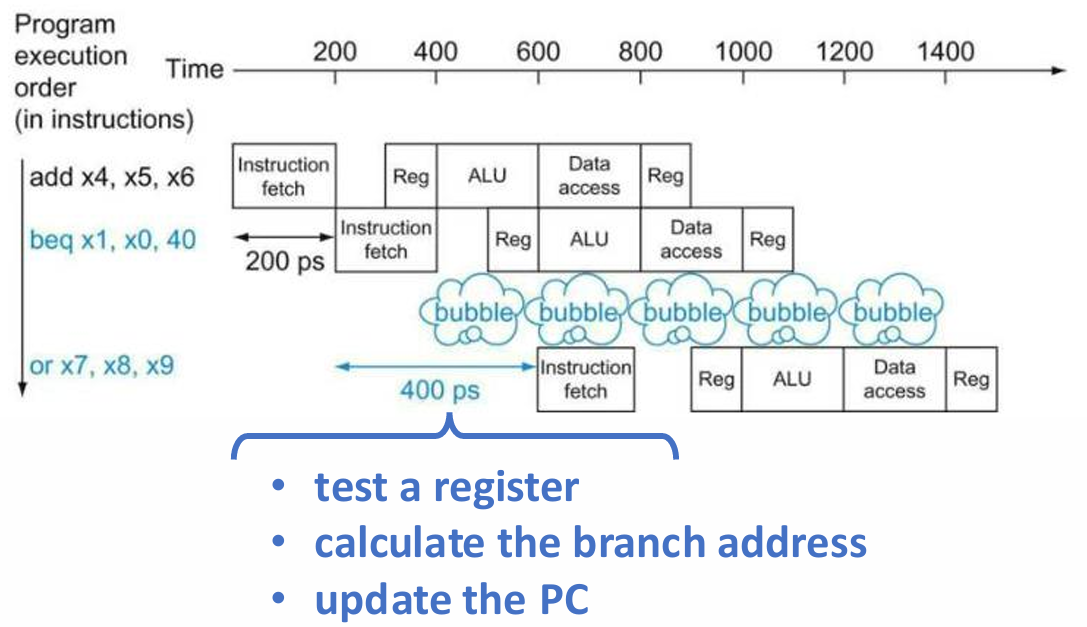
为了减少分支指令导致的流水线停顿,在 RISC-V 流水线中,需要在 ID 阶段添加硬件,提前对分支指令进行判断:
- 目标地址加法器(Target address adder):用于计算分支的目标地址(如 PC 值加上指令中的偏移量)
- 寄存器比较器(Register comparator):用于比较两个寄存器的值,从而判断分支条件是否满足
但是硬件依然需一定的操作时间,流水线依然需要等待这些操作完成才能确定下一条指令,这说明硬件优化虽然能缓解停顿,但无法完全消除停顿。
3. 2 Prediction¶
| 类别 | 定义 | 示例 |
|---|---|---|
| Simple Prediction | 总是预测条件分支不发生跳转 |  |
| Sophisticated Prediction | 预测某些条件分支不发生跳转 | 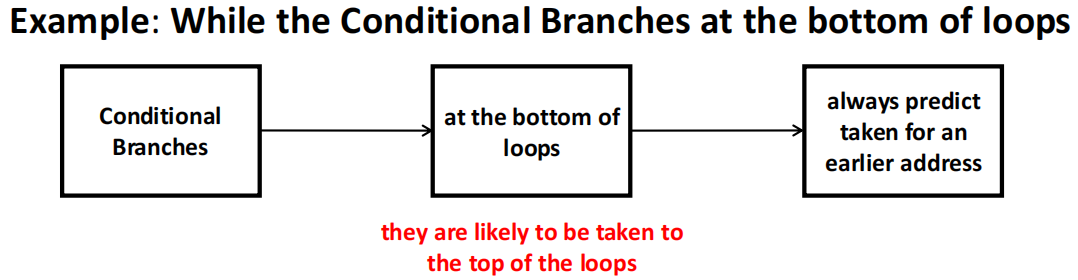 |
