Chapter 3 Memory Hierarchy¶
1 Introduction¶
存储技术与存储层次
- Mechanical memory
- Acoustic wave / torque wave delay line memory
- Magnetic Drum Memory
- Magnetic core memory
- Electronic memory
SRAMDRAMSDRAM
FlashROMPROMEPROM
- Optical memory
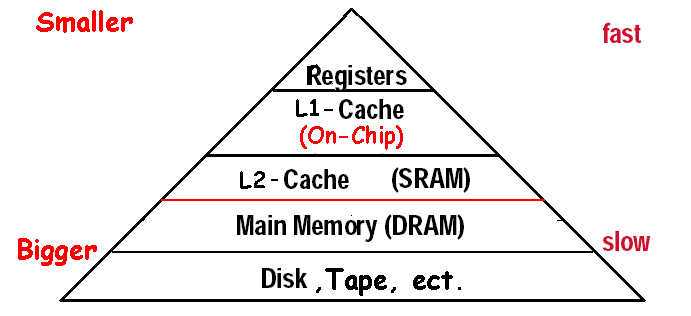
在计算机系统视角下,存储层次从近到远通常包括:
RegisterCacheMemoryStorage
局部性原理(Principle of Locality)
-
Temporal locality(时间局部性):若某个数据项刚被访问,那么它很快还会被再次访问。
-
Spatial locality(空间局部性):若某个数据项被访问,那么地址邻近的数据项也很可能很快被访问。
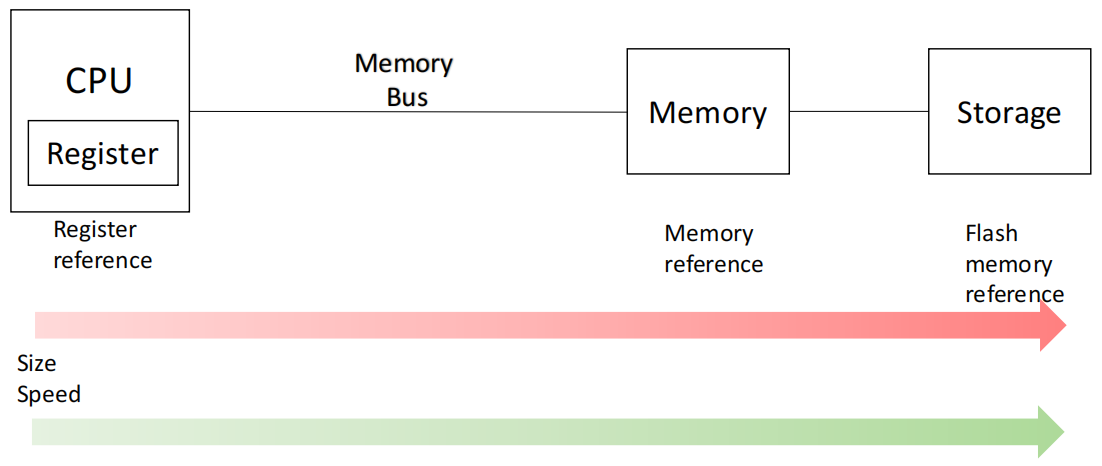
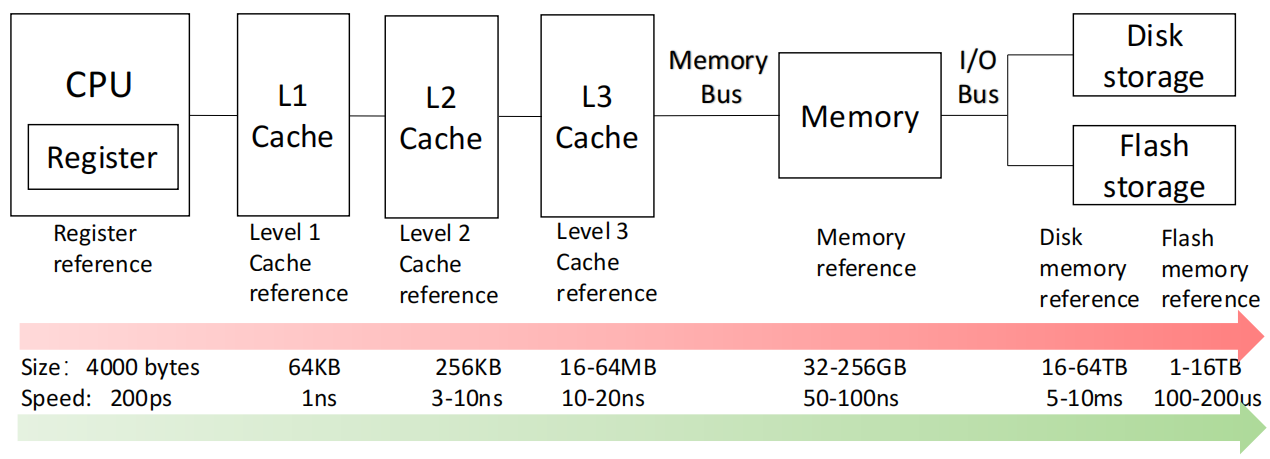
从寄存器到主存再到外存
CPU 内部首先有 Register,用于最快速的数据处理与临时保存。

仅有寄存器不够,还需要更大的 Memory 提供临时存储。

主存之外还需要更大但更慢的 Storage(如 Flash / Disk)保存长期数据。
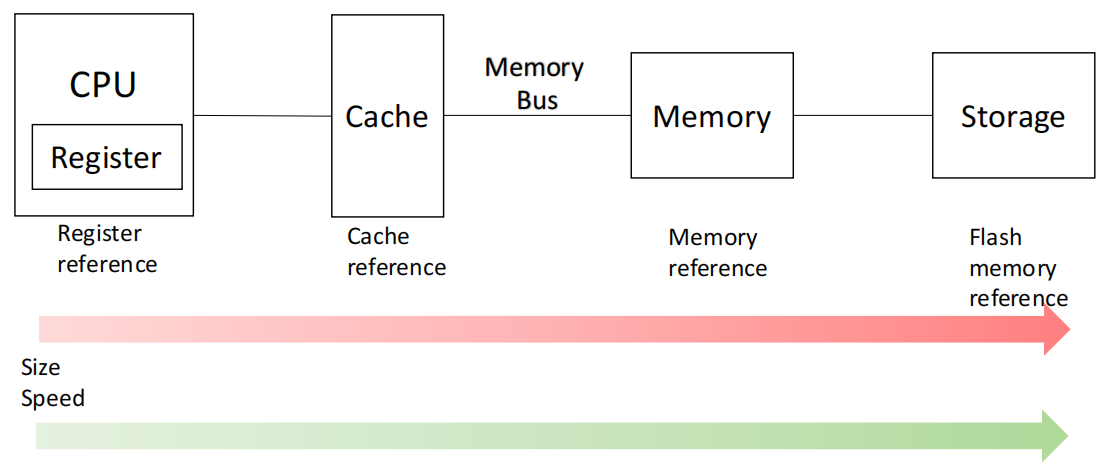
为了弥补 CPU 与主存之间的速度差距,在二者之间插入更快的 Cache。
Memory hierarchy for a personal mobile device
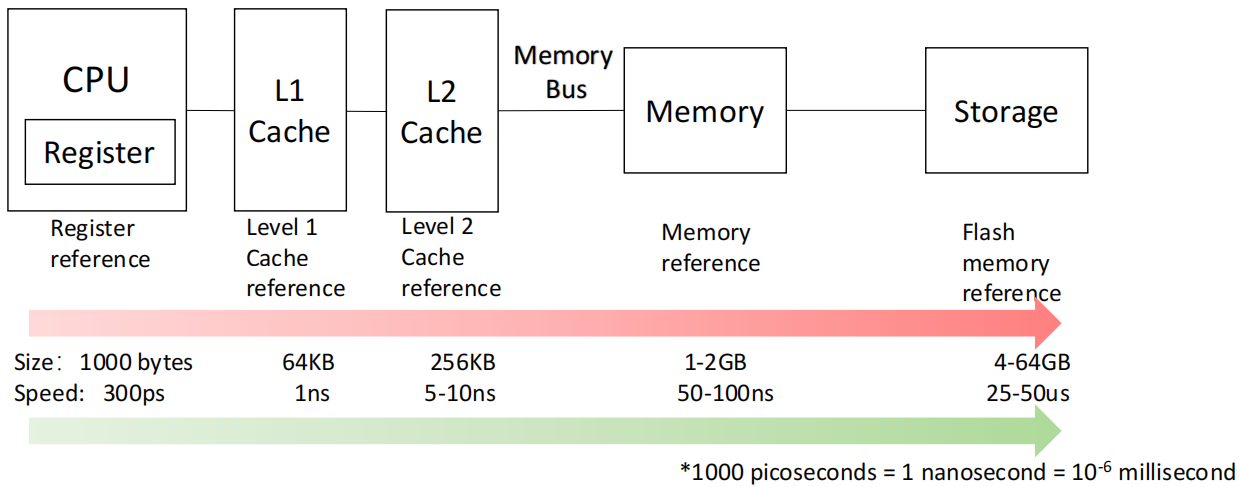
越靠近 CPU,越小越快;越远离 CPU,越大越慢。
Memory hierarchy for a laptop or a desktop
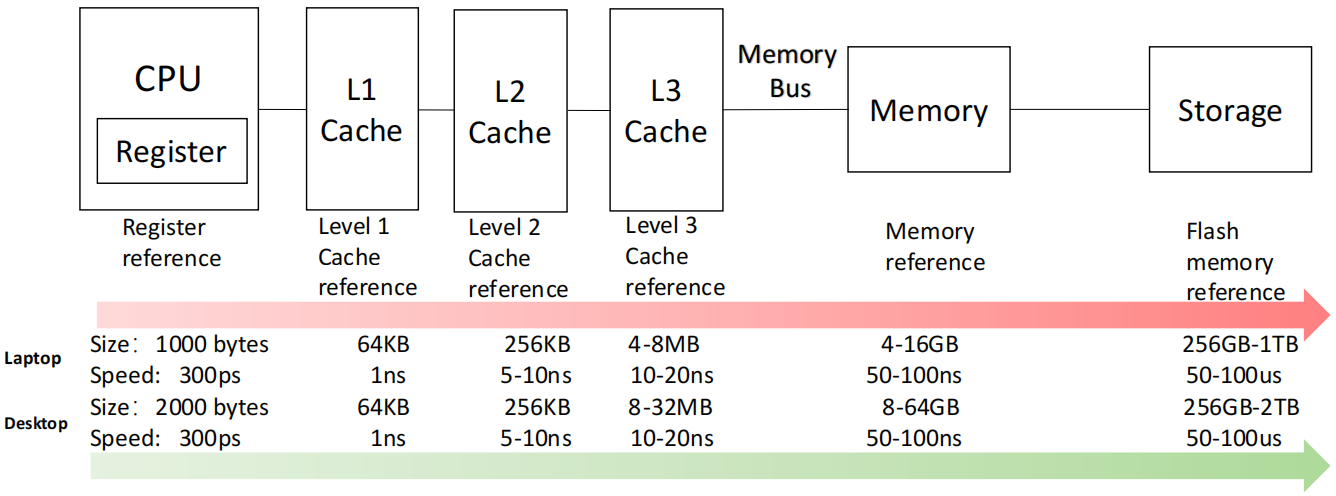
Memory hierarchy for server
对于服务器,还会引入更大规模的内存与磁盘存储:
Cache 是位于处理器和更低层存储之间的一层小而快的缓冲区,用来缓存最近或高频访问的数据 / 指令,通过重复利用常见项目来降低平均访问时间。
当处理器访问某个数据项时:
- Cache hit:在 Cache 中找到了该数据
- Cache miss:在 Cache 中没有找到该数据
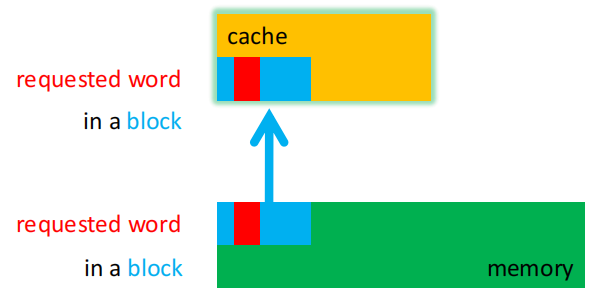
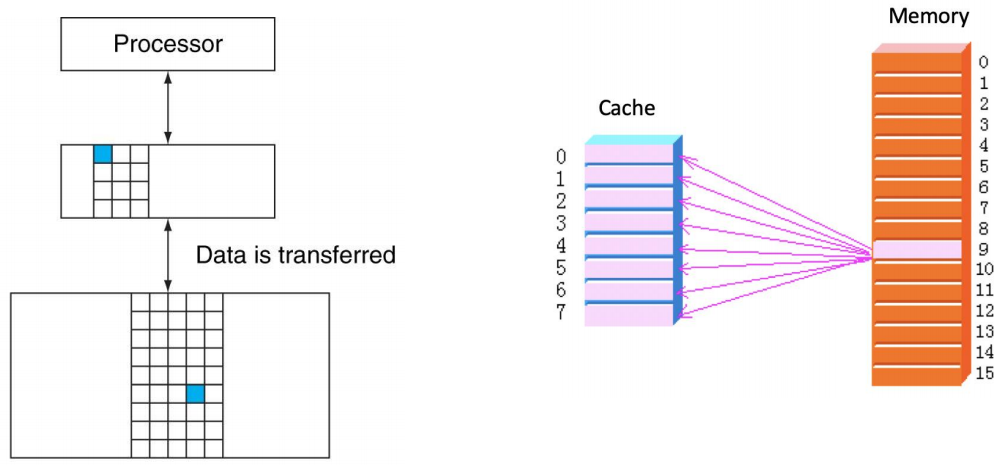
块(block / line)是一个固定大小的数据集合,包含处理器当前请求的那个字(requested word),当发生 miss 时,会把这个字所在的整个块从主存取回并放入 Cache。
Cache 和主存之间并不是按单个字交换数据,而是按块交换数据。
2 Technology Trend and Memory Hierarchy¶
处理器和内存的速度鸿沟
处理器速度增长远快于主存速度增长,因此出现明显的 processor-memory performance gap。
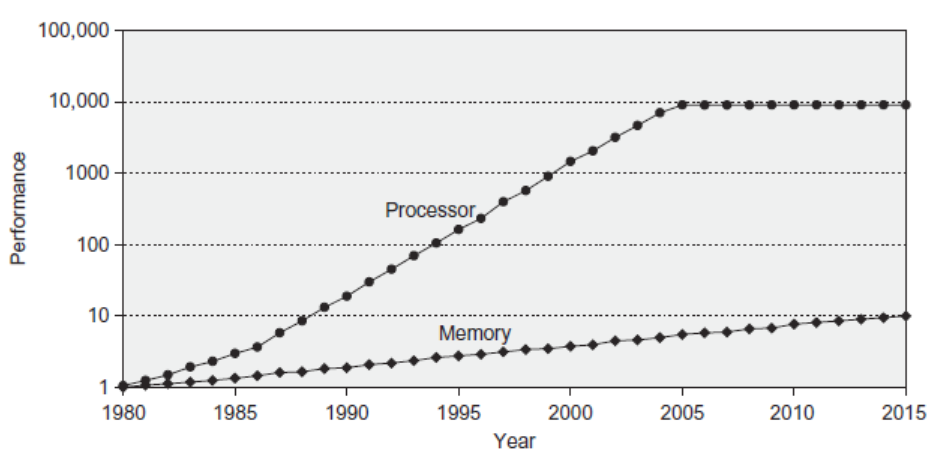
这也是引入多级 Cache 的根本原因之一:
- 不能只靠更大的主存解决问题
- 必须依赖层次结构和局部性,把常用数据尽量放在更靠近处理器的位置
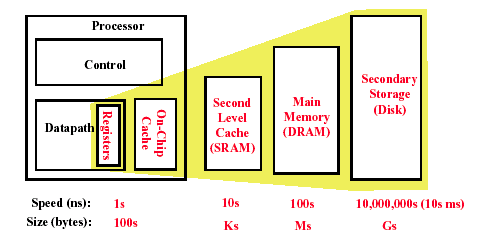
利用局部性原理,存储层次试图同时实现两件事:
- 从最便宜的技术中,向用户呈现尽可能大的可用容量
- 从最快的技术中,向用户提供尽可能快的访问速度
Cache Locality
- Temporal locality:刚访问的字很快可能还会访问,因此要把最近访问的数据留在离 CPU 更近的位置。
- Spatial locality:与当前访问地址相邻的数据很快也可能会访问,因此要把连续的一组字(一个 block)一起搬近处理器。
Cache miss 所需时间取决于两部分:
- Latency:取回这个块的第一个字所需时间
- Bandwidth:继续传回该块剩余数据所需时间
也就是说,miss penalty 不只是启动访问的代价,还包含传完整个块的代价。
