Chapter 2 Design of Pipelining¶
1 Introduction¶
1. 1 Overlapping Execution¶
| 类型 | Sequential execution | Overlapping execution |
|---|---|---|
| 示意图 | 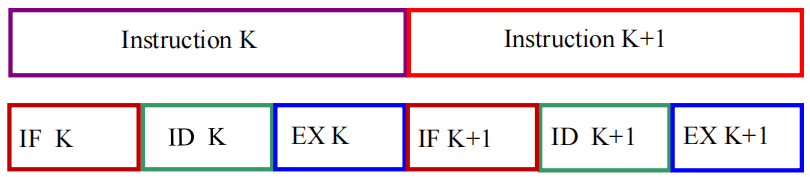 |
 |
| 执行时间 | \(T = \sum\limits_{i=1}^{n} (t_{IFi} + t_{IDi} + t_{EXi})\) | \(T = \sum\limits_{i=0}^{n} (t_{IFi} + t_{IDi} + t_{EXi}) = 3n\Delta t\) |
| 类型 | Single overlapping execution | Twice overlapping execution |
|---|---|---|
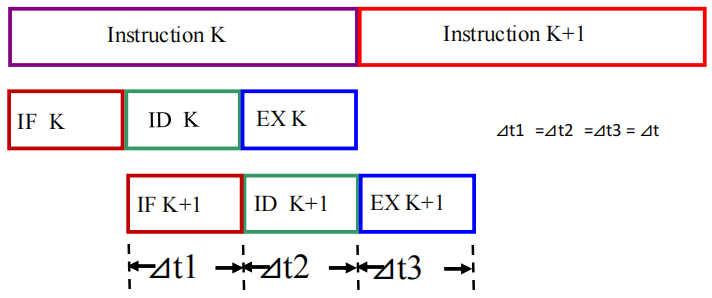
| 示意图 | 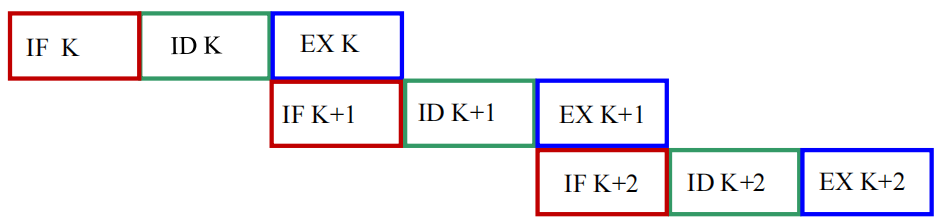 |
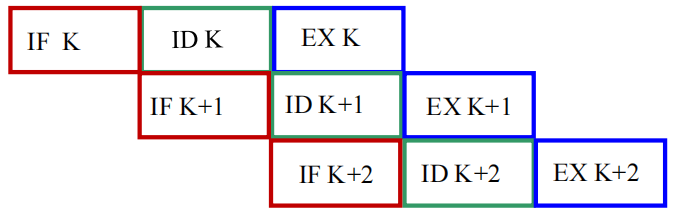 |
| 执行时间 | \(T=(2n+1) \Delta t\) | \(T = (n+2) \Delta t\) |
| 优点 | \(\textbf{·}\) 执行时间缩短约 \(1/3\) \(\textbf{·}\) 功能单元利用率明显提高 |
\(\textbf{·}\) 执行时间缩短约 \(2/3\) \(\textbf{·}\) 功能单元利用率明显提高 |