| Dynamic Prediction | 利用近期的历史行为来预测未来预测某些条件分支不发生跳转 | 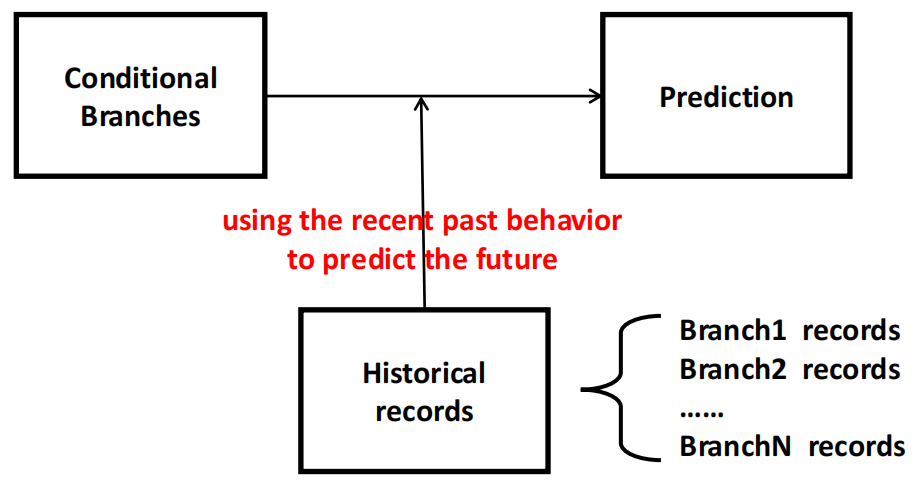 |
若流水线更长,则提前确定分支结果是困难的,stall 造成的时钟周期浪费也是无法接受的。
通过提前预测分支的结果让流水线继续并行执行后续指令,只有当预测错误时才插入 stall 来刷新错误指令流,这样在预测正确的情况下流水线就无需 stall,能够大幅减少因等待分支结果导致的性能损失。
在 RISC-V 流水线中,我们采用 分支不发生跳转 的预测策略,流水线会无延迟地按顺序执行的逻辑取指,只有当预测错误时才会触发 stall,纠正指令流。
3. 3 Delayed Decision¶
在延迟分支指令之后,立即放置一条 不受分支结果影响 的指令
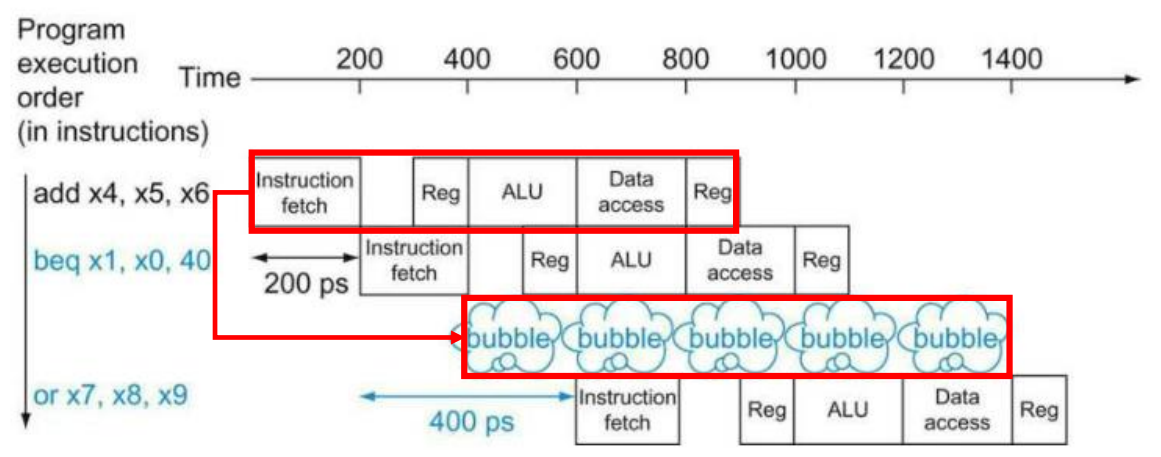
无论分支是否发生,分支延迟槽中的指令(Delay slot i+1)一定会被执行,通过在流水线等待分支结果的同时执行无关指令,有效避免流水线空转,减少 bubble 带来的性能浪费