Causes of Cache misses
- Compulsory miss:第一次访问某个块,之前不可能已经在 Cache 中
- Capacity miss:Cache 容量不够,某块被替换掉,后续又再次访问
- Conflict miss:程序频繁访问多个不同地址,但它们映射到 Cache 中同一位置 / 同一组,导致冲突替换
不同计算机类别对存储层次的关注点
-
桌面计算机(Desktop computers):
- 通常主要服务于单个用户,往以一个前台应用为主
- 更关注 memory hierarchy 的平均访问延迟(average latency)
-
服务器(Server computers):
- 同时面对大量用户,并发运行很多应用
- 更关注内存带宽(memory bandwidth)
-
嵌入式系统(Embedded computers):
- 常见于实时应用(real-time applications),更关注最坏情况性能而不只是平均性能
- 更关注功耗和电池寿命
- 常运行单一应用,操作系统较简单,存储层次中的“保护”作用往往被削弱
- 主存通常很小,很多场景甚至没有磁盘存储
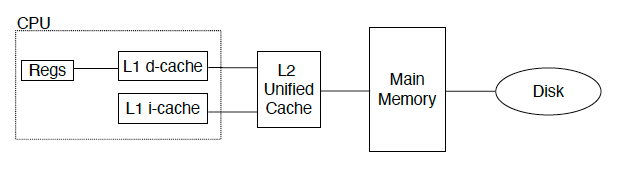
36 terms of Cache

在计算机体系结构里,几乎一切都可以被看成 cache
Registers是变量的 cache,由软件管理L1 cache是L2 cache的 cacheL2 cache是主存的 cacheMemory是磁盘的 cache(虚拟存储的角度)TLB是页表的 cache- 分支预测结构也可被理解为某种预测信息缓存
多级 Cache 让最常访问的数据停留在最上层,使得容量、成本、延迟在不同层之间平衡。
| Unified Cache | Split I&D Cache | |
|---|---|---|
| 核心设计 | 指令与数据共用同一套缓存 | 指令缓存(I-cache)与数据缓存(D-cache)相互分离 |
| 硬件需求 | 所需硬件较少,资源复用率高 | 需要额外硬件资源(两套独立缓存),硬件成本更高 |
| 性能表现 | 性能较低,指令流与数据流会争用缓存资源 | 性能更高,可并行支持取指与数据访问,避免资源冲突 |
| 特殊设计 | 无特殊只读设计,缓存读写逻辑统一 | I-cache 为只读,简化了缓存一致性与写控制逻辑 |
| 示意图 | 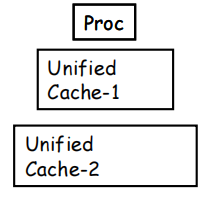 |
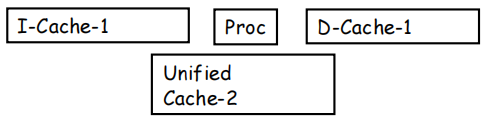 |
Intel Pentium cache organization

示例:Memory Access without/with Cache
以 lw t0, 0(t1) 为例,若 t1 = 1022 且 Memory[1022] = 99,则:
- Memory Access without Cache:Processor 向 Memory 发出地址
1022,Memory 读取该字,把99返回给 Processor,Processor 将99写入寄存器t0。 - Memory Access with Cache:Processor 先把地址发给 Cache,Cache 检查是否含有该地址的副本
- 若命中:直接把数据返回给处理器
- 若未命中:Cache 再把地址发往主存,主存返回数据给 Cache,Cache 更新 / 替换对应块,再把数据返回给处理器
读内存时会出现三种情况:
- Cache hit:该块有效且地址匹配,直接读
- Cache miss:对应位置没有数据,需要从内存取回
- Cache miss with block replacement:对应位置有数据但不是想要的数据,需要丢弃旧块,取回新块(Cache 始终是 lower level memory 的副本)。
3 Four Questions for Cache Designers¶
四个核心设计问题
Where can a block be placed?
Direct mapped / Set associative / Fully associative
How is a block found if it is in the cache?
Tag / Block / Valid bit
Which block should be replaced on a miss?
Random / LRU / FIFO
What happens on a write?
