Chapter 15 Query Processing¶
1 Overview¶
- 解析与翻译(Parsing and translation):将查询语句转换为内部形式,再进一步转换为关系代数表达式。解析器(Parser)会检查语法错误,并验证查询中涉及的关系(表)是否合法。
- 优化(Optimization):关系代数表达式往往有很多等价写法,需要在所有等价计划中选代价最低的那个。
- 执行(Evaluation):查询执行引擎接收查询执行计划,执行该计划,并最终返回查询结果。
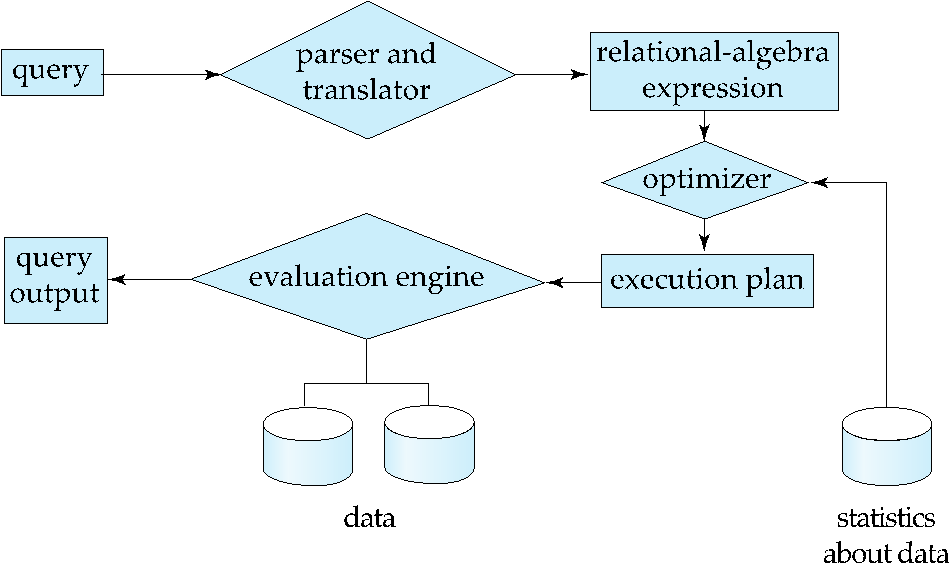
- 执行计划(evaluation-plan):带有具体执行策略的表达式
成本衡量主要看磁盘块传输次数和寻道次数作为成本衡量指标,默认忽略 CPU 成本和最终输出写盘成本。代价估计依赖系统目录里的统计信息,如关系大小、元组数、块数和索引高度等
常用代价模型
设一次块传输时间为 \(t_T\),一次寻道时间为 \(t_S\),则总代价近似为:
2 Selection¶
- 线性查找(Linear search):遍历全部数据块,逐条核对记录是否符合筛选条件。
- 索引扫描(Index scan ):使用索引进行查询,查询条件必须作用于索引的搜索键上。
成本
- 普通查询开销:\(b_r\) 次块传输 \(+\) \(1\) 次寻道(文件连续存储,\(b_r\) 为数据块总数)
- 主键/唯一键查询:匹配成功立即停止扫描,平均开销 \(\dfrac{b_r}{2}\) 次块传输 \(+\) \(1\) 次寻道
二分查找
由于数据在磁盘上通常不是连续存储的,因此直接对数据文件进行二分查找通常不切实际。只有在有索引可用时二分查找才有意义,而且,二分查找的寻道次数通常比索引查找更多,效率反而更低。
-
主索引 + 键属性等值查询(primary index, equality on key):检索满足对应等值条件的单条记录,成本为 \((h_i + 1) \times (t_T + t_S)\)。
-
主索引 + 非键属性等值查询(primary index, equality on nonkey):检索多条记录,假设匹配的记录位于连续的数据块中,令 \(b\) 为包含匹配记录的数据块数量,则成本为 \(h_i \times (t_T + t_S) + t_S + t_T \times b\)。
-
二级索引 + 非键属性等值查询(secondary index, equality on nonkey)
- 若搜索键为候选键,则检索单条记录,成本为 \((h_i + 1) \times (t_T + t_S)\)。
- 若搜索键非候选键,则检索多条记录,这 \(n\) 条匹配记录可能分别位于不同的磁盘块中,成本为 \((h_i + n) \times (t_T + t_S)\),此时开销可能非常高。
-
主索引 + 比较(primary index, comparison):假设关系已按 \(A\) 字段排序
- \(\sigma_{A \geq V}(r)\):使用索引找到第一个满足 \(A \geq V\) 的元组,再从该位置开始顺序扫描整个关系。
- \(\sigma_{A \leq V}(r)\):直接顺序扫描整个关系,直到遇到第一个 \(A > V\) 的元组为止,不使用索引。
-
二级索引 + 比较(secondary index, comparison)
- \(\sigma_{A \geq V}(r)\):使用索引找到第一个满足 \(A \geq V\) 的索引项,再从该位置开始顺序扫描索引,获取所有记录的指针。