| 缺点 | \(\textbf{·}\) 需要额外的硬件 \(\textbf{·}\) 控制过程变复杂 |
\(\textbf{·}\) 需要更多的硬件 \(\textbf{·}\) 需要单独的取指、译码和执行组件 |
1. 2 流水线的特征¶
- 流水线将一个处理过程划分为多个子流程,每个子流程由特定功能单元实现
- 流水线中各阶段的时间间隔应尽可能保持一致,否则流水线将被阻塞并中断,其中耗时最长的阶段成为整个流水线的 bottleneck
- 流水线中的每个功能模块都必须配备一个 buffer register (latch) ,这种寄存器被称为流水线寄存器
- 流水线需要 pass time 和 empty time
- pass time :第一个任务从进入流水线开始到完成的整个过程
- empty time :最后一个任务从进入流水线到获得结果的整个过程
- 流水线将一条指令的处理过程划分为 \(m(m>2)\)个等时间的子过程,使 \(m\) 条相邻指令的处理过程在同一时间内交错并重叠进行
- 流水线可视为重叠执行的扩展
- 流水线中的每个子过程及其功能部件称为流水线的级或段,这些级或段相互连接构成流水线
- 流水线中段的数量称为流水线深度
2 流水线的类别¶
分段(Segmentation)、浮点运算(Floating Point Arithmetic)、乘法(Multiply)的处理步骤示意图
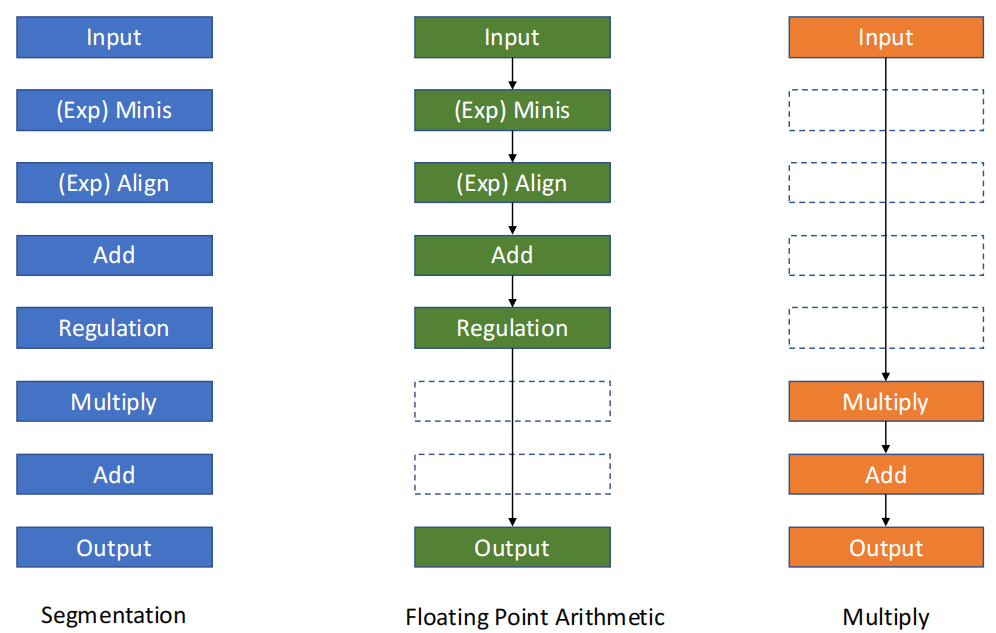
| 类型 | Single function pipelining | Multi function pipelining |
|---|---|---|
| 定义 | 只能完成一种固定功能的流水线 | 流水线的各个阶段可以进行不同的连接从而实现不同的功能 |