Write back / Write through (常配 Write buffer)
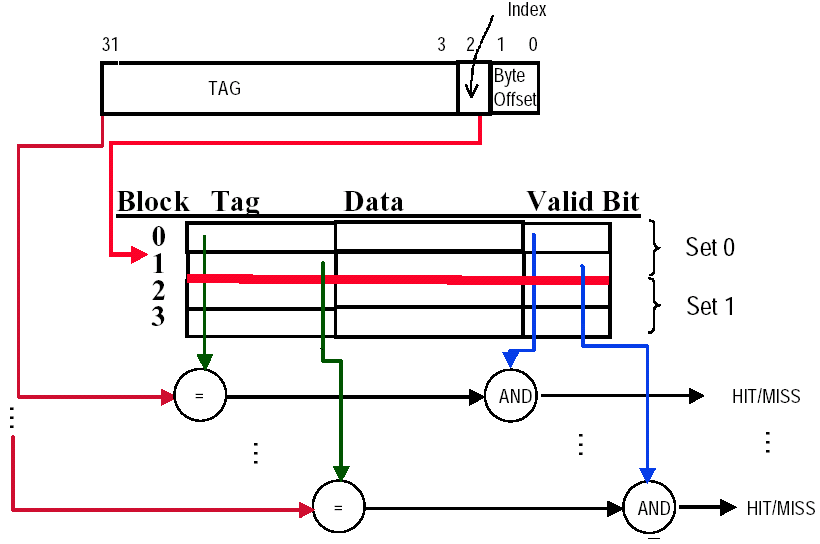
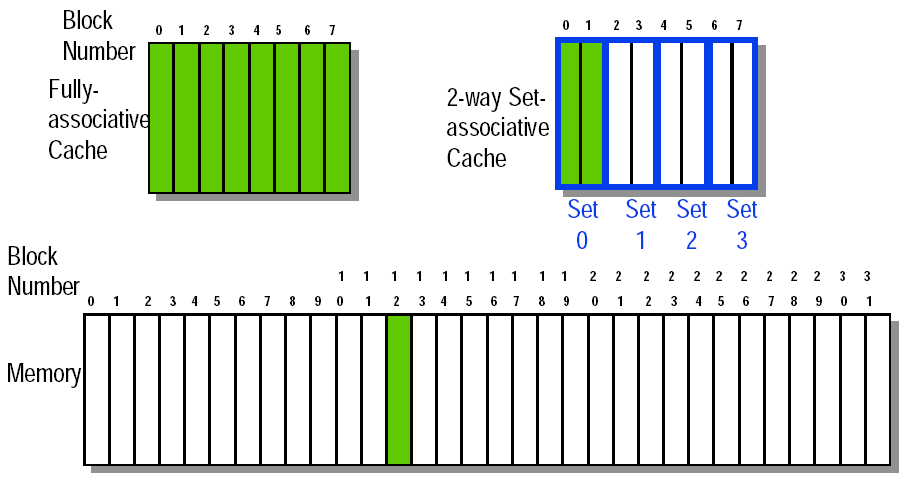
3. 1 Block Placement¶
- 直接映射(direct mapped):每个主存块只能映射到 Cache 中唯一一个位置,结构简单、命中判断快,但容易发生 conflict miss。
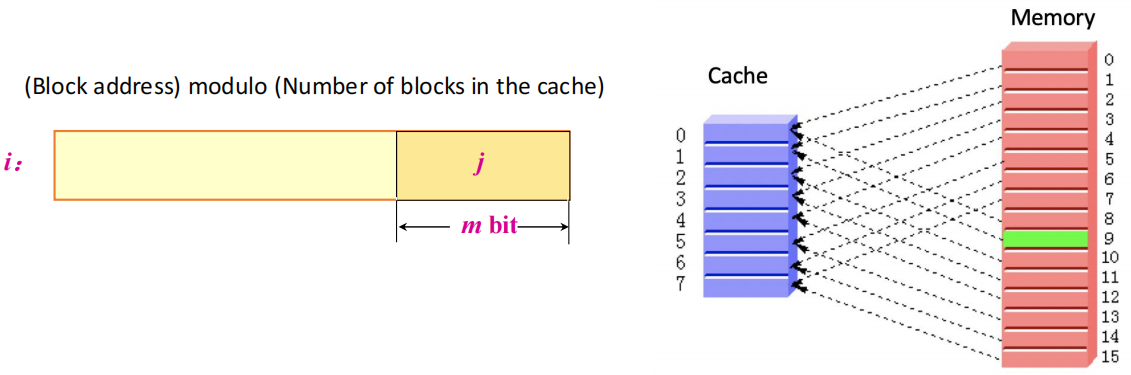
- 全相联(fully associative):一个块可以被放进 Cache 的任意位置,最灵活,冲突 miss 最少,但查找硬件代价最高。
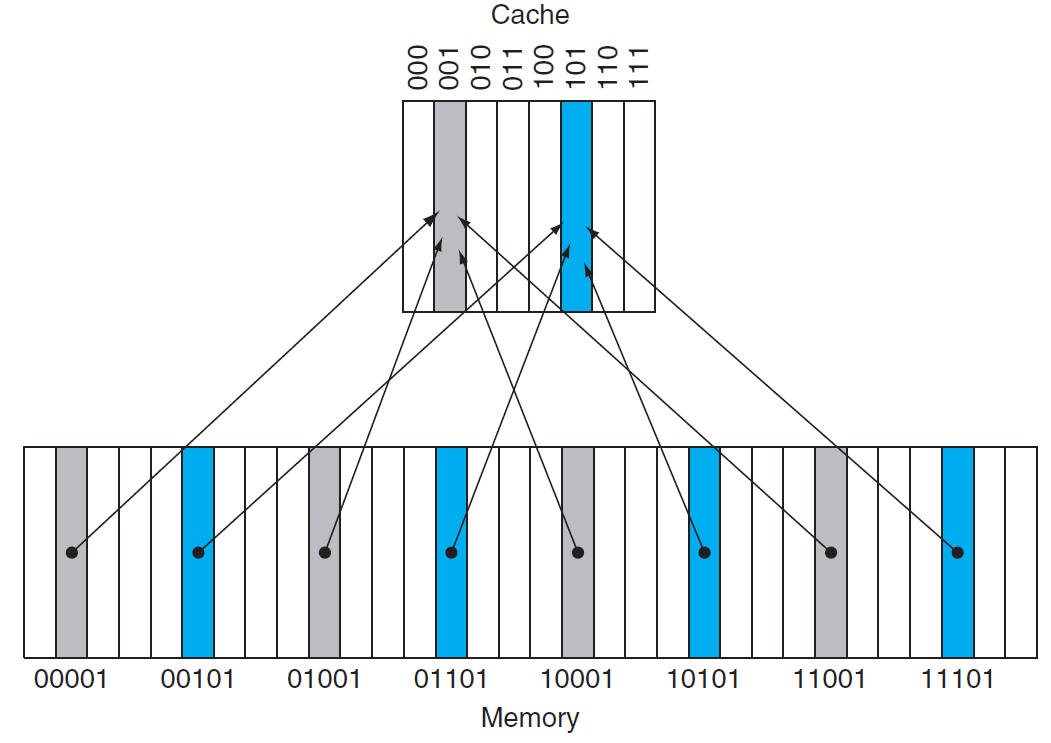
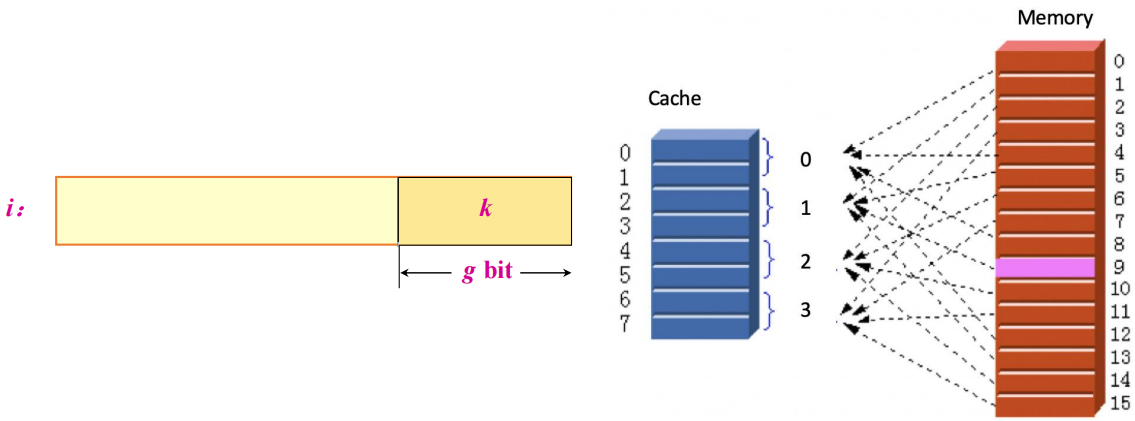
- 组相联(set associative):一个块先确定属于哪一个
set,再放入该组中的任意一个位置,若每组有n个块,则称为n-way set associative。
几个特殊关系
Direct mapped=1-way set associativeFully associative= 对一个有m个块的 Cache 来说,相当于m-way set associativeFully associative也可看作:整个 Cache 只有 1 个 set
Why Index With the Middle Bits?
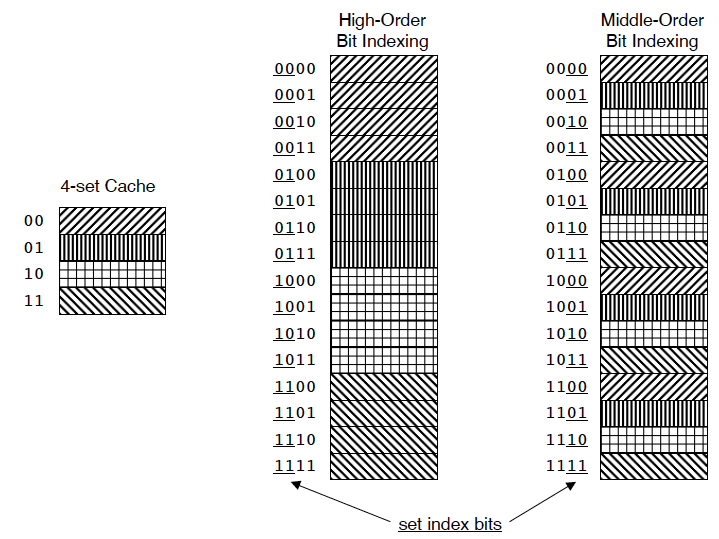
如果使用高位作为 index,连续的内存块可能映射到同一组,这样会恶化顺序访问时的冲突情况。
所以实践中通常使用低位做块内偏移,中间位做 index,高位做 tag。
相联度越高,Cache 空间利用率越高、块冲突概率越低,miss rate 越低,但也会导致比较器更多、命中路径更复杂、硬件成本和访问时间上升。
大部分 Cache 在命中率和实现复杂度之间折中,采用不高于 4 路组相联(\(n <= 4\))。
| 结构 | 每组块数 / 相联度 | 组数 |
|---|---|---|
| Full-associative | \(M\) | \(1\) |
| Direct mapped | \(1\) | \(M\) |
| Set-associative | \(1 < n < M\) | \(1 < G < M\) |
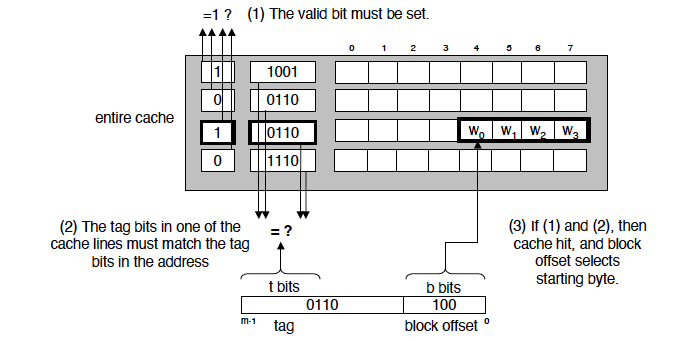
3. 2 Block Identification¶
为了判断某个块是否在 Cache 中,需要:
- Tag:记录该 Cache 块当前对应的是哪一个主存块
- Valid bit:该条目当前是否有效
判断命中时,先根据地址找到候选位置 / 候选组,若 valid = 1 且 tag 匹配,则 hit,否则 miss。

- Index field:对组相联 Cache 选择哪一个
set,对直接映射 Cache:选择哪一个block,位数为 \(\log_2(\text{#sets})\) 或 \(\log_2(\text{#blocks})\) - Byte Offset field:选择块内的具体字节,位数为 \(\log_2(\text{block size in bytes})\)
- Tag field:用于在选中的组 / 块中做地址匹配,位数为 \(\text{Tag size} = \text{Address size} - \text{Index size} - \text{Byte offset size}\)
Line Matching and Word Selection
- Direct-mapped cache:只需比较唯一候选行的 tag
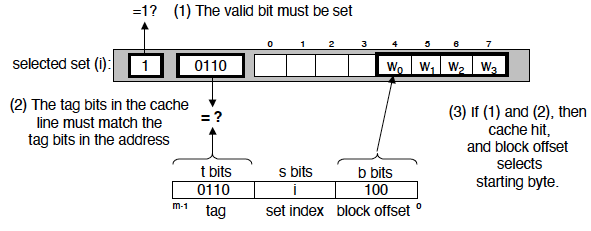
- Set-associative cache:先用 index 选组,再在组内并行比较多个 tag
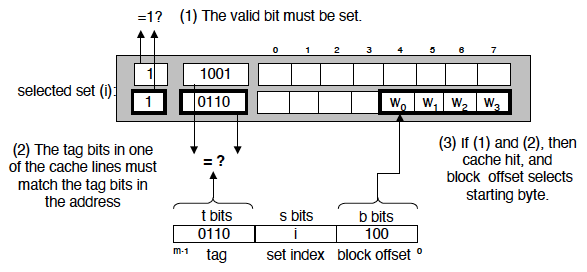
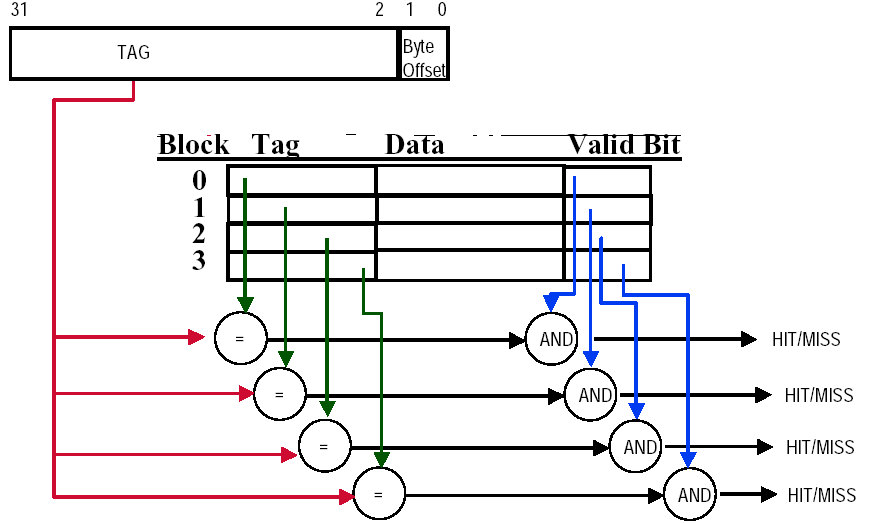
- Fully associative cache:整张 Cache 都是候选,需要做全表匹配
命中后,再通过 offset 选出块中的具体字 / 字节。
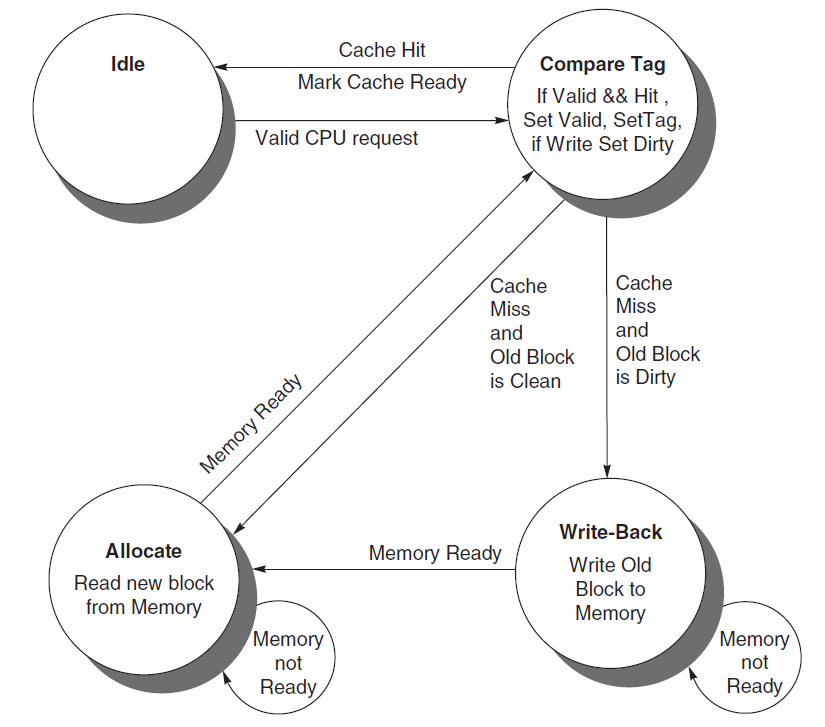
Using a Finite-State Machine to Control a Simple Cache
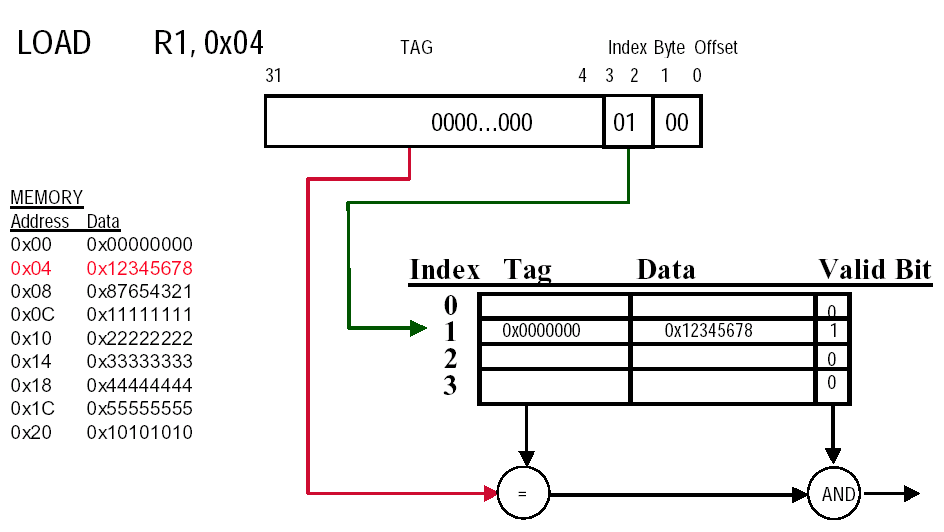
3. 3 Access data in a direct mapped cache¶
示例

先做地址划分,因为 \(16 \text{KB} = 2^{14}\ \text{bytes}\),每块 \(4\ \text{words} = 16\ \text{bytes} = 2^4\ \text{bytes}\) ,所以 Cache 块数 \(2^{14} / 2^4 = 2^{10} = 1024\),因此对于 \(32\) 位地址:
- Byte offset:
4 bits - Index:
10 bits - Tag:
32 - 10 - 4 = 18 bits
| 访问地址 | Block address | Index | Tag | Offset | 结果 |
|---|---|---|---|---|---|
0x00000014 |
1 |
1 |
0 |
4 |
初始无有效数据,miss,装入 block 1,返回 b |
0x0000001C |
1 |
1 |
0 |
12 |
同一块,valid 且 tag 匹配,hit,返回 d |
0x00000034 |
3 |
3 |
0 |
4 |
block 3 为空,miss,装入后返回 f |
0x00008014 |
2049 |
1 |
2 |
4 |
访问到 index 1,但原 tag 为 0,不匹配,miss + replacement,替换后返回 j |
直接映射实现简单,但冲突替换最明显,同一个 index 上一次只能放一个块,地址不同但 index 相同的块会发生冲突,命中判断必须同时看 valid bit、tag、offset。
Cache 总硬件位数:64-bit 地址,direct-mapped,每个 Cache 含 \(2^n\) 个块(\(n\) 位 index),每个块含 \(2^m \, \text{words}\)
- 块大小 \(= 2^m \times 4 = 2^{m+2} \, \text{bytes} = 2^{m+5} \, \text{bits}\)
- 块内偏移需要 \(m + 2\) 位,其中 \(m\) 位用于 word-in-block,\(2\) 位用于 byte-in-word
完整 Cache 总位数为:
注意区分:
- actual size:真正的数据容量
- complete cache size:包含 tag、valid 等元数据后的总硬件容量
How many total bits are required for a direct-mapped cache with 16 KiB of data and four-word blocks, assuming a 64-bit address?
- Cache 块数 \(= \frac{16 \times 2^{10}}{4 \times 4} = 2^{10}\),所以 \(n = 10\),\(m = 2\)
- data bits per block:\(4 × 4 × 8 = 128\)