3. 4 Reducing Branch Delay¶
根据以上,分支指令的结果判断提前到了 ID 阶段,故有数据冒险情况如下:
| 比较寄存器的依赖场景 | 停顿周期 | 示意图 |
|---|---|---|
| 依赖前 2/3 条 ALU 指令的结果(可通过 Forward 解决) | 0 | 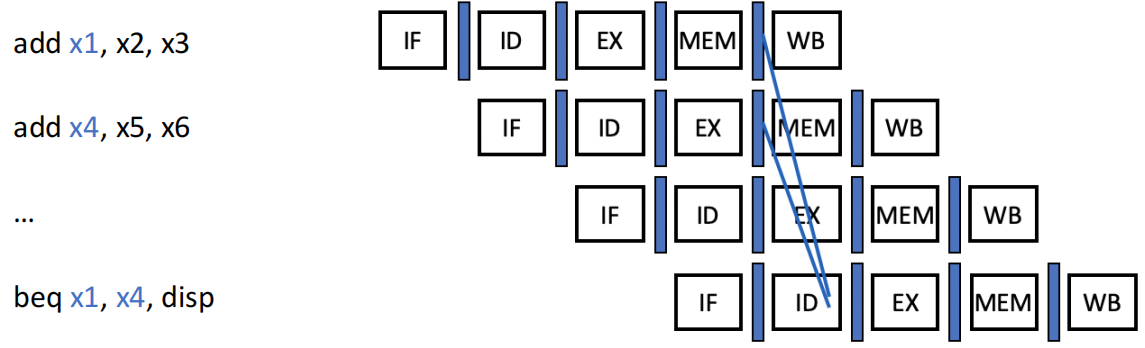 |
| 依赖前 1 条 ALU 指令或前 2 条 load 指令的结果 | 1 | 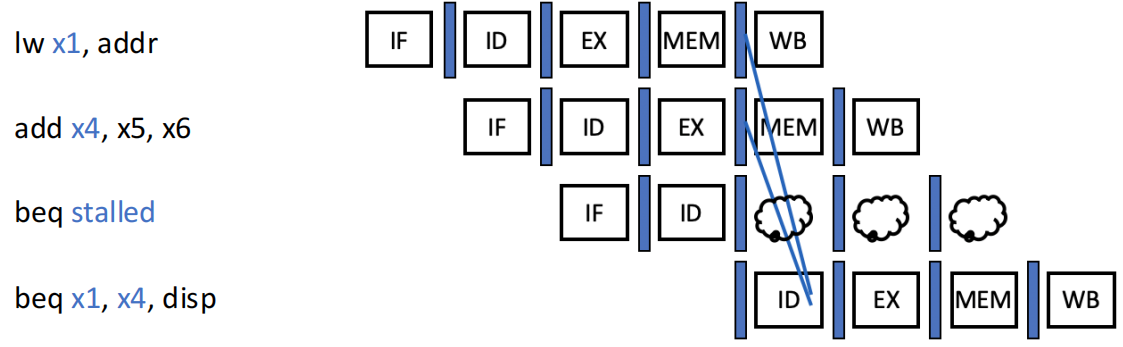 |
| 依赖紧接的前 1 条 load 指令的结果 | 2 | 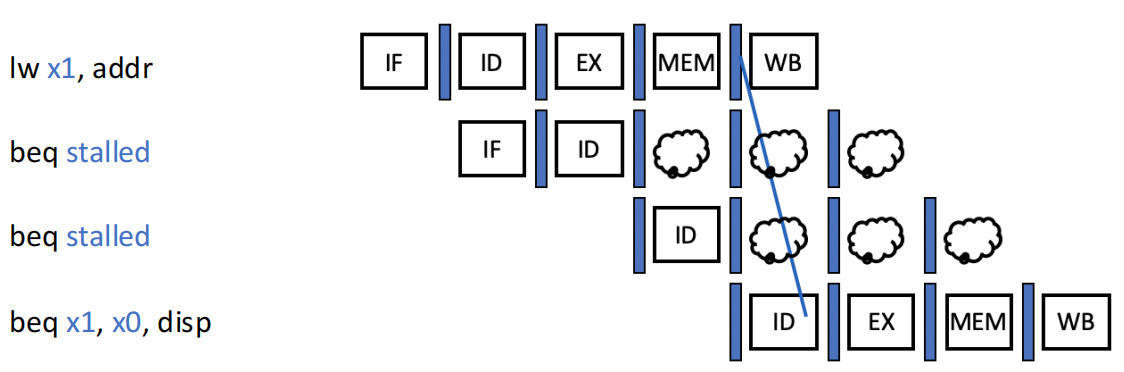 |
在更深的流水线和超标量流水线中,分支惩罚更为显著,我们通常采用动态预测。
outer: ... (外层循环起始处)
inner: ... (内层循环起始处)
beq ..., ..., inner (若条件满足则跳回内层循环)
...