| 类型 | Static pipelining | Dynamic pipelining |
|---|---|---|
| 定义 | 同一时间段内,所有功能段仅能按单一固定连接方式工作,执行同一种功能 | 同一时间段内,多功能流水线的每个环节可采用不同连接方式,实现多任务并行处理 |
| 示意图 | 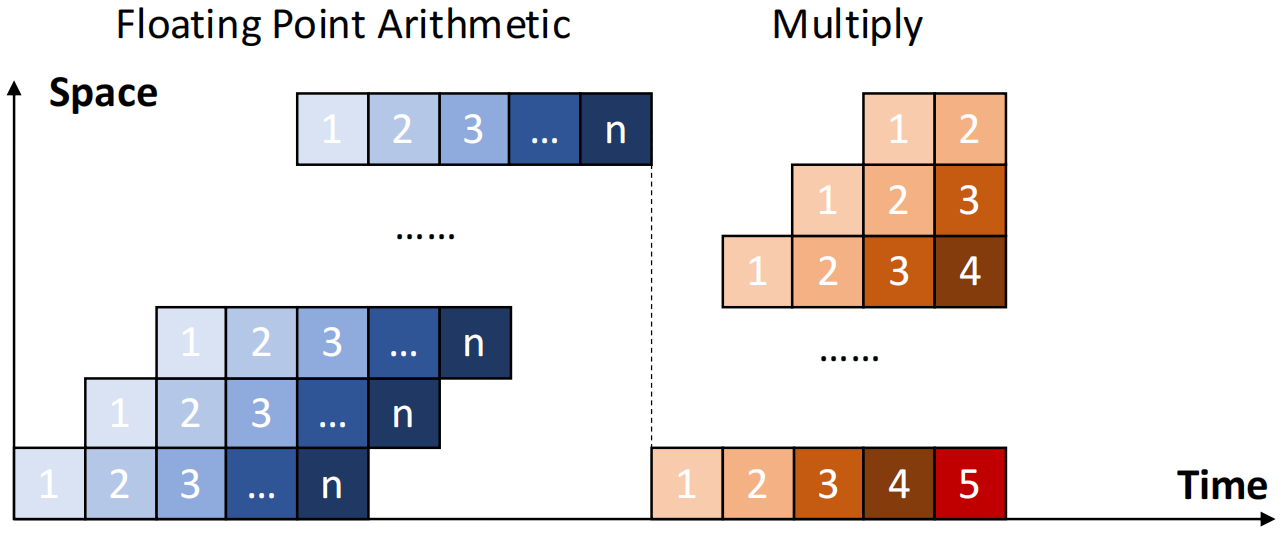 |
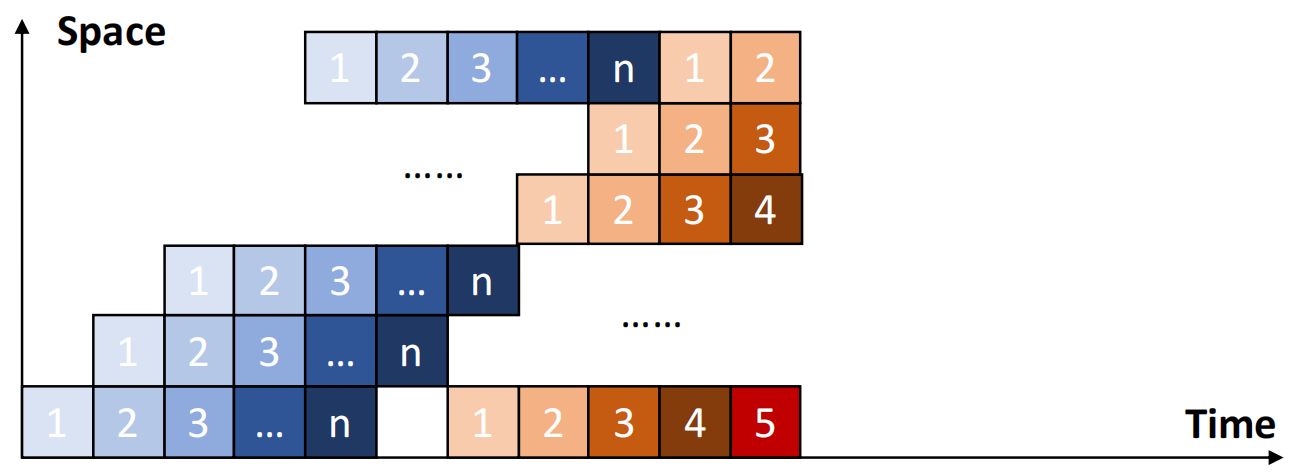 |
| 特点 | 当输入是一系列相同运算时,流水线的效率才能得到充分发挥 | \(\textbf{·}\) 灵活性强,但控制较为复杂 \(\textbf{·}\) 可提高功能单元的可用性 |
| 类型 | Component level pipelining (in component-operation pipelining) |
Processor level pipelining (inter component-instruction pipelining) |
Inter processor pipelining (inter processor-macro pipelining) |
|---|---|---|---|
| 定义 | 处理器的算术和逻辑运算组件被划分为多个段,以便通过流水线方式执行各类操作 | 指令的解释与执行通过流水线来实现。一条指令的执行过程被划分为若干子过程,每个子过程在一个独立的功能单元中执行 | 是两个或多个处理器的串行连接,用于处理同一数据流,且每个处理器完成整个任务的一部分 |
| 类型 | Linear pipelining | Nonlinear pipelining |
