朋辈辅学¶
流水线与非流水线处理器的时钟周期、指令延迟及资源利用率分析
In this exercise, we examine how pipelining affects the clock cycle time of the processor. Problems in this exercise assume that individual stages of the datapath have the following latencies:
| IF | ID | EX | MEM | WB |
|---|---|---|---|---|
| 250ps | 350ps | 150ps | 300ps | 200ps |
Also, assume that instructions executed by the processor are broken down as follows:
| ALU/Logic | Jump/Branch | Load | Store |
|---|---|---|---|
| 45% | 20% | 20% | 15% |
-
What is the clock cycle time in a pipelined and non-pipelined processor?
答案
\(\text{Clock Cycle Time}_{\text{pipelined}} = \max(250, 350, 150, 300, 200) = 350\ \text{ps}\)
\(\text{Clock Cycle Time}_{\text{non-pipelined}} = 250 + 350 + 150 + 300 + 200 = 1250\ \text{ps}\)
-
What is the total latency of an ld instruction in a pipelined and non-pipelined processor?
答案
流水线中一条指令需经过所有阶段,每个阶段占一个时钟周期,\(\text{Total Latency}_{\text{pipelined}} = 5 \times 350 = 1750\ \text{ps}\)
非流水线中一条指令占一个时钟周期,Load 指令的总延迟等于非流水线的时钟周期,\(\text{Total Latency}_{\text{non-pipelined}} = 1250\ \text{ps}\)
-
If we can split one stage of the pipelined datapath into two new stages, each with half the latency of the original stage, which stage would you split and what is the new clock cycle time of the processor?
答案
要减小流水线时钟周期,需拆分当前延迟最大的阶段,即 ID 阶段,拆分后新的时钟周期 \(\text{Clock Cycle Time}_{\text{new-pipelined}} = \max(250, 175, 175, 150, 300, 200) = 300\ \text{ps}\)
-
Assuming there are no stalls or hazards, what is the utilization of the data memory?
答案
数据内存仅被
Load和Store指令使用,在无 stall 的流水线中,每个时钟周期处理一条指令,利用率 \(= 20\% + 15\% = 35\%\) -
Assuming there are no stalls or hazards, what is the utilization of the write-register port of the "Registers" unit?
答案
寄存器写端口仅被需要写寄存器的指令使用,即
ALU/Logic和Load,利用率 \(= 45\% + 20\% = 65\%\)
无数据冒险处理下的寄存器值计算
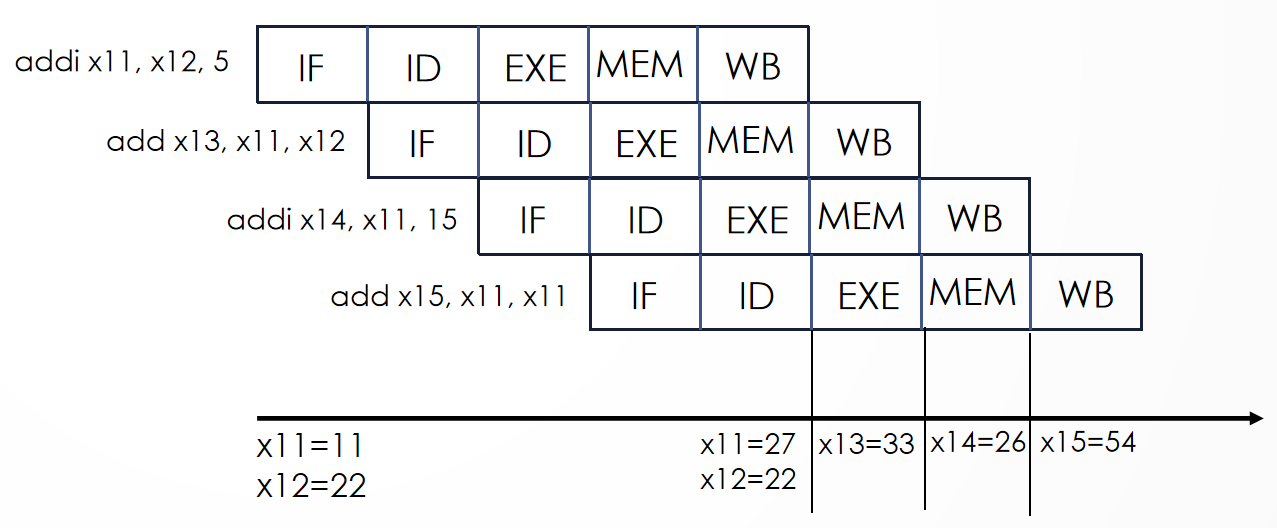
Assume that x11 is initialized to \(11\) and x12 is initialized to \(22\). Suppose you executed the code below on a version of the pipeline that does not handle data hazards (i.e., the programmer is responsible for addressing data hazards by inserting NOP instructions where necessary). What would the final values of register x13, x14, x15 be?