beq ..., ..., outer (若条件满足则跳回外层循环)
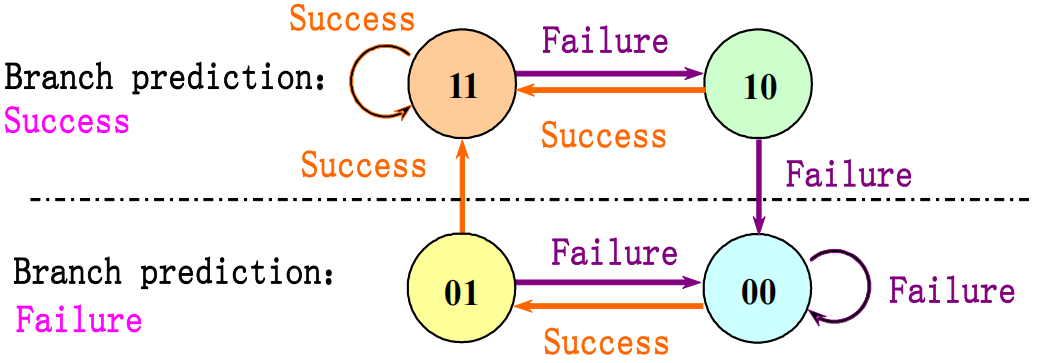
对于上面这段代码,若使用 1-bit Predictor,则内层循环的分支会被错误预测两次;若换用 2-bit predictor,则内层循环的分支仅被错误预测一次,故我们通常使用的 分支历史表(Branch History Table) 如下:
3. 5 分支目标缓冲区(Branch-Target Buffers, BTB)¶
即使有预测器,仍然需要计算目标地址,发生分支(分支被执行)时会有1个周期的代价,因从我们引入分支目标缓冲区(Branch-Target Buffers, BTB)
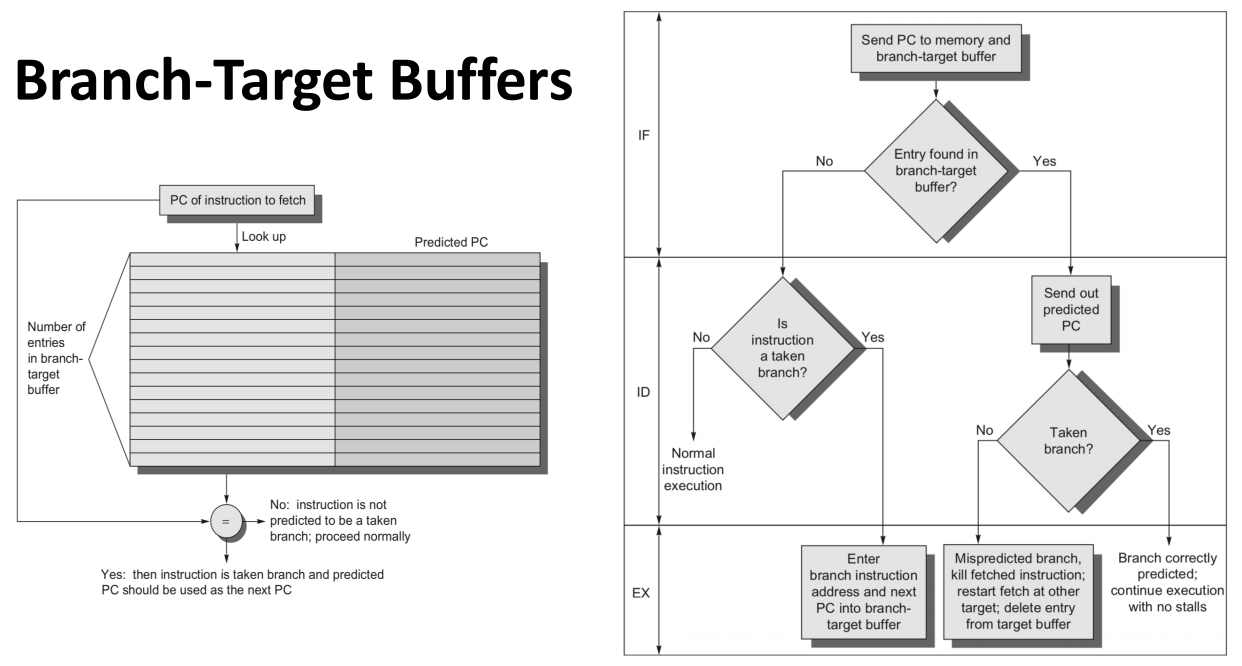
- 能够更快获取分支目标处的指令
- 可以一次性提供分支目标处的多条指令,对多处理器场景来说是必要的
- 有可能实现无延迟的无条件分支,或者有时实现无延迟的条件分支
| Is instruction in BTB? | Predict | Reality | Delay cycle |
|---|---|---|---|
| Yes | Taken | Taken | 0 |
| Yes | Taken | Untaken | 2 |
| No | Taken | 2 | |