|---|---|---|
| 定义 | \(\textbf{·}\) 流水线的每个阶段串行连接,没有反馈回路 \(\textbf{·}\) 当数据通过流水线中的每个段时,每个段最多只能流经一次 |
除了串行连接之外,流水线中还存在反馈回路 |
| 类型 | Ordered pipelining | Disordered pipelining |
|---|---|---|
| 定义 | 在流水线中,任务的流出顺序与流入顺序完全一致。每个任务在流水线的每个段中按顺序流动 | 在流水线中,任务的流出顺序与流入顺序不一致。允许后续进入的任务先完成 |
| 类型 | Scalar processor | Vector pipelining processor |
|---|---|---|
| 定义 | 没有向量数据表示和向量指令,仅通过流水线处理标量数据 | 具有向量数据表示和向量指令,是向量数据表示与流水线技术的结合 |
3 流水线的实现¶
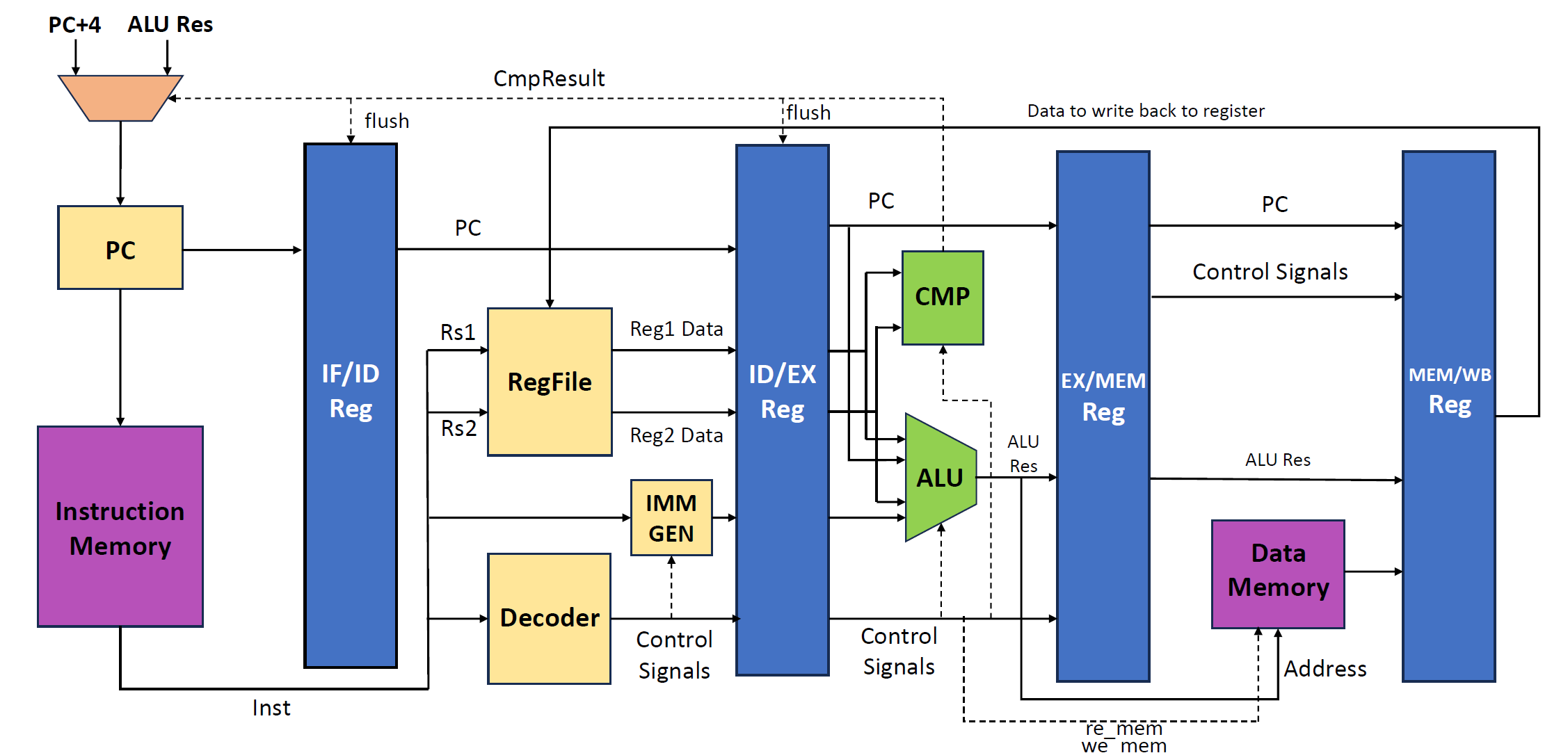

4 流水线性能评估¶
4. 1 吞吐量(Throughput, TP)¶
-
\(TP\) 指单位时间内流水线完成的任务数(或指令数),表示为 \(TP = \frac{n}{T}\)
-
理想情况下,流水线满负荷连续运行(无空闲、无填充开销),每 \(\Delta t_0\) 完成 1 个任务,则有最大吞吐量 \(TP_{\text{max}} = \frac{1}{\Delta t_0}\)
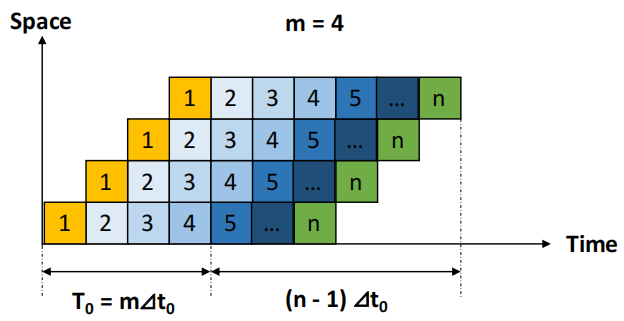
-