- tag bits per block:\(64 - (10 + 2 + 2) = 50\)
- valid bits per block:\(1\)
完整 Cache 总位数:
可以看到,硬件实际占用会大于纯数据容量,因为还需要 tag 和 valid 等附加位。
Consider a cache with 64 blocks and a block size of 16 bytes. To what block number does byte address 1200 map?
若 Cache 有 64 blocks,块大小为 16 bytes,问:byte address = 1200 映射到哪个 Cache block?
- Block address:\(1200 / 16 = 75\)
- Cache block number:\(75 \bmod 64 = 11\)
所以该地址映射到 Cache block 11,且这一块覆盖的字节地址范围是 1200 ~ 1215
3. 4 Block Replacement¶
对于 direct-mapped cache,发生 miss 时其实没有选择空间,因为该主存块只能放到唯一位置,所以只能替换那一个块。
hit 与 miss 时处理器会发生什么
- cache hit:处理器像什么都没发生一样,直接继续执行
- cache miss:通常需要让处理器停顿(stall),冻结当前可见状态,等待 lower level memory 把数据取回
Instruction cache miss 的基本处理流程
- 将原始
PC送往主存 - 发起读请求,并等待主存完成访问
- 将返回的数据写入 Cache,同时更新对应条目的
tag并将valid bit置1 - 重新开始这条取指,这次应当会在 Cache 中命中
而在 set-associative / fully associative cache 中,一个块进入 Cache 时往往有多个候选位置,这时才需要明确的替换策略(replacement policy)。
- Random:随机选择一个候选块替换,实现最简单,只需随机数发生器,但可能恰好替换掉马上要用的数据
- LRU(Least Recently Used):替换最近最久未使用的块,利用时间局部性假设,通常比随机策略更合理,但需要额外硬件记录访问先后
- FIFO(First In, First Out):替换最早进入该组的块,实现简单,但不一定与局部性最匹配
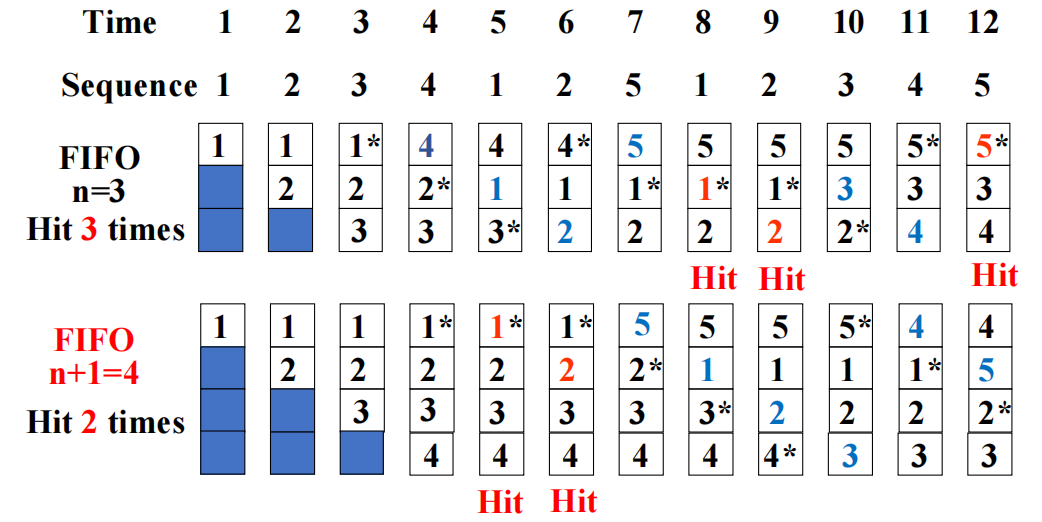
命中率与替换算法直接相关
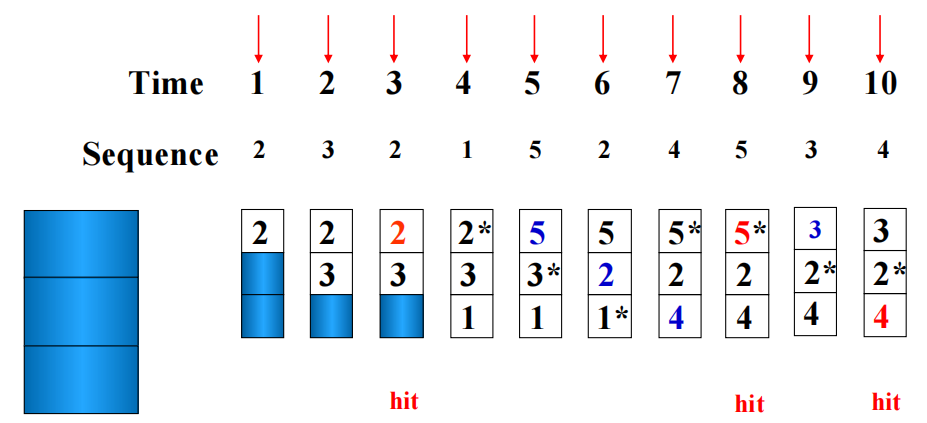
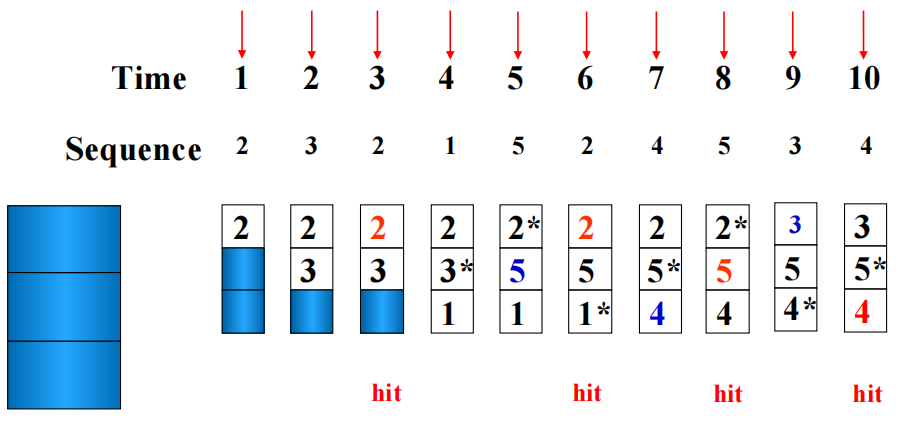
设 Cache 容量为 \(3\) blocks,访问序列为:\(2, 3, 2, 1, 5, 2, 4, 5, 3, 4\),则:
- FIFO:只看进入先后,不关心最近是否访问过,命中次数为 \(3\)
- LRU:更符合时间局部性,命中次数为 \(4\)
- OPT:理论最优策略,实际通常只用于分析比较,命中次数为 \(5\)
命中率不只由替换算法决定,还和访问序列本身、Cache 容量、块大小和相联度等因素强相关。同一个算法,在不同工作负载下效果可能差很多。
Thrashing
当程序循环访问的工作集略大于 Cache 能容纳的块数时,可能出现刚装入就被替换的情况,即 thrashing(抖动)。
例如顺序循环访问 1, 2, 3, 4, 1, 2, 3, 4,若 Cache 只能容纳 3 个块,则很容易出现每次访问都 miss 的现象;若 Cache 能容纳 4 个块,则装满之后后续访问就可以连续命中。
Stack replacement algorithm
记 \(B_t(n)\) 为时刻 \(t\)、容量为 \(n\) 的 Cache 中所包含的块集合,若某替换算法满足:
则称其为 stack replacement algorithm,直观含义是:更大的 Cache 至少应保留小 Cache 里已有的内容。
LRU 是 stack replacement algorithm
对 LRU 而言,块按照最近使用顺序排成一条栈,栈顶为最近访问,栈底为最久未访问。
当 Cache 容量从 \(n\) 增加到 \(n+1\) 时,只是把这条顺序列表向下多保留一个元素,不会把原先前 \(n\) 个块打乱。
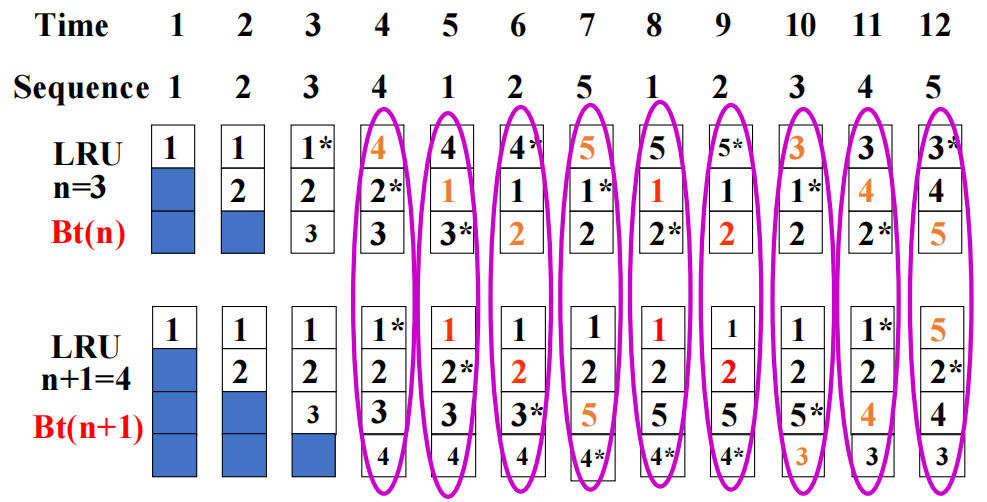
所以在 LRU 下,Cache 变大时命中率不会下降。
Belady 异常
FIFO 不是 stack replacement algorithm,因此可能出现 Belady anomaly,即:Cache 变大了,命中率反而下降。
3. 5 Hardware Implementation of LRU¶
- Comparison Pair Method(比较对方法):精确实现 LRU,对每一对 Cache block 记录谁比谁更新近,再由这些两两比较结果组合出谁最久未使用。
3 个块时的比较对表示
若有三个块 \(A\)、\(B\)、\(C\),只需记录 \(T_{AB}\)、\(T_{AC}\)、\(T_{BC}\) 三组比较关系,其中:
\(T_{AB} = 1\) 表示 \(A\) 比 \(B\) 更新近,\(T_{AB} = 0\) 表示 \(B\) 比 \(A\) 更新近,其余两个触发器同理。
根据上述定义,可写出三个块分别成为 LRU 的条件:
例如,若 \(T_{AB} = T_{AC} = T_{BC} = 1\),则说明 \(A\) 比 \(B\) 新、\(A\) 比 \(C\) 新、\(B\) 比 \(C\) 新,因此最久未访问的是 \(C\)。
- 每次访问后更新状态:
- 访问 \(A\) 后:\(T_{AB} = 1\)、\(T_{AC} = 1\)
- 访问 \(B\) 后:\(T_{AB} = 0\)、\(T_{BC} = 1\)
- 访问 \(C\) 后:\(T_{AC} = 0\)、\(T_{BC} = 0\)
若某组内有 \(p\) 个块,则需要的比较对触发器数量为:\(\binom{p}{2} = \frac{p(p-1)}{2}\),其中:
- 需要 \(p\) 个 AND 门来分别生成每个块的可替换信号
- 每个 AND 门需要接收 \(p-1\) 个输入
因此精确 LRU 的硬件复杂度大约按 \(O(p^2)\) 增长,所以现实系统里,当相联度较高时,常常不会使用完全精确的 LRU,而会采用近似 LRU 或其他更便宜的策略。
3. 6 Write Strategy¶
写策略要回答的问题是:当处理器执行写操作时,Cache 和更低层存储分别如何更新。
Write Hit:要写的块已经在 Cache 中
-
Write-through:写命中时,同时更新 Cache 和 Main Memory
- 优点:主存始终保持最新数据,一致性简单,控制位通常只需要 valid bit
- 缺点:每次写都要访问主存,带宽压力更大
- 常见场景:实时系统,更强调数据正确性和可见性
-
Write-back:写命中时,只更新 Cache,被修改的块会被标记为 dirty,只有当该块被替换出去时才把结果写回主存
- 优点:明显减少主存写流量,性能通常更好
- 缺点:实现更复杂,掉电前若还未来得及写回,主存中的数据可能不是最新
- 常见场景:通用处理器,更强调整体性能
Dirty Bit
Dirty bit(脏位) 用于记录某条 Cache line 是否“已经被修改,但还没有写回主存”。
dirty = 0:Cache 中的数据与主存一致dirty = 1:Cache 中的数据比主存更新
在 write-back 中,替换一个块之前必须先检查 dirty bit:
- 若
dirty = 1:先写回主存,再替换 - 若