| No | Untaken | 0 |
3. 6 集成指令取指单元(Integrated Instruction Fetch Units)¶
- 专用分支预测器:预测过程返回、间接跳转和循环分支
- 集成了若干功能(集成的分支预测、指令预取和指令存储器访问与缓冲)
4 非线性流水线的调度(Scheduling of Nonlinear pipelining)¶
在非线性流水线中,我们需要确定何时向流水线引入新任务才不会与之前进入流水线的任务发生冲突,调度流程一般为冲突向量分析→状态转移图构建→循环队列调度,最终目的是为了找到使指令平均间隔最短的调度方案,最大化流水线的吞吐量,提升其性能。
Example
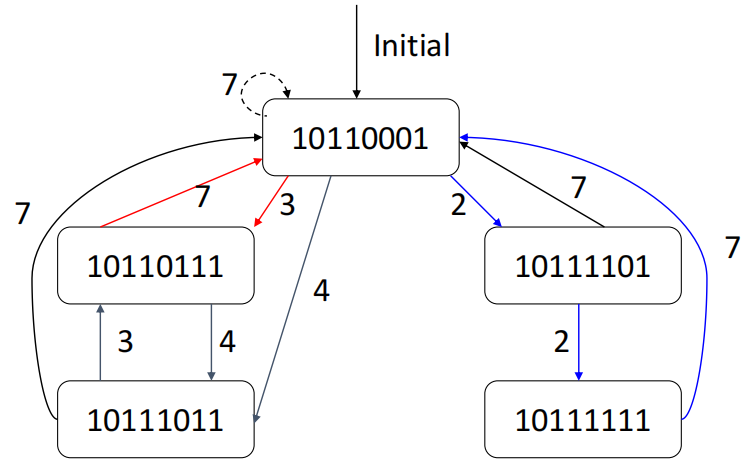
以 5 阶段非线性流水线为例,首先有初始冲突向量(Initial conflict vector)\(C0=(10110001)\),令 CCV = Current Conflict Vector
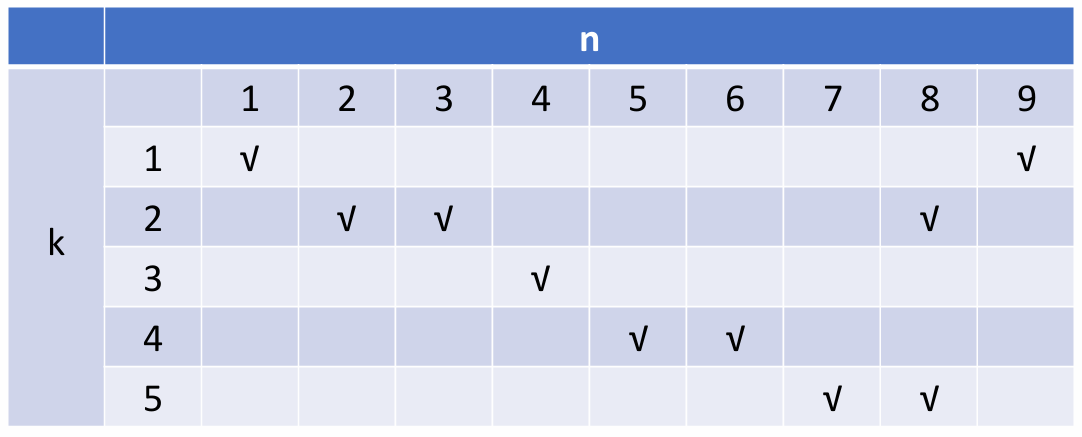
接下来尝试进行调度,下面给出两种示例:
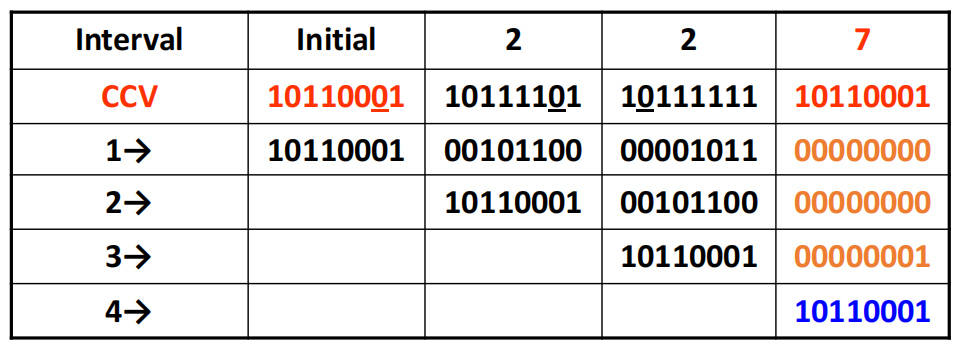
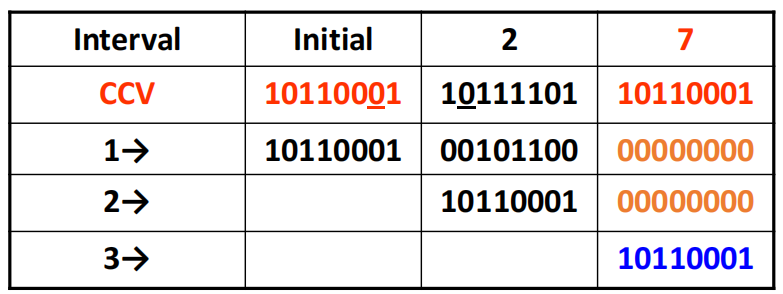
接下来作出状态转移图(State transition graph):