假设流水线有 \(m\) 个阶段(如 \(m=4\) 级流水线),每个阶段的时间为 \(\Delta t_0\),则实际吞吐量 \(TP = \frac{n}{(m + n - 1) \cdot \Delta t_0} = \frac{n}{n + m - 1} \cdot TP_{\text{max}}\)
-
当 \(n \gg m\) 即任务数远大于流水线段数时,\(TP \approx TP_{\text{max}}\),此时填充阶段的开销可忽略,流水线接近满负荷运行,吞吐量接近最大值
在实际场景下,流水线各阶段时间不同,其中耗时最长的阶段将成为整个流水线的瓶颈(bottleneck),此时有: $$ TP_{\text{max}} = \frac{1}{\max(\Delta t_1, \Delta t_2, ..., \Delta t_m)}$$ $$TP = \frac{n}{\sum_{i=1}^{m} \Delta t_i + (n - 1) \times \max(\Delta t_1, \Delta t_2, ..., \Delta t_m)} $$
- 解决流水线瓶颈的常见方法:
- Subdivision:将瓶颈阶段拆分为若干个亚阶段
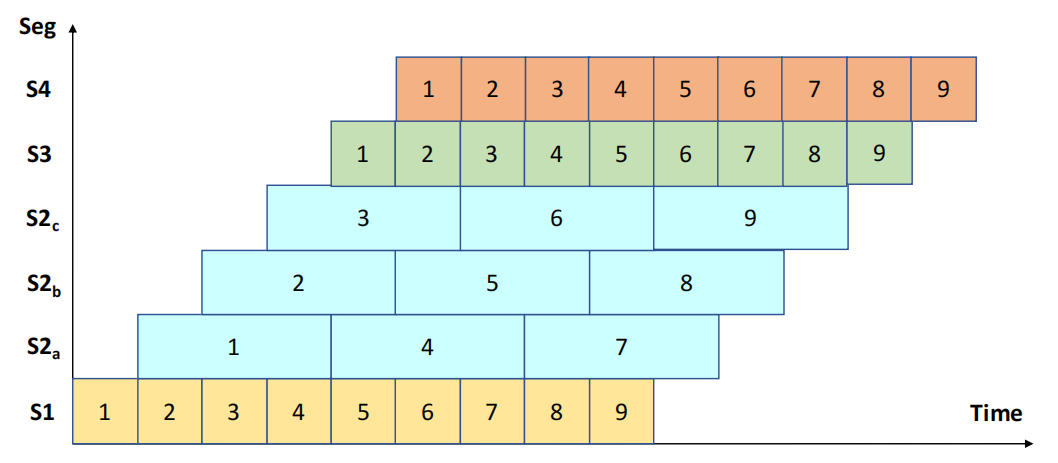
- Repetition:用 Data distributor 将来自 \(S_1\) 的任务分发到多个并行的 \(S_2\) 子阶段,再用 Data collector 将并行子阶段的结果汇总,传递给后续阶段(如下图) ,相当于复制瓶颈阶段,用空间换时间
4. 2 加速比(Speedup, Sp)¶
-