dirty = 0:可以直接替换
Write miss:要写的块当前不在 Cache 中
-
Write allocate:写未命中时,先把对应块从主存调入 Cache,再在 Cache 中完成写操作
- 利用时间局部性和空间局部性
- 若之后还会继续读写该块,通常更划算
-
No-write allocate / Write around:写未命中时,直接把数据写到主存,不把该块装入 Cache
- 避免一次性写入污染 Cache
- 若该地址很少再被访问,这种方式更合适
- Write-back + Write-allocate:miss 时把块装入 Cache,后续在 Cache 内反复修改,最终替换时再统一写回,是最常见的高性能组合。
- Write-through + No-write-allocate:miss 时不装块,直接写主存,后续若又读同一地址往往还会再次 miss,是实现简单的一组组合。
Write stall 与 Write buffer
对 write-through 来说,若每次写都要等主存完成,就会产生 write stall,为了减少这种停顿,处理器常加入 write buffer:
- CPU 先把待写数据放进 write buffer
- 主存写入在后台继续完成
- CPU 不必每次都停下来等待
但 write buffer 不是万能的,若短时间内写请求过于密集或突发写入量超过 buffer 容量,仍可能重新发生停顿。
What happens if a cache block modified under the Write-Back policy is lost due to power failure before being evicted?
Data is lost, since the update existed only in the cache.
Write allocate 与 No-write allocate 的命中差异
设一个空的、全相联、write-back Cache,执行以下访存:
write Mem[100]write Mem[100]read Mem[200]write Mem[200]write Mem[100]
则:
| 访问序列 | No-write allocate | Write allocate |
|---|---|---|
write Mem[100] |
miss | miss |
write Mem[100] |
miss | hit |
read Mem[200] |
miss | miss |
write Mem[200] |
hit | hit |
write Mem[100] |
miss | hit |
这说明:若一个写入地址后面还会继续被访问,write allocate 往往更有优势。
4 CPU Vulnerabilities and Cache Security¶
背景
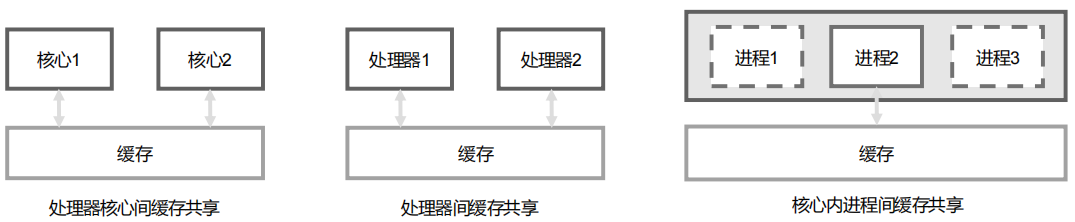
缓存(Cache) 是 CPU 与主存之间数据交互的桥梁,本身可能暂存敏感数据、密钥、内核数据,一旦被攻击,这些信息就可能泄露。
此外,Cache 往往存在共享,攻击者有机会利用共享缓存突破安全隔离边界。
4. 1 CPU 缓存缺陷分析¶
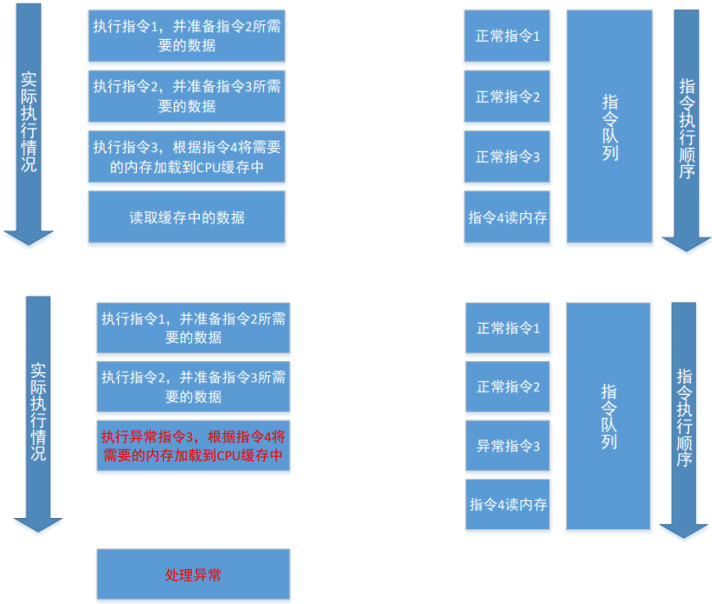
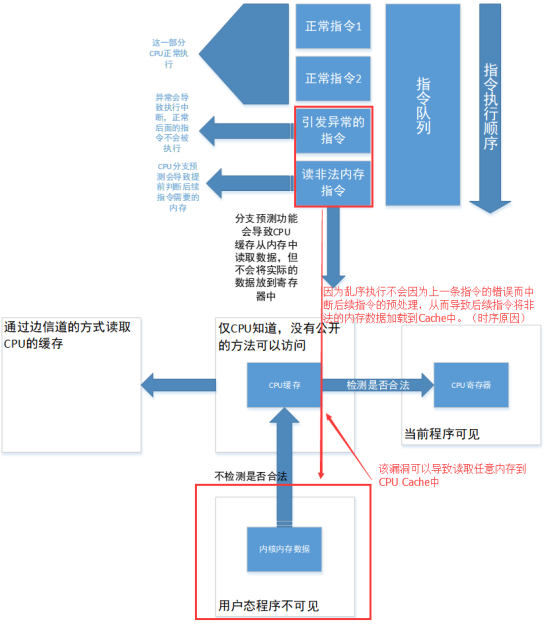
对于具备预测执行能力的处理器,某些指令访问的数据可能在合法性检查前,就已经从主存加载到 CPU Cache 中,具体来说:
- 某条后续指令所需的数据加载,不一定依赖前一条指令是否最终合法提交
- 从内存到缓存的加载过程,可能并不会验证访问的内存是否合法有效
- 即使前面的访问最终触发异常,后续访问带来的 Cache 状态改变可能已经留下
因而会出现:
- 指令在架构状态上没有真正执行成功
- 但在微架构状态上已经把敏感数据相关痕迹留在了 Cache 中
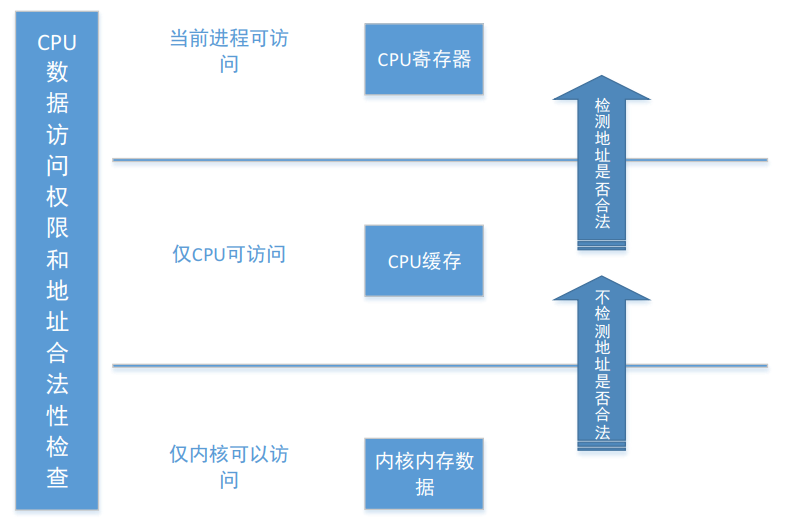
对普通用户来说,CPU Cache 过程本身是不可直接访问的;只有当数据真正进入寄存器时,用户才具备可见访问权限。
但如果攻击者能通过侧信道方法间接得知 Cache 中的数据状态,那么这种先进入 Cache、后检查权限的逻辑就会变成安全缺陷。
缓存侧信道攻击(Cache Side-Channel Attack)
多核系统为了性能通常会共享部分 Cache,缓存侧信道攻击利用 cache hit 与 cache miss 的响应时间差,去推测受害者的访存行为或泄露机密信息。
4. 2 Meltdown¶
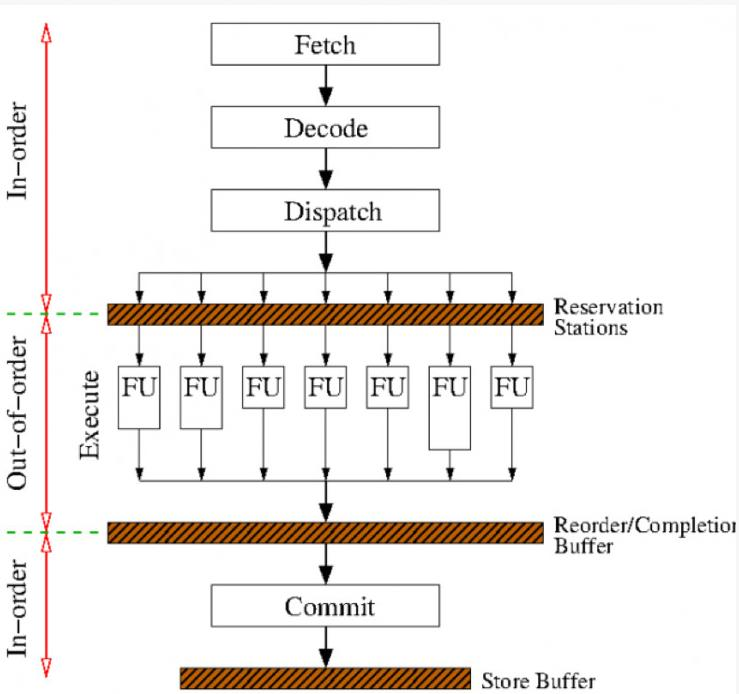
Meltdown 利用现代 CPU 的 out-of-order execution(乱序执行),打破原本由硬件保证的内存隔离,使普通用户进程能够间接读取内核内存。
Meltdown 原理
- 在支持乱序执行的 CPU 上,后面的指令可能在前面指令安全检查完成之前就被提前执行
- 指令执行顺序可以乱,但 retirement(退休 / 提交) 仍必须按序进行
- CPU 的安全检查是在 retirement 时才进行
- 因此,在某条指令完成权限检查前,后续依赖这条指令结果的操作可能已经对 Cache 产生影响
Meltdown 攻击过程
- 获取并解码指令,存入执行缓冲区 / Reservation Stations
- 乱序执行指令,结果暂存于结果序列
- 在 retirement 阶段重新排列结果并执行安全检查,再决定是否提交到寄存器
对应的漏洞利用流程可进一步概括为 4 步:
- 指令获取与解码
- 乱序执行期间,把秘密值编码到某个数组页是否进入 Cache 上
- 权限检查发现违例后,丢弃本次执行结果并恢复 CPU 架构状态,但不会恢复 Cache 状态
- 攻击者遍历探测如
rbx[al * 4096]一类地址,谁访问更快,就说明哪一页此前被带入了 Cache,从而推出秘密值
Meltdown 的缓解措施
- KAISER:一种内核修改,无需内核映射到用户空间。
- 限制:某些
x86设计仍要求在用户空间中保留少量高权限映射,因而仍可能残留攻击面。
4. 3 Spectre¶
Spectre 利用 speculative execution(推测执行) 与 BPU(Branch Prediction Unit) 的预测机制,破坏不同应用程序之间的隔离。
Spectre 原理
- 分支指令往往需要等待较长时间,CPU 会在结果真正出来前,先根据 BPU 的历史记录做预测
- 预测执行发现错误后,架构状态会被丢弃并重置
- 但和乱序执行类似,预测执行对 Cache 的影响会被保留
Spectre 攻击过程
- 训练 CPU 的 BPU,让其在运行漏洞利用代码时做出特定预测
- 让预测执行把目标地址相关内容带入 CPU Cache
- 通过缓存侧信道判断哪个数组元素被访问过,从而推测秘密数据
Spectre 的缓解措施
- 序列化指令:限制预测执行,但无法在所有 CPU 或系统配置中工作。
- 插入推测执行阻止指令:在条件分支及其目标之后插入屏障,但会严重降低性能。
- 微代码修复现有处理器:修补程序可能会阻止推测执行或阻止推测内存读取,但这会极大地破坏性能。
Meltdown 与 Spectre 对比
| 维度 | Meltdown | Spectre |
|---|---|---|
| 核心依赖 | 乱序执行 | 分支预测驱动的推测执行 |
| 破坏的隔离 | 用户空间与内核空间 | 不同应用 / 不同安全域之间 |
| 典型平台特征 | Intel 上尤为典型 | AMD / ARM / Intel 等更广泛存在 |
| 攻击难度 | 相对更直接 | 对分支预测利用更复杂,分析与攻击成本更高 |
| 缓解特点 | KPTI / KAISER 很关键 |