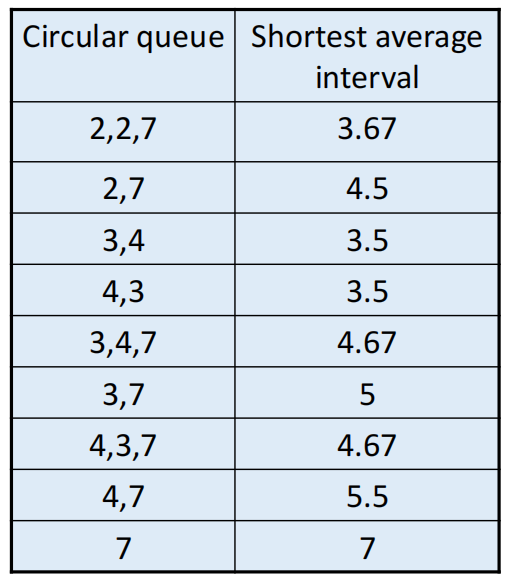
最后进行最短平均间隔分析:
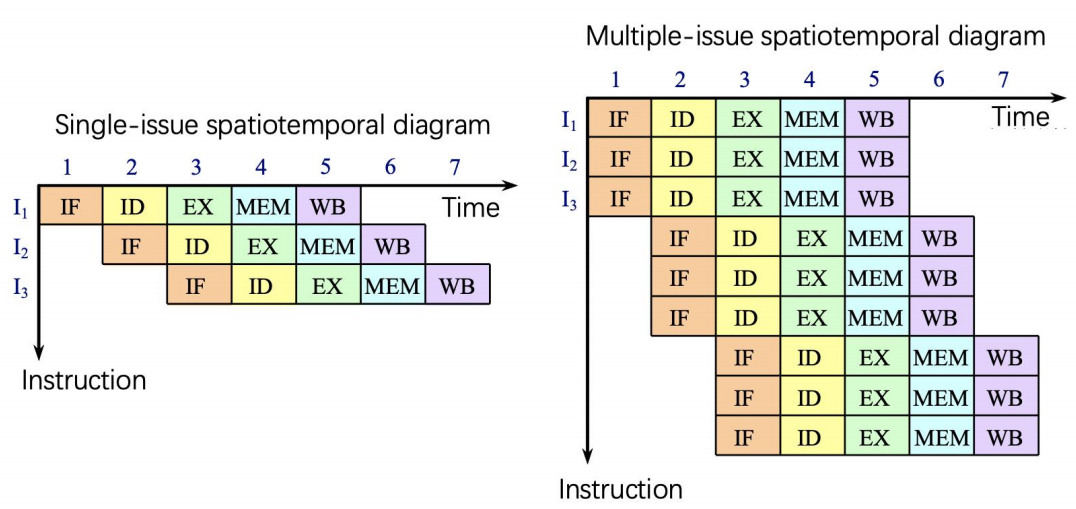
5 多发射(Multiple Issue)¶
为了提升指令级并行(ILP, Instruction-Level Parallelism),除了采用更深的流水线,减少每级的工作量从而缩短时钟周期外,还可以采用多发射。
多发射指的是复制流水线级形成多条流水线,每个时钟周期启动多条指令,由于 \(\text{CPI}<1\),所以我们通常使用 每周期指令数(IPC) 作为衡量标准。
5. 1 发射结构¶
| 类型 | 静态多发射(Static multiple issue) | 动态多发射(Dynamic multiple issue) |
|---|---|---|
| 概念 | \(\textbf{·}\) 编译器 (Compiler) 将待发射的指令分组并打包到 发射槽 (issue slots) \(\textbf{·}\) 使用编译器检测并避免冒险 |
\(\textbf{·}\) CPU 检查指令流并在每个周期选择要发射的指令 \(\textbf{·}\) 编译器可通过重排指令提供帮助 \(\textbf{·}\) CPU 在运行时使用高级技术解决冒险 |
5. 2 Speculation¶