Sp 定义为非流水线执行时间与流水线执行时间的比值,用于衡量流水线对性能的提升程度,公式为:\(\text{Sp} = \frac{\text{Execution Time}_{\text{nonpipelined}}}{\text{Execution Time}_{\text{pipelined}}}\)
-
理想情况下,\(\text{Sp} = \frac{n \times m \times \Delta t_0}{(m + n - 1) \times \Delta t_0} = \frac{n \times m}{m + n - 1}\)
-
当 \(n \gg m\)时,\(\text{Sp} \approx m\),这表示任务数足够多时,加速比接近流水线的段数
4. 3 效率(Efficiency, η)¶
-
\(\eta = \frac{\text{Execution Time}_{\text{nonpipelined}}}{\text{Execution Time}_{\text{pipelined}} \times m}\)
-
理想情况下,\(\eta = \frac{n \times m \times \Delta t_0}{(m + n - 1)\Delta t_0 \times m} = \frac{n}{m + n - 1}\)
-
当 \(n \gg m\)时,\(\eta \approx 1\)
为什么要使用流水线?
- 减少 CPU 时间
- 提高吞吐量(而非单个指令的执行时间)
- 提高功能部件的资源效率
为什么不直接做一个 50 级的流水线?
- 级数太多会产生大量复杂情况(如需处理正在执行的指令之间存在的依赖关系),控制逻辑会变得十分庞大
- 锁存器会占用空间,且信号通过锁存器本身也会产生延迟(机器周期 > 锁存器延迟 + 时钟偏斜)
哪些因素会影响多功能流水线的效率?