- \(\sigma_{A \leq V}(r)\):直接扫描索引的叶子节点页面,获取记录指针,直到遇到第一个 \(A > V\) 的索引项为止。
范围查询的直觉
- primary index 上做范围扫描,常可以从第一个命中位置开始顺序读
- secondary index 上做范围扫描时,记录地址可能很分散,随机 I/O 可能很多,当命中率较高时,线性扫描反而可能更便宜
-
使用单个索引的合取选择(conjunctive selection using one index):多个条件中挑一个最便宜的索引策略,其余条件在内存中过滤。
-
使用复合索引的合取选择(conjunctive selection using composite index):如果存在合适的复合索引则直接使用。
-
通过标识符交集实现的合取选择(conjunctive selection by intersection of identifiers):分别用多个索引拿到记录指针(record pointers),再求交集。
-
通过标识符并集实现的析取选择(disjunctive selection by union of identifiers):对多个
OR条件分别取指针集合,再求并集,仅当所有条件都有可用索引时适用,否则使用线性扫描。
3 Sorting¶
对于能全部装入内存的关系,可以使用快速排序,但对于无法装入内存的关系,外部归并排序(external sort-merge)是合适的选择。
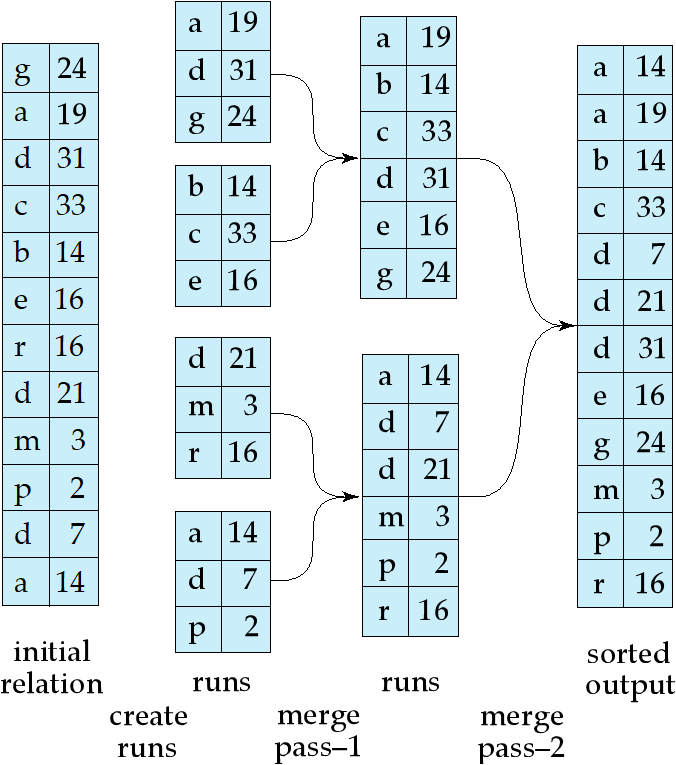
设 \(M\) 为内存大小(以页为单位),\(b_r\) 为数据文件的块数。
- 创建有序段(sorted runs):每次读入 \(M\) 个块到内存并在内存中进行排序,将排序后的数据写入有序段,直到处理完整个关系,有序段的总数为 \(N = \lceil b_r / M \rceil\)。
- 归并有序段(N-way merge):
- 若 \(N < M\):分配 \(N\) 个内存块作为输入缓冲区,\(1\) 个内存块作为输出缓冲区,将每个有序段的第一个块读入对应的输入缓冲区,反复选取所有输入缓冲区中的第一条记录写入输出缓冲区,满则落盘,空则续读,直至全部数据归并完成。
- 若 \(N \ge M\):多轮归并,每轮将连续的 \(M-1\) 个有序段合并为一个更大的有序段,直至所有有序段最终合并为一个完整的有序文件。
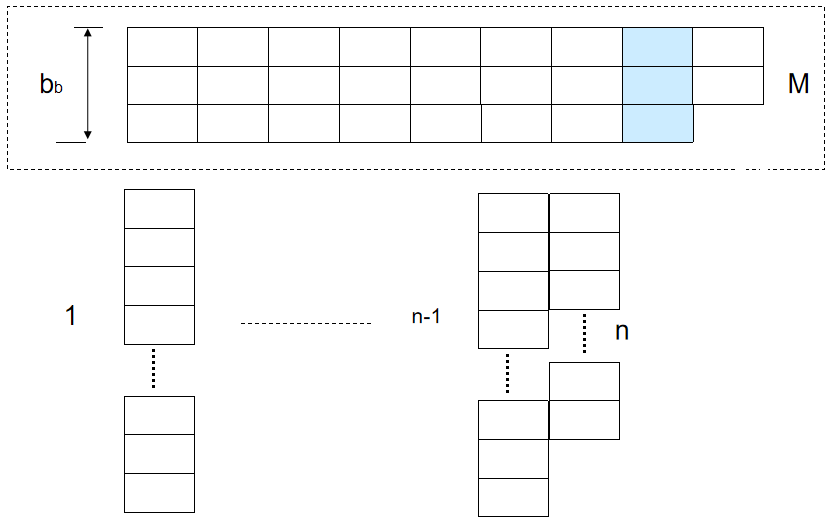
实际实现时通常为每个有序段分配 \(b_b\) 个连续块的输入缓冲区,通过批量读入数据减少磁盘 I/O 开销,提升归并效率。
多缓冲预读优化
若每个有序段仅分配 \(1\) 个数据块作为缓冲区,则会导致归并过程中磁盘寻道次数过多。作为改进,可以为每个有序段分配 \(b_b\) 个数据块作为缓冲区,每次可批量读写 \(b_b\) 个数据块。
- 单轮归并可处理的有序段数量 \(k = \lfloor \dfrac{M}{b_b} \rfloor -1\)
- 初始归并段数量 \(r = \lceil \dfrac{b_r}{M} \rceil\)
- 所需归并轮次总数 \(x = \lceil \log_k r \rceil\)
- 初始有序段生成及每轮归并的数据块传输量 \(= 2b_r\)
- 总数据块传输量:
- 默认最终结果不写回磁盘,最后一趟只读不写:\(b_r (2x + 1)\)
