Chapter 2 Intro to Relational Model¶
In the context of this book, which one of the following is a relation (multiple selection)
- Your pet dog and you
- Your bank account and you
- All the members in a football team
- All the students currently attending this class
答案
关系是元组的集合,1、2 均为两两关联,并非元组集合;3、4 为同类型对象的集合,符合关系定义。
1 基本概念¶
1. 1 Relation Schema and Instance¶
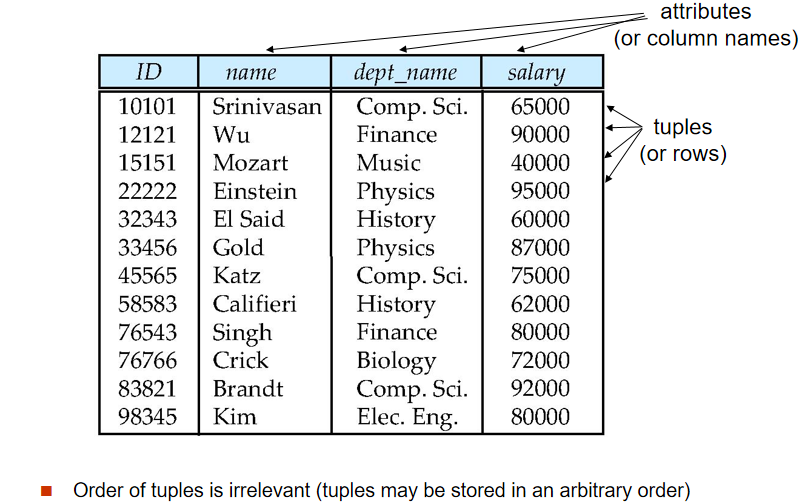
- 关系模式(Relation Schema):\(R=(A_1,A_2,...,A_n)\),其中 \(A_1-A_n\)为属性(attributes),如
instructor = (ID, name, dept_name, salary) - 关系实例(Relation Instance):给定属性域 \(D_1,D_2,...,D_n\),关系 \(r\subseteq D_1×D_2×…×D_n\)(不一定有理)
- \(r(R)\) 表示基于模式 \(R\) 的关系实例 \(r\),表是关系实例的等价概念
1. 2 Domain of Attribute¶
- 域(Domain):某一属性的允许值集合,是属性的取值范围
- 属性值需满足原子性(atomic),即不可再分
示例
- 原子性示例:
- 分别存储名和姓,如姓:“张”,名:“三”
- 如果不经常按名或姓查询,可以将全名存储在一个属性中,如姓名:“张三”
- 非原子性示例:
- 一个属性存储多个电话号码
- 一个属性存储书籍的作者/标题/出版社等所有信息
- 特殊值
null:属于所有域,表示值未知或不存在,会导致诸多操作的定义复杂化。
1. 3 Database¶
- 数据库(Database)由多个关系组成,企业信息会被拆分为多个关系存储,如
instructor、student、advisor
单表存储(如 univ (instructor_ID, name, dept_name, salary, student_Id, ...))的后果
- 信息冗余(如多个学生对应同一教师,教师信息重复)
- 大量
null值(如无导师的学生,导师字段为空)
- 数据库模式(Database schema):数据库的逻辑结构(所有关系模式的集合)
- 数据库实例(Database instance):某一特定时刻数据库中的实际数据(所有关系实例的集合)
- 规范化理论(Normalization theory):用于设计良好的关系模式,解决信息冗余和 null 值问题
1. 4 Keys¶
键(Keys)是关系模式 \(R\) 的属性子集,即 \(K\subseteq R\) 。
| 键的类型 | 定义 | 示例 |
|---|---|---|
| 超键 (Superkey) |
能唯一标识关系中任意元组的属性子集 | instructor 的 {ID}、{ID, name} |
| 候选键 (Candidate Key) |
最小的超键(无冗余属性) | instructor 的 {ID};grade(student_id, course_id, grade) 的 {student_id, course_id} |
| 主键 (Primary Key) |
从多个候选键中选定一个作为元组的唯一标识 | 选student_id 作为 student(student_id, name, mobile_phone, email) 的主键 |
| 外键 (Foreign Key) |
关系 \(R_1\) 中的属性子集,其值必须出现在另一关系 \(R_2\) 的主键中 | instructor 的 dept_name 参照 department 的 dept_name |
- 参照关系(Referencing relation):含外键的关系
- 被参照关系(Referenced relation):外键指向的关系
2 Relational Algebra¶
关系代数(Relational Algebra)是一种过程化语言(而非传统的编程语言),输入和输出均为关系,是实现关系数据库查询的基础。
2. 1 Basic Operators¶
| 操作 | 定义 | 特性 |
|---|---|---|
| 选择(Select) | \(\sigma_p(r)=\{t \, \lvert \, t\in r \, \text{and} \, p(t)\}\) | — |
| 投影(Project) | \(\prod\) | 删除未指定的属性,自动去重 |
| 并(Union) | \(r \cup s=\{t \, \lvert \, t\in r \, \text{or} \, t\in s\}\) | 要求同元数、属性域兼容,自动去重 |
| 差(Set Difference) | \(r-s=\{t \, \lvert \, t\in r \, \text{and} \, t \notin s\}\) | 要求同元数、属性域兼容 |
| 笛卡尔积(Cartesian Product) | \(r\times s=\{t \, q \, \lvert \, t\in r \, \text{and} \, q \in s\}\) | 属性名重复时需重命名 |
| 重命名(Rename) | \(\rho_{x(A_1,A_2,\dots,A_n)}(E)\) | 将表达式 \(E\) 的结果以名称 \(x\) 返回,同时将其属性重命名为 \(A_1, A_2, \dots, A_n\) |
Join Operation
- 等值连接:筛选笛卡尔积中指定属性值相等的元组,如 \(\sigma_{instructor.ID=teaches.ID}(instructor × teaches)\)。
-
组合操作(找出物理系所有教师的姓名及他们所教授的所有课程的课程 ID):
-