- 当多功能流水线执行某一特定功能时,总会有一些用于其他功能的段处于空闲状态
- 在流水线建立的过程中,一些即将被使用的段也会处于空闲状态
- 当各段的处理时间不相等时,时钟周期取决于瓶颈段的时间
- 当功能切换时,流水线需要被清空
- 上一个操作的输出是下一个操作的输入
- 额外开销:流水线寄存器延迟以及时钟偏斜的开销
例题:静态双功能流水线
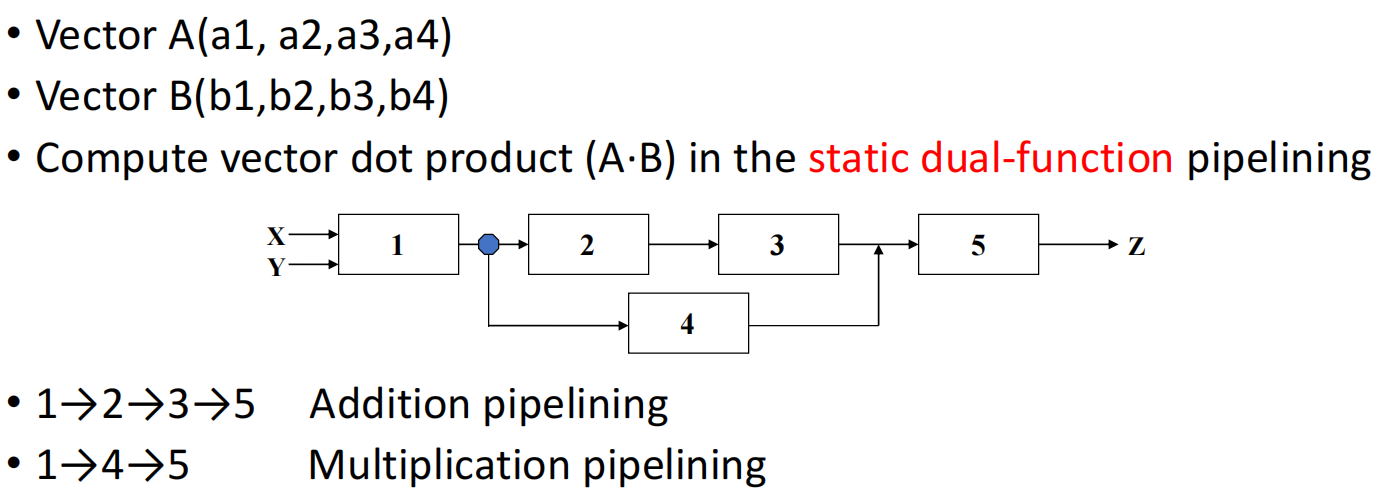
答案
根据题意,绘制 Time-Segments 图:
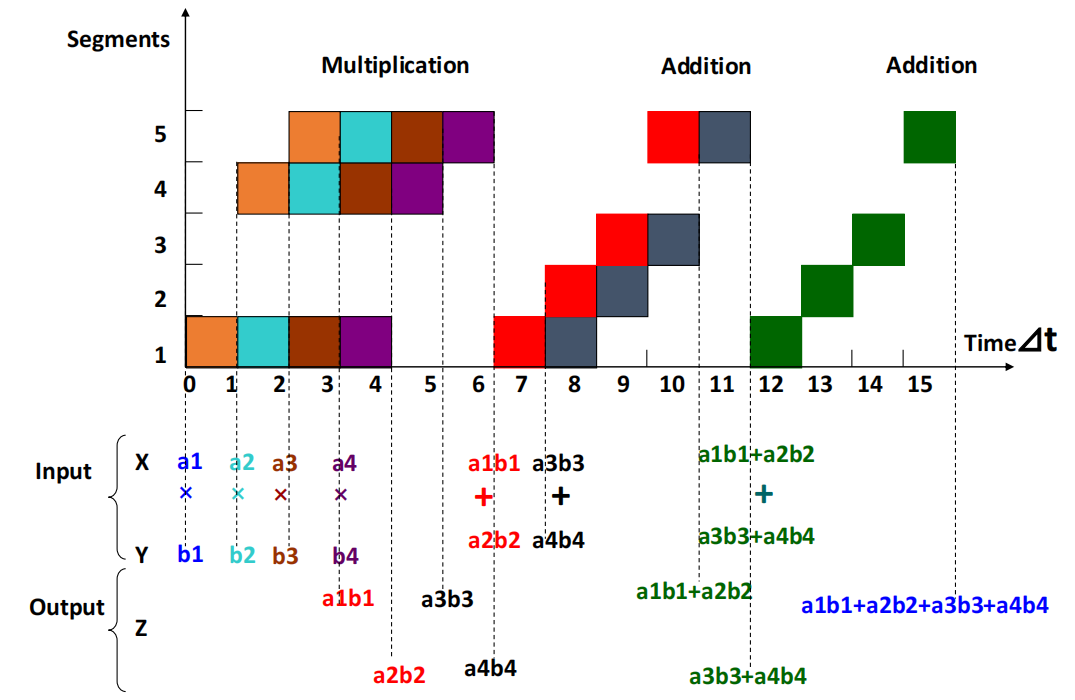
故 \(TP = \frac{7}{15 \Delta t},\quad Sp = \frac{4×3Δt+3×4Δt}{15Δt} = 