| 类型 | 编译器推测 | 硬件推测 |
|---|---|---|
| 概念 | \(\textbf{·}\) 可以对指令重新排序,如将加载操作移到分支之前 \(\textbf{·}\) 可以包含修正指令,从而从错误猜测中恢复 |
\(\textbf{·}\) 可以预取待执行的指令 \(\textbf{·}\) 缓冲结果直到确定其被实际需要 \(\textbf{·}\) 在推测错误时清空缓冲区 |
5. 3 多发射处理器(multiple-issue processor)¶
5. 3. 1 超标量(Superscalar)¶
- 每个时钟周期发射的指令数不固定,取决于代码的具体情况(1-8条,存在上限)
- 假设上限为 \(n\),则该处理器称为 \(n\) 发射处理器
- 可以通过编译器进行静态调度,也可以基于 Tomasulo 算法进行动态调度
- 是目前通用计算中最成功的方法
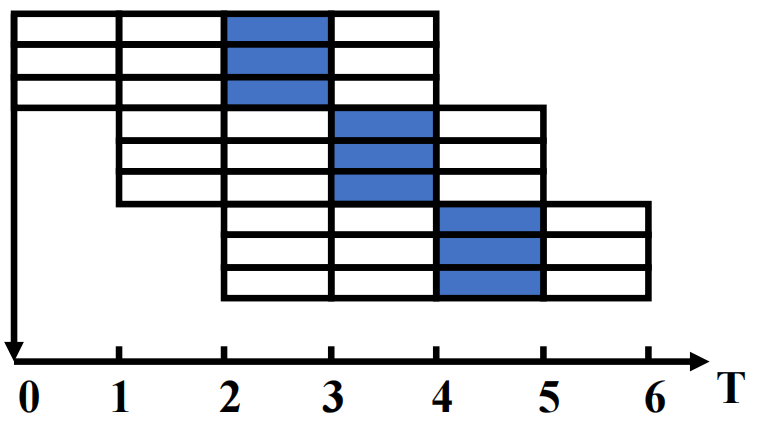
- 超标量结构对程序员完全透明:处理器自动检测指令是否可流出,无需手动重排指令
- 兼容性:未针对超标量优化的代码或旧编译器生成的代码仍然可以运行,但性能表现差
- 性能优化手段:采用动态超标量调度技术提升执行效率
5. 3. 2 超长指令字(VLIW, Very Long Instruction Word)¶