Query 1:\(\prod_{\text{instructor.name}, \text{course-id}} \left( \sigma_{\text{dept-name} = \text{'Physics'}} \left( \sigma_{\text{instructor.ID} = \text{teaches.ID}} \left( \text{instructor} \times \text{teaches} \right) \right) \right)\)
-
Query 2:\(\prod_{\text{instructor.name}, \text{course-id}} \left( \sigma_{\text{instructor.ID} = \text{teaches.ID}} \left( \sigma_{\text{dept-name} = \text{'Physics'}} \left( \text{instructor} \right) \times \text{teaches} \right) \right)\)
-
Query 2 先过滤再连接,减少了参与笛卡尔积的元组数量,更高效
2. 2 Additional Operations¶
不增加关系代数的表达能力,但可简化常见查询,均可通过基本操作实现。
| 操作 | 定义 | 注释 |
|---|---|---|
| 集合交 (Intersection) |
\(r\cap s=\{t \, \lvert \, t\in r \, \text{and} \, t\in s\}\) | 要求同元数、属性域兼容 |
| 自然连接 (Natural Join) |
\(r \bowtie_{\theta} s = \sigma_{\theta} \left( r \times s \right)\) | 满足结合律、交换律 |
| 赋值 (Assignment) |
\(\leftarrow\) | 将复杂查询的临时结果赋给变量,简化多层嵌套的复杂查询结构 |
| 外连接 (Outer Join) |
\(\bowtie_{left}\),\(\bowtie_{right}\),\(\bowtie_{full}\) | 通过 null 填充无匹配的属性值,避免信息丢失 |
| 除 (Division) |
\(\text{r} \div \text{s}\) 是满足 \(\text{t} \times \text{s} \subseteq \text{r}\) 条件的、定义在属性集 \(R-S\) 上的最大关系 \(\text{t}\) | \(\prod_{ID,course\_id}(takes) \div\) \(\prod_{course\_id}(\sigma_{dept\_name='Biology'}(course))\) 表示修读过生物学系所有课程的学生 |
通过基本操作实现除操作
\(temp1\leftarrow\prod_{R-S}(r)\),\(temp2\leftarrow\prod_{R-S}((temp1×s)-\prod_{R-S,S}(r))\),\(result\leftarrow temp1 - temp2\)
2. 3 Extended Operations¶
无法用基本操作表达,为关系代数增加了新的表达能力。
聚合函数(Aggregation function)
接收一组值作为输入,并返回单个值作为结果,如 avg()、min()、max()、sum()、count()。
| 公式 | 注释 | |
|---|---|---|
| 广义投影 (Generalized Projection) |
\(\Pi_{F_1,F_2,\dots,F_n}(E)\) | \(\textbf{·}\) \(E\) 为关系代数表达式 \(\textbf{·}\) \(F_1,F_2,\dots,F_n\) 为包含常量和属性的算术表达式 |
| 聚合操作 (Aggregate Operations) |
\(_{G_1,G_2,\dots,G_n} \ \mathcal{G} \ _{F_1(A_1),F_2(A_2),\dots,F_n(A_n)}(E)\) | \(\textbf{·}\) \(E\) 为关系代数表达式 \(\textbf{·}\) \(G_i\) 为用于分组的属性列表(可为空) \(\textbf{·}\) \(F_i\) 为聚合函数,\(A_i\) 为属性 |
计算各部门教师平均工资
3 Null Values¶
null表示值未知或不存在,是所有域的成员,元组的某些属性可能取空值- 含
null的算术表达式结果为null,如 \(5 + \text{null} = \text{null}\) count(*)统计所有元组(包括含null的元组),avg/min/max/sum/count(c)忽略null- 在去重和分组操作中,
null被视为普通值,且两个空值被认定为相等 - 与
null的比较结果为 \(\text{unknown}\)
引入 unknown 的三值逻辑运算规则
- 或运算(OR):
- \(\text{unknown} \ \text{or} \ \text{true} = \text{true}\)
- \(\text{unknown} \ \text{or} \ \text{false} = \text{unknown}\)
- \(\text{unknown} \ \text{or} \ \text{unknown} = \text{unknown}\)
- 与运算(AND):
- \(\text{true} \ \text{and} \ \text{unknown} = \text{unknown}\)
- \(\text{false} \ \text{and} \ \text{unknown} = \text{false}\)
- \(\text{unknown} \ \text{and} \ \text{unknown} = \text{unknown}\)
- 非运算(NOT):\(\text{not} \ \text{unknown} = \text{unknown}\)
- SQL 规则补充:若谓词 \(P\) 的计算结果为
unknown,则判定式 \(P \ \text{is} \ \text{unknown}\) 的结果为true
- 若查询谓词(select predicate)的计算结果为
unknown,则该结果会被视为false(即该元组不会被筛选出)
查找所有薪资为空的教师
select name
from instructor
where salary is null