1.6,\quad \eta = \frac{3×4Δt+4×3Δt}{5×15Δt} = 32\%\)
例题:动态双功能流水线
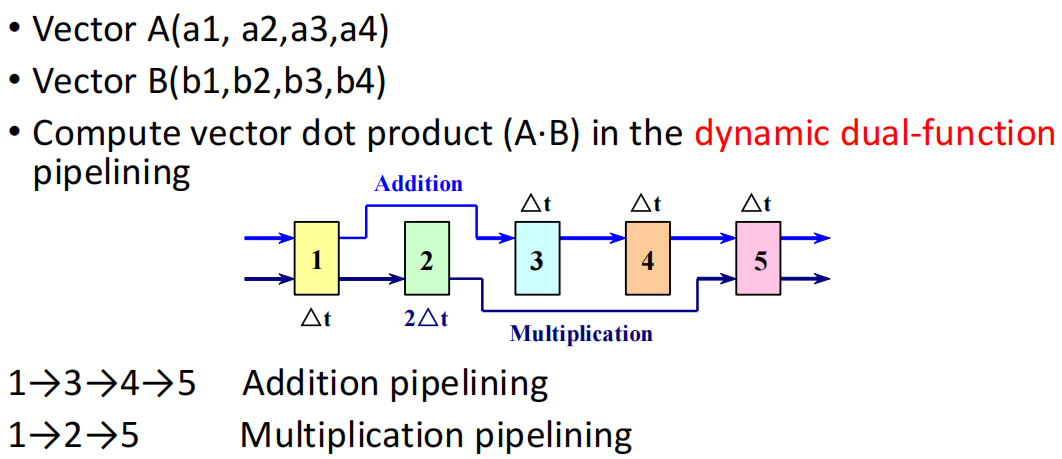
答案
根据题意,绘制 Time-Segments 图:
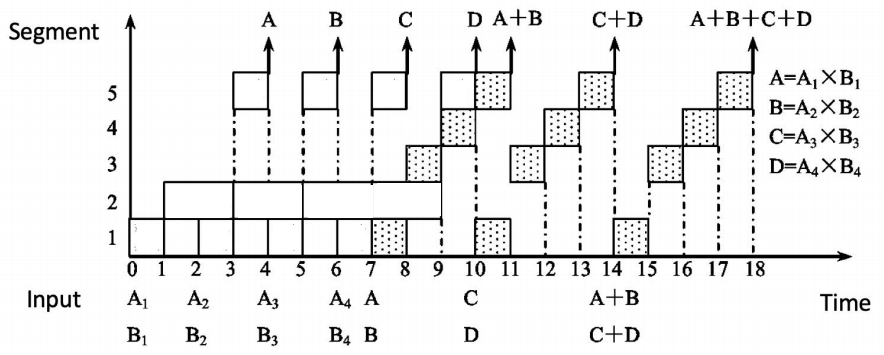
故 \(TP = \frac{7}{18\Delta t}, \quad Sp = \frac{28\Delta t}{18\Delta t} \approx 1.56, \quad \eta = \frac{4 \times 4 + 3 \times 4}{5 \times 18} \approx 0.31\)