Assume the register file is written at the beginning of the cycle and read at the end of a cycle. Therefore, an ID stage will return the results of a WB state occurring during the same cycle.
addi x11, x12, 5
add x13, x11, x12
addi x14, x11, 15
add x15, x11, x11
答案
\(\text{x13} = 33\),\(\text{x14} = 26\),\(\text{x15} = 54\)
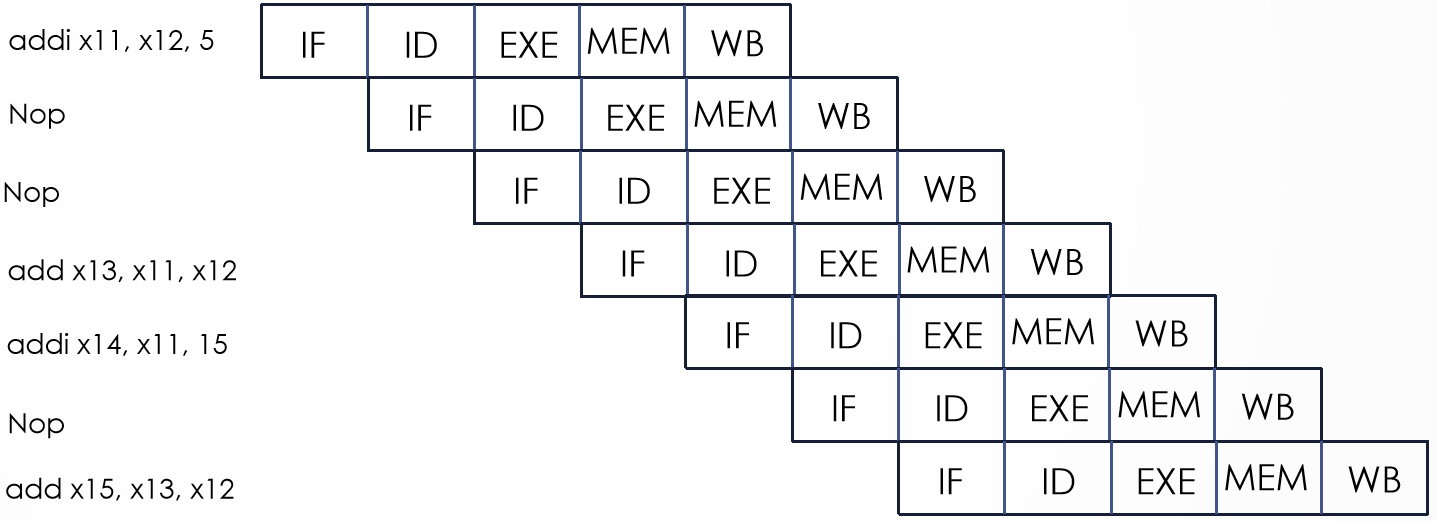
nop 指令的添加
Add NOP instructions to the code below so that it will run correctly on a pipeline that does not handle data hazards.
addi x11, x12, 5
add x13, x11, x12
addi x14, x11, 15
add x15, x13, x12
答案
addi x11, x12, 5
NOP
NOP
add x13, x11, x12
addi x14, x11, 15
NOP
add x15, x13, x12
流水线 RAW 数据依赖、转发机制与 CPI 及速度比综合分析
This exercise is intended to help you understand the cost/complexity/performance trade-offs of forwarding in a pipelined processor. These problems assume that, of all the instructions executed in a processor, the following fraction of these instructions has a particular type of RAW data dependence.