不能只靠 KAISER,需编译器、屏障、微码等多层手段 |
- 被广泛用于缓解 Meltdown 的 KAISER 补丁,并不能防止 Spectre 攻击。
4. 4 其他新场景下的攻击¶
-
基于硬件特性的攻击:不再只利用 Cache 的共性,还会利用查找逻辑、替换策略、预取技术、瞬态执行等硬件细节。这类攻击更依赖对微架构的深入理解,也更难被检测。
-
安全机制场景下的攻击:即使引入了可信执行环境(TEE)等机制,也可能因不同安全域共享 Cache 而继续暴露攻击面,根本原因仍在于缓存层面没有做到真正隔离。
-
性能驱动下的攻击:现实环境中常有运行窗口短、系统噪声大、预取干扰强等限制,因此攻击者还会关注攻击的速度、精度和泄露信息量。
攻击分布情况
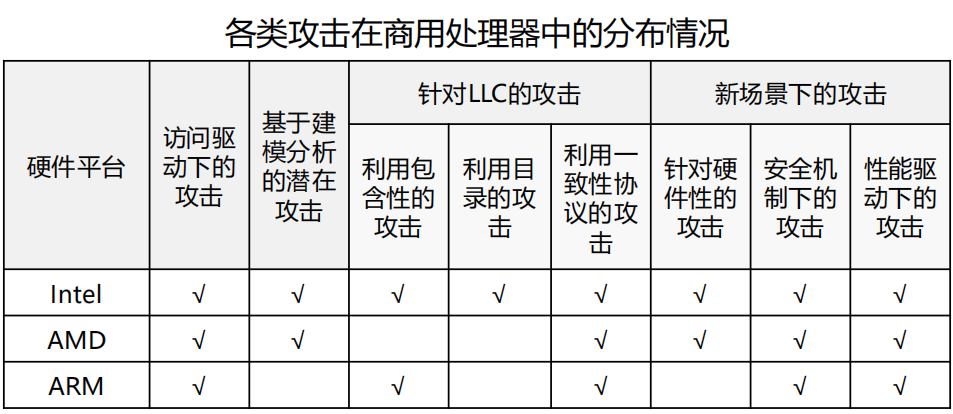
- 一些攻击利用的是 Cache 的共有性质,因此具有较强通用性
- 一些新型攻击依赖具体实现,影响范围较小,但危害依然显著
- 目前主流商用处理器都无法完全抵御缓存侧信道攻击
- Intel 处理器因性能优化而忽略较多安全考虑,暴露面更广
4. 5 Cache 安全增强¶
商用处理器 Cache 安全增强方案
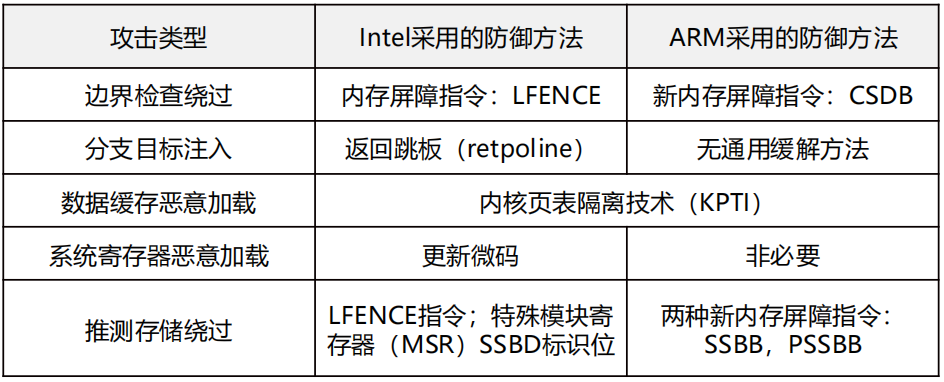
目前商用处理器主要针对已经披露的 Meltdown 与 Spectre 提供防御,而对其他类型的缓存侧信道攻击仍缺少充分通用的防御手段。
基于软件的防御机制
- 漏洞检测方法:通过静态或动态程序分析,找出程序中可能存在缓存侧信道漏洞的部分
- 用户级防御措施:如保持特定运算时间恒定、清除缓存等
- 系统级防御措施:从操作系统或虚拟机管理程序角度改进内存管理、锁定缓存行等,避免恶意探查
优点:实现灵活、易于快速部署。
缺点:一定程度依赖底层微架构实现,往往需要硬件额外支持才能降低开销。
基于硬件的防御机制
- 缓存分组(cache partitioning):
- 将 Cache 划分为不同区域分配给不同进程,真正实现隔离
- 优点:从原理上完全避免侧信道攻击
- 缺点:受硬件限制,且可能明显影响性能
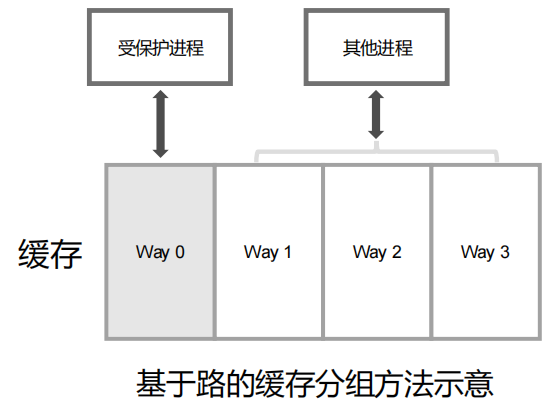
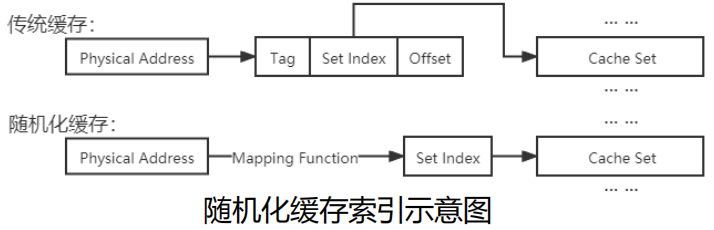
- 缓存随机化(cache randomization):
- 消除特定地址到 Cache 的固定映射,可通过基于表的映射方案或基于计算的映射方案实现
- 优点:性能开销较小,效果已有较充分验证
- 缺点:不能彻底消除攻击,但能显著缓解
其他防御思路
-
针对目录结构的防御方法:
- 从源头出发:增加目录项数量,减少冲突
- 从结果出发:检测跨核心缓存行替换,并将被替换缓存行重新加载到
L2
-
完善软件硬件协作关系:
- 重新思考软硬件协作方式,定义新的指令集体系结构
- 例如通过数据遗忘(Data Oblivious)编程消除机密信息与执行时延差异的关联
- 通过优化基本块执行,减少分支预测带来的攻击机会
5 Memory System Performance¶
5. 1 Introduction to Cache Performance¶
- 注:\(\text{CPI}_{\text{execution}}\) 中包含 ALU 指令和正常命中的访存指令本身的执行代价,真正额外拖慢系统的是 memory stall cycles。
5. 2 Basic Optimization Methods¶
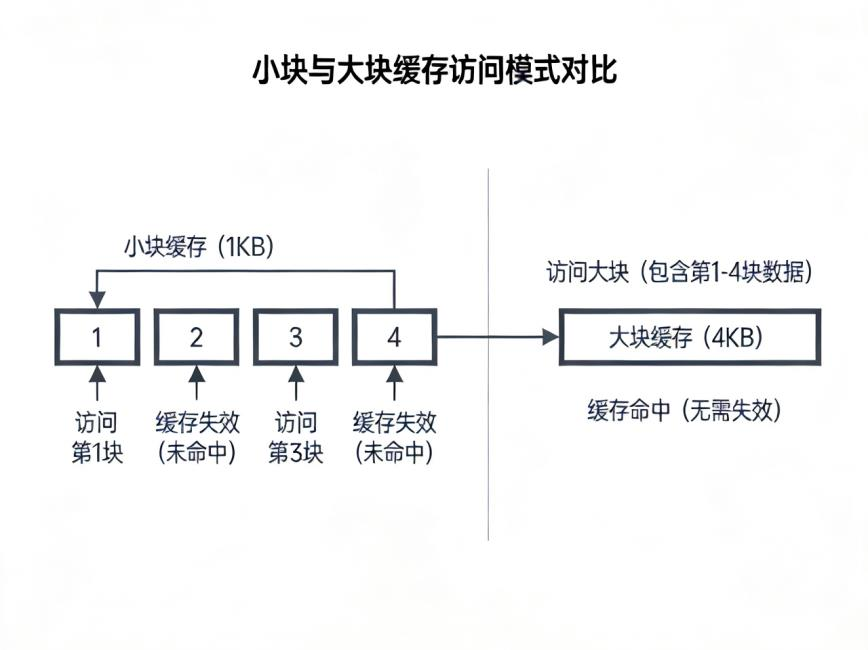
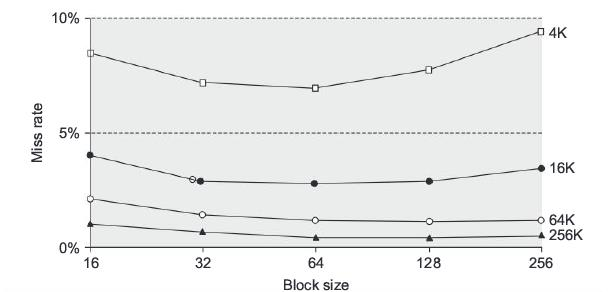
5. 2. 1 Larger Block Size to Reduce Miss Rate¶
利用空间局部性,一次加载更多连续数据,从而减少首次访问带来的 compulsory miss。
- 优点:对空间局部性强的程序能显著降低 miss rate。
- 缺点:会增大 miss penalty,更大的块也可能增加映射冲突。
- 适用场景:数组遍历、矩阵运算、其他顺序访问明显的程序
5. 2. 2 Larger Caches to Reduce Miss Rate¶
提供更大的容量容纳数据,从而减少 capacity miss 和部分 conflict miss。
- 优点:优化效果通常直观明显。
- 缺点:命中时间可能变长,硬件成本和功耗增加。
- 适用场景:处理大型数据集的应用,如数据库查询、科学计算等。
5. 2. 3 Higher Associativity to Reduce Miss Rate¶
允许主存块映射到一个组中的多个位置,而不是固定唯一位置,从而减少冲突失效。
- 优点:显著降低 conflict miss.
- 缺点:需要并行比较多个 tag,硬件复杂度上升,hit time 往往也会略微增加。
- 适用场景:数据访问模式易引发冲突失效的程序,例如数值计算、矩阵运算等科学计算类应用。
2:1 Cache Rule
大小为 \(N\) 的 direct-mapped cache 的 miss rate \(\approx\) 大小为 \(\frac{N}{2}\) 的 2-way set associative cache 的 miss rate
miss rate 不是唯一指标
提高相联度确实能有效减少 conflict miss,从而降低 miss rate,但也可能增加命中时间。
因此 miss rate 更低,不代表 AMAT 一定更小,4-way 到 8-way 往往是性能与复杂度之间较好的折中,过高相联度常常收益有限,但成本明显增加,真实系统通常采用 2-way 到 8-way。
Pseudo-Associativity
- 目标:兼顾 direct-mapped 的快 hit time 与 2-way SA 的低冲突 miss
- 方法:第一次 miss 后,再去检查 Cache 的另一半,若找到则称为 pseudo-hit(慢命中)
- 缺点:hit 可能需要 \(1\) 个或 \(2\) 个周期,不利于紧耦合 CPU 流水线
- 更适合不直接卡在处理器关键路径上的 Cache(如某些
L2)
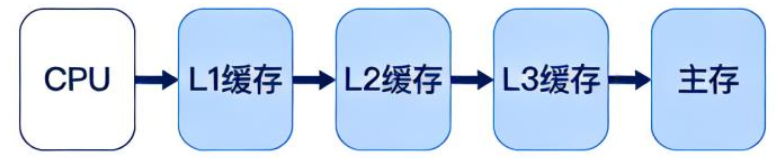
5. 2. 4 Multilevel Caches to Reduce Miss Penalty¶
在 CPU 与主存之间加入 L1 / L2 / L3 多级 Cache,当 L1 miss 时,先检查更快的 L2 / L3,尽量避免直接访问慢得多的主存。
- 优点:显著降低 miss penalty,已成为现代处理器标准配置。
- 缺点:增加硬件复杂度与制造成本。
5. 2. 5 Giving Priority to Read Misses over Writes¶
读 miss 的处理优先于写操作,从而减少 CPU 等待读数据的时间。
Read Miss Strategies
- Read Through:直接从主存把内容送给 CPU,不经过 Cache,不常用
- Read Allocate:先把数据从主存读入 Cache,再由 Cache 提供给 CPU
RAW conflict
假设 direct-mapped cache 中 512 和 1024 映射到同一块,有一个 4-word write buffer 且 read miss 不会检查 write buffer,则可能出现:主存中尚未完成写入,随后读 miss 又从主存读取旧值,导致 RAW conflict。
- 最简单方法:read miss 等到 write buffer 清空后再继续,但会明显降低 CPU 性能。
- 更好的方法:read miss 先检查 write buffer,若发生冲突则直接从 write buffer 取数据,否则继续访问主存。