- 每个时钟周期发射的指令数是 固定 的(4-16条),这些指令构成一条长指令或一个 指令包(instruction packet)
- 在指令包中,指令之间的并行性通过指令显式表达
- 指令调度由编译器 静态 完成
- 应用于数字信号处理和多媒体应用领域
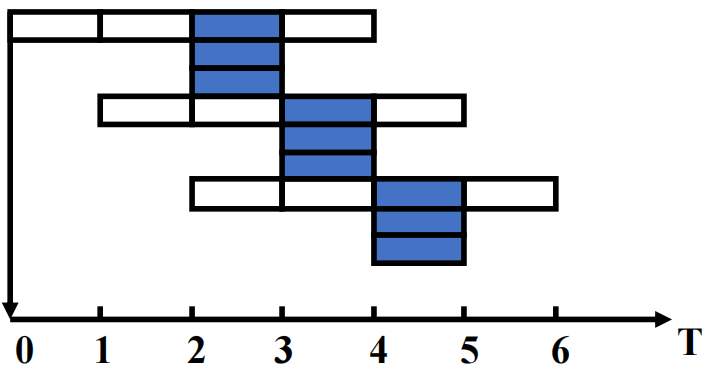
5. 3. 3 超级流水线(Super-Pipeline)¶
- 每个流水线阶段被进一步细分
- 多条指令可在一个时钟周期内分时共享
- 对于每时钟周期可流出 \(n\) 条指令的超级流水线计算机,这 \(n\) 条指令并非同时流出,而是每 \(1/n\) 个时钟周期流出一条指令,其流水线周期实际为 \(1/n\) 个时钟周期
| 通用名称 | 发射结构 | 冒险检测 | 调度 | 区分特征 |
|---|---|---|---|---|
| 超标量(静态) | 动态 | 硬件 | 静态 | 按序执行 |
| 超标量(动态) | 动态 | 硬件 | 动态 | 部分乱序执行,但无推测 |
| 超标量(推测型) | 动态 | 硬件 | 带推测的动态 | 带推测的乱序执行 |
| 超长指令字/长指令字(VLIW/LIW) | 静态 | 主要靠软件 | 静态 | 所有冒险由编译器确定并指示(通常为隐式) |
| 显式并行指令计算(EPIC) | 主要为静态 | 主要靠软件 | 主要为静态 | 所有冒险由编译器显式确定并指示 |