Assume the following latencies for individual pipeline stages. For the EX stage, latencies are given separately for a processor without forwarding and for a processor with different kinds of forwarding.

The type of RAW data dependence is identified by the stage that produces the result (EX or MEM) and the next instruction that consumes the result (1st instruction that follows the one that produces the result, 2nd instruction that follows, or both).
We assume that the CPI of the processor is 1 if there are no data hazards.
-
For each type RAW dependency above, how many nop instructions would need to be inserted to allow your code run correctly on a pipeline with no forwarding or hazard detection?
答案
EX to 1st only: 2 nops
MEM to 1st only: 2 nops
EX to 2nd only: 1 nop
MEM to 2nd only: 1nop
EX to 1st and EX to 2nd: 2nops
-
Analyzing each dependency type independently will over-count the number of nop instructions needed to run a program on a pipeline with no forwarding or hazard detection. In the code below, how many nop instructions are over-counted by analyzing dependency type independently?
ld x11, 0(x5) add x12, x6, x7 add x13, x11, x12 add x28, x29, x30答案
独立分析,
ld x11, 0(x5)属于 MEM to 2nd only,需要 1 个nop,add x12, x6, x7属于 EX to 1st only,需要 2 个nop,共计 3 个nop,但实际上只需要2个nop,故过度计数量为 \(1\)。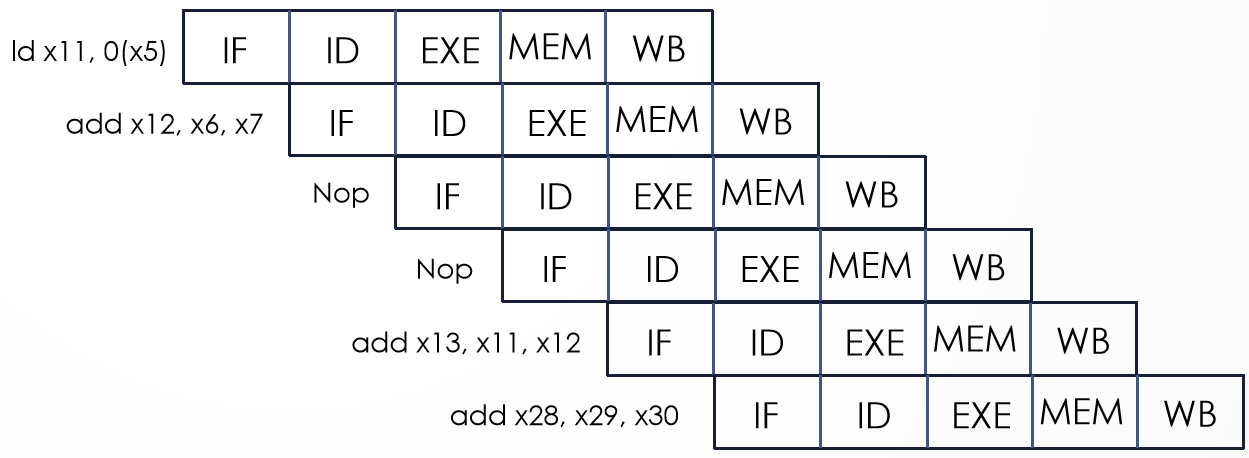
-
Assuming no other hazards, what is the CPI for the program described by the table above when run on a pipeline with no forwarding? What percent of cycles are stalls? (For simplicity, assume that all necessary cases are listed above and can be treated independently.)
答案
\(\text{Additional CPI} = 0.05×2 + 0.2×2 + 0.05×1 + 0.1×1 + 0.1×2 = 0.85\)
\(\text{CPI} = 1 + 0.85 = 1.85\)
\(\text{Percent Stalls} = \frac{0.85}{1.85} \approx 46 \%\)
-
What is the CPI if we use full forwarding (forward all results that can be forwarded)? What percent of cycles are stalls?