Performance Analysis
- 基础时间参数
- CPU 读取/写入 Cache 的时间:\(1\) 个周期
- CPU 读取/写入 Main Memory 时间:\(100\) 个周期
- Cache 写回/读取 Main Memory 的时间:\(50\) 个周期
- CPU 读取/写入 Write Buffer 的时间:\(3\) 个周期
- Cache 写入 Write Buffer 的时间:\(5\) 个周期
- Write Buffer 写入 Main Memory 的时间:\(30\) 个周期
- 访问参数
- 读操作占比:\(70\%\)
- 写操作占比:\(30\%\)
- 发生 RAW(Read After Write) 冲突的概率:\(15\%\)(冲突时数据仍在 Write Buffer 的概率与缓冲区大小相关)
- Write Buffer Hit 率:\(70\%\)
- Read Miss 率:\(15\%\)
- Write Miss 率:\(10\%\)
- 假设 Write Buffer 始终有空位
解答
\(85\%\) 的 read miss 无冲突,无需等待写操作,执行流程为:Cache 从主存读取数据 → CPU 读取 Cache,惩罚时间为:
\(15\%\) 的 read 操作存在 RAW 冲突:
- 无优化场景:需等待引发冲突的写操作写入主存 → 从主存读取数据到 Cache → CPU 读取 Cache,惩罚时间为:
- 有优化场景(读优先 + Write Buffer):Write Buffer 异步写回主存时,待写回数据仍保留在缓冲区中,可直接从 Write Buffer 获取最新数据,无需等待写回主存,惩罚时间为:
故 read miss penalty 为:
计算写操作 Penalty:
-
Write Around 策略:
- 无优化场景:直接写入主存,惩罚时间为:
\[ \text{Penalty(without opt)} = 100\ \text{cycles} \]- 有优化场景(Write Buffer):CPU 仅需写入 Write Buffer,写回主存异步处理,惩罚时间为:
\[ \text{Penalty(with opt)} = 3\ \text{cycles} \] -
Write Allocate 策略:
- 无优化场景:从主存加载数据到 Cache → 写入 Cache → 替换时写回主存,惩罚时间为:
\[ \text{Penalty(without opt)} = 50 + 1 + 50 = 101\ \text{cycles} \]- 有优化场景(Write Buffer):替换时写入 Write Buffer,写回主存异步处理,惩罚时间为:
\[ \text{Penalty(with opt)} = 50 + 1 + 5 = 56\ \text{cycles} \]
计算整体Penalty(读写操作加权):
-
Write Around 策略:
- 无优化总 Penalty:
\[ \text{Penalty(without opt)} = 100 \times 30\% + 58.5 \times 70\% = 70.95\ \text{cycles} \]- 有优化总 Penalty:
\[ \text{Penalty(with opt)} = 3 \times 30\% + 43.8 \times 70\% = 31.56\ \text{cycles} \]- 优化倍率:
\[ opt\_rate = \frac{\frac{1}{31.56}}{\frac{1}{70.95}} = \frac{70.95}{31.56} = 2.25 \] -
Write Allocate 策略:
- 无优化总 Penalty:
\[ \text{Penalty(without opt)} = 101 \times 30\% + 58.5 \times 70\% = 71.25\ \text{cycles} \]- 有优化总 Penalty:
\[ \text{Penalty(with opt)} = 56 \times 30\% + 43.8 \times 70\% = 47.46\ \text{cycles} \]- 优化倍率:
\[ opt\_rate = \frac{\frac{1}{47.46}}{\frac{1}{71.25}} = \frac{71.25}{47.46} = 1.50 \]
计算总程序性能影响(含 Cache 命中场景):
其中:Cache 命中率 = \(1 - 15\% - 10\% = 75\%\),命中时间为 \(1\) 周期。
-
Write Around 策略:
- 无优化总时间:
\[ Total(\text{without opt}) = 58.5 \times 15\% + 70.95 \times 10\% + 1 \times 75\% = 16.62\ \text{cycles} \]- 有优化总时间:
\[ Total(\text{with opt}) = 43.8 \times 15\% + 31.56 \times 10\% + 1 \times 75\% = 10.48\ \text{cycles} \]- 优化倍率:
\[ opt\_rate = \frac{\frac{1}{10.48}}{\frac{1}{16.62}} = \frac{16.62}{10.48} = 1.59 \] -
Write Allocate 策略:
- 无优化总时间:
\[ Total(\text{without opt}) = 58.5 \times 15\% + 71.25 \times 10\% + 1 \times 75\% = 16.65\ \text{cycles} \]- 有优化总时间:
\[ Total(\text{with opt}) = 43.8 \times 15\% + 47.46 \times 10\% + 1 \times 75\% = 12.07\ \text{cycles} \]- 优化倍率:
\[ opt\_rate = \frac{\frac{1}{12.07}}{\frac{1}{16.65}} = \frac{16.65}{12.07} = 1.38 \]
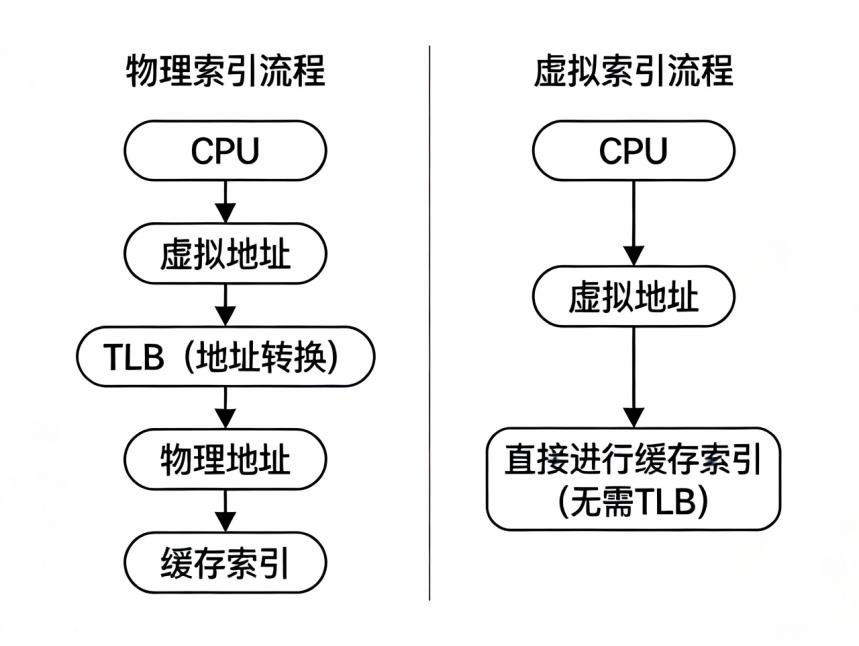
5. 2. 6 Avoiding Address Translation During Indexing of the Cache¶
使用虚地址进行 Cache 索引,而不是在关键路径上先做地址翻译后再索引。
- 优点:避开 TLB 查找带来的关键路径延迟,减小 hit time,有助于支持更高 CPU 时钟频率。
- 缺点:可能出现 cache aliasing,即多个虚地址映射到同一物理地址,因而需要额外硬件来处理别名问题。
- 适用场景:高性能处理器设计。
5. 3 Advanced Optimization Methods¶
5. 3. 1 Pipelined L1 Caches With Virtual Indexing and Set Associativity¶
将 Cache 的访问过程拆成多个流水级,让 CPU 每个周期都能发起新的访问请求,从而提升带宽。
- 优点:增加 Cache 带宽,支持更高频率。
- 缺点:单次命中延迟增加,Cache 访问不再是零额外阶段。
- 适用场景:适用于高频率、高带宽需求的现代高性能处理器架构。
例题
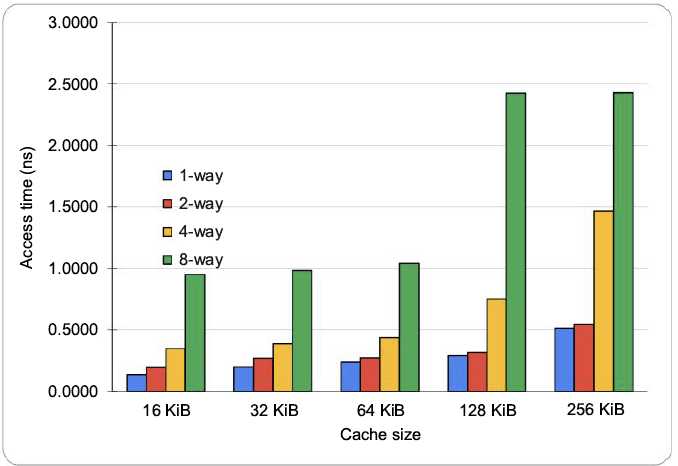
判断 32 KiB 四路组相联 L1 缓存的内存访问速度是否快于 32 KiB 两路组相联 L1 缓存。假设访问 L2 的缺失开销(失效开销)为更快的 L1 缓存访问时间的 15 倍,忽略 L2 之外的缓存缺失,哪一种缓存的平均内存访问时间(AMAT)更短?