答案
全转发下,只有 MEM to 1st only 的依赖无法被转发解决,仍然需要一个
nop指令停顿,故\[ CPI = 1 + 0.2 \times 1 = 1.2$,$\text{Percent Stalls} = \frac{0.2}{1.2} \approx 17 \% \] -
Let us assume that we cannot afford to have three-input multiplexors that are needed for full forwarding. We have to decide if it is better to forward only from the EX/MEM pipeline register (next-cycle forwarding) or only from the MEM/WB pipeline register (two-cycle forwarding). What is the CPI for each option?
答案
- 若仅从 EX/MEM 寄存器转发,各情况需要的
nop数如下:
EX to 1st: 0 MEM to 1st: 2 EX to 2nd: 1 MEM to 2nd: 1 EX to 1st and 2nd: 1故 \(\text{CPI} = 1 + 0.2 \times 2 + 0.05 \times 1 + 0.10 \times 1 + 0.10 \times 1 = 1.65\)
- 若仅从 MEM/WB 寄存器转发,各情况需要的
nop数如下:
EX to 1st: 1 MEM to 1st: 1 EX to 2nd: 0 MEM to 2nd: 0 EX to 1st and 2nd: 1故 \(\text{CPI} = 1 + 0.05 \times 1 + 0.2 \times 1 + 0.10 \times 1 = 1.35\)
- 若仅从 EX/MEM 寄存器转发,各情况需要的
-
For the given hazard probabilities and pipeline stage latencies, what is the speedup achieved by each type of forwarding (EX/MEM, MEM/WB, for full) as compared to a pipeline that has no forwarding?
答案
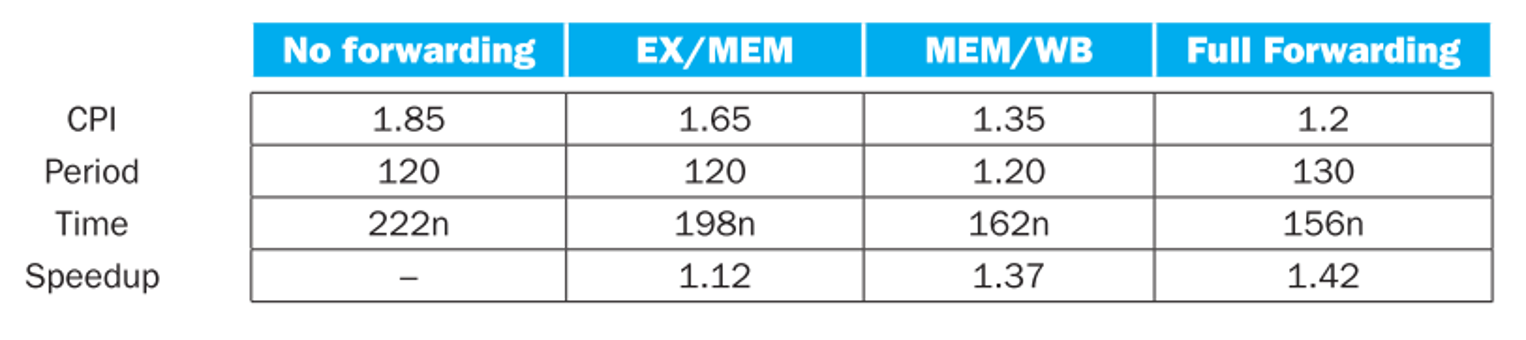
非线性流水线调度
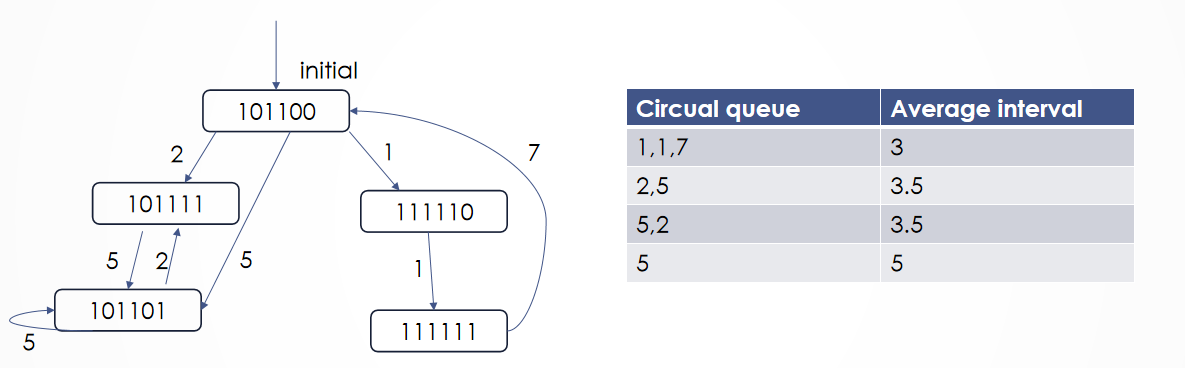
How to schedule this non-linear pipline? What’s the shortest average interval?
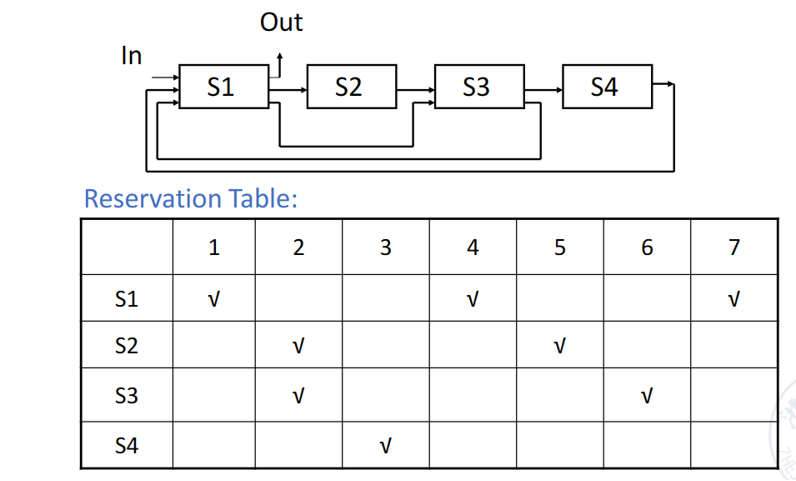
答案
进程调度
计算各个进程的 Turnaround time、Waiting time 和 Response time,以及总的平均 Turnaround time,Waiting time 和 Response time.
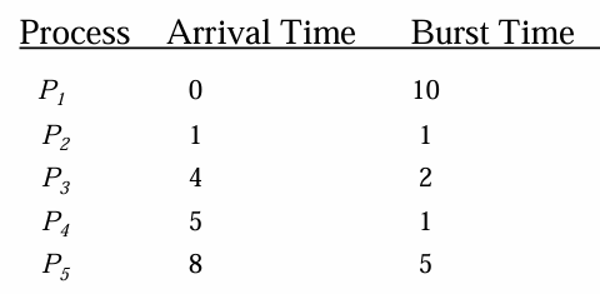
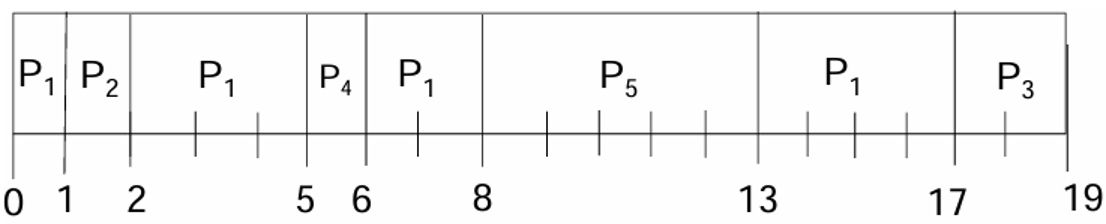
答案
| Process | Turnaround time | Waiting time | Response time |
|---|---|---|---|
| P1 | 17 | 7 | 0 |
| P2 | 1 | 0 | 0 |
| P3 | 15 | 13 | 13 |
| P4 | 1 | 0 | 0 |
| P5 | 5 | 0 | 0 |
| Average | 7.8 | 4 | 2.6 |