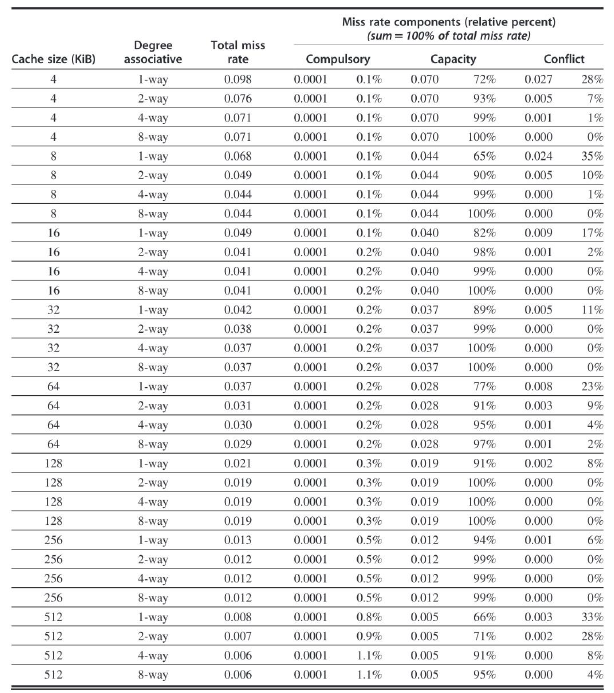
解答
设两路组相联缓存的访问时间为 1(基准单位时间),则对于二路缓存:
\(\text{Average memory access time}_{2 way} = \text{Hit time} + \text{Miss rate} \times \text{Miss penalty} = 1 + 0.038 × 15 = 1.38\)
对于四路缓存,其访问时间为两路的 \(1.4\) 倍,对应的缺失开销耗时为 \(15 ÷ 1.4 \approx 10.1\),为简化计算取 \(10\),则:
\(\text{Average memory access time}_{4 way} = \text{Hit time} + \text{Miss rate} \times \text{Miss penalty} = 1.4 + 0.037 × 10 = 1.77\)
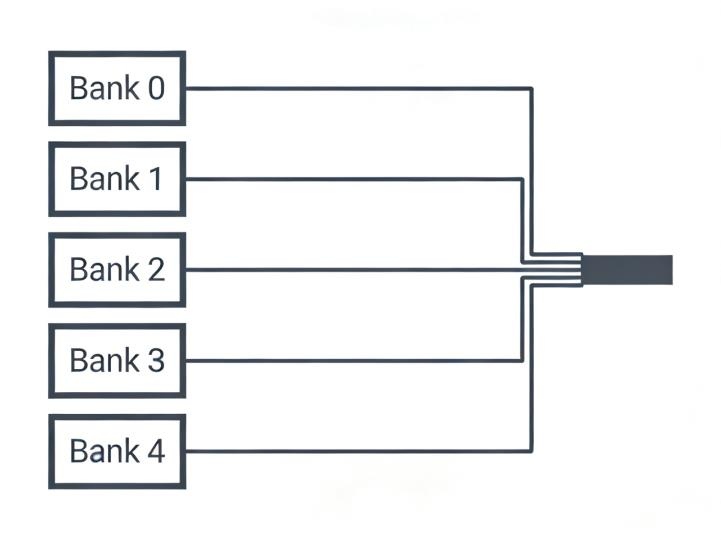
5. 3. 2 Multiple Banks and Ports to Increase the Bandwidth of L1 D-Caches¶
将 Cache 划分为多个独立 bank,并提供多个端口,以支持更高并发度的数据访问。
- 优点:显著提高带宽,特别适合多核处理器和乱序执行处理器。
- 缺点:Bank 冲突控制更复杂,硬件设计和验证成本更高。
- 适用场景:高性能多核处理器架构、图形处理单元(GPU)及其他需要极高内存带宽的应用。
5. 3. 3 Reducing the Miss Rate With Better Replacement Policies¶
用 LRU 或 LFU 等智能算法预测未来访问模式,优先替换无用数据,优于简单的 FIFO 策略。
- 优点:显著降低缓存失效率。
- 缺点:增加硬件复杂度与实现开销。
- 适用场景 :缓存容量受限,且数据访问模式具有较强局部性与可预测性的场景。
5. 3. 4 Multibanked L2 and L3 Caches¶
把大容量 L2 / L3 拆分为多个独立 bank,只激活当前访问到的 bank。
- 优点:降低功耗、降低访问延迟、提高总体带宽。
- 缺点:多 Bank 的管理逻辑增加了硬件设计的复杂度。
- 适用场景:现代高性能多核处理器的 L2/L3 缓存设计。

5. 3. 5 Nonblocking Caches¶
当 Cache miss 时,允许 CPU 继续执行后续可以执行的操作,而不是整个停住等待。
- 优点:让计算与 miss 处理重叠,提高吞吐量。
- 缺点:Cache 控制器与 CPU 硬件复杂度大幅上升。
- 适用场景:追求极致性能、支持乱序执行的高端处理器架构。
5. 3. 6 Critical Word First and Early Restart¶
发生 miss 时,不必等整个 block 全部返回后再恢复执行,而是优先返回 CPU 当前最需要的那个字,CPU 一旦拿到关键字就立刻恢复执行。
- 优点:显著降低有效 miss penalty。
- 缺点:内存控制器需要更复杂的调度逻辑。
- 适用场景:对访存延迟极其敏感,且经常访问大块数据中随机位置的程序。
5. 3. 7 Compiler Optimizations to Reduce Miss Rate¶
通过编译器或程序重写改善时间局部性与空间局部性,直接降低 miss rate。
Instruction Miss 优化
-
Reorder procedures in memory:
- 将连续调用的函数相邻放置,尽量落在同一 Cache line / 相邻 block
- 对存在分支的程序,把 Hot Path 连续布局,减少跳转带来的替换
- 若不能放在同一 block,也应尽量让高频函数分散到不同 Cache set,避免互相驱逐
-
Profiling to look at conflicts:
- 收集程序执行轨迹与 miss 事件
- 识别高频交替访问且映射到同一组的地址对
- 再通过函数重排、内联、冷热代码分离、地址对齐等方式优化
Data Miss 优化
- Merging arrays:将经常一起访问的多个数组合并布局,减少交替访问不同数组造成的 miss。
- Loop Interchange:通过交换循环嵌套顺序,使访问顺序匹配内存存储顺序,例如对行主序二维数组,应尽量按行连续访问。
- Loop Fusion:将循环结构相同且彼此独立、又共享部分数据的循环合并,减少重复访存。
- Loop Distribution:将互相冲突的访问拆成不同循环,让每个循环都能采用更适合局部性的访问顺序。
- Blocking:将迭代空间切成较小块,提高块内数据复用
5. 3. 8 Hardware Prefetching 与 Compiler-Controlled Prefetching¶
- 硬件预取(Hardware Prefetching):由硬件自动识别访问模式(如顺序访问),在 CPU 真正需要数据前,先把未来可能要访问的数据带入 Cache。
- 编译器控制预取(Compiler-Controlled Prefetching):编译器静态分析代码后,显式插入预取指令,指示 CPU 提前加载特定数据。
- 优点:可能降低 miss rate,也可能降低 miss penalty。
- 缺点:预测错误会浪费总线带宽与功耗。
- 适用场景:访问模式高度可预测的程序,例如数组遍历、矩阵运算等顺序 / 固定步长访问。
5. 3. 9 Multiple Memory Buses and Memory Modules to Increase Bandwidth¶
增加内存总线数量,让 CPU 能通过多条总线并行访问不同内存模块。
- 优点:显著提高内存带宽,缓解 CPU 与内存之间的数据传输瓶颈。
- 缺点:主板布线与设计复杂度更高,硬件成本增加。
- 适用场景:对内存带宽有极高需求的服务器、工作站及高性能计算(HPC)系统。
总结
Cache 优化的核心目标是降低 AMAT,但所有方法都需要在以下维度之间权衡:
- miss rate
- miss penalty
- hit time
- 带宽
- 硬件复杂度
- 功耗
现代高性能处理器几乎从不依赖单一技术,而是把多种方法组合起来使用。
性能计算示例
设:
- 忽略 memory stalls 时,所有指令基本都需要 \(1.0\) 个时钟周期
- cache miss penalty 为 \(200\) 个时钟周期
- average miss rate 为 \(2\%\)
- 每条指令平均有 \(1.5\) 次 memory references
- 每 \(1000\) 条指令平均有 \(30\) 次 cache misses
则:
- 由 misses / instruction 计算:
- 由 miss rate 计算:
因此:
课件同时给出对比:若没有 Cache,则
可见即使 miss penalty 很大,只要 Cache 能保持较低 miss rate,整体性能仍会得到极大改善。