- 最终结果写回磁盘,最后一趟需要增加 1 次写操作:\(2 b_r (x + 1)\)
磁盘寻道开销
若算法在一次连续读写操作中可处理的块数为 \(b\),总共需要读写的块数为 \(B\),则总寻道次数为 \(\left\lceil \frac{B}{b} \right\rceil\)。
创建有序段时,每生成 \(1\) 个有序段需要 \(1\) 次读寻道和 \(1\) 次写寻道,总寻道次数为 \(2\left\lceil \frac{b_r}{M} \right\rceil\)。
归并有序段时,每一轮归并需要 \(2\left\lceil \frac{b_r}{b_b} \right\rceil\) 次寻道(实际可能更多,因为每个有序段的块数不一定是 \(b_b\) 的整数倍),总寻道次数为:
若最终结果写回磁盘,最后一趟增加写寻道,总寻道次数为:
4 Join Algorithms¶
Examples use the following information
- student 表记录数为 5000,读取开销为 10000
- student 表数据块数为 100,读取开销为 400
4. 1 Nested-Loop Join¶
for each tuple t_r in r do begin
for each tuple t_s in s do begin
test pair (t_r, t_s) to see if they satisfy the join condition θ
if they do, add t_r ⋅ t_s to the result.
end
end
其中关系 \(r\) 称为外关系(outer relation),\(s\) 称为内关系(inner relation)。该算法无需索引,可支持任意连接条件,但代价高昂。
- 最坏情况:内存只能容纳每个关系的 \(1\) 个数据块,此时块传输次数为 \(n_r \times b_s + b_r\),寻道次数为 \(n_r + b_r\)
- 若较小的关系能完全装入内存,则将其作为内关系,此时块传输次数为 \(b_r + b_s\),寻道次数为 \(2\)
4. 2 Block Nested-Loop Join¶
这是嵌套循环连接的一种变体,将内层关系的每一个数据块与外层关系的每一个数据块进行配对,显著降低内表重复扫描。
for each block B_r of r do begin
for each block B_s of s do begin
for each tuple t_r in B_r do begin
for each tuple t_s in B_s do begin
Check if (t_r, t_s) satisfy the join condition
if they do, add t_r • t_s to the result.
end
end
end
end
- 最坏情况:外层关系的每一块都需要读取一次内层关系的所有块,此时块传输次数为 \(b_r \times b_s + b_r\),寻道次数为 \(2 \times b_r\)
- 最好情况:块传输次数为 \(b_r + b_s\),寻道次数为 \(2\)
优化方案
在块嵌套循环中,使用 \(M-2\) 个磁盘块作为外层关系的分块单元(其中 \(M\) 为以块为单位的内存大小),剩余的 \(2\) 个块用于缓存内层关系和输出结果
- 块传输次数:\(\lceil \dfrac{b_r}{M-2} \rceil \times b_s + b_r\)
- 寻道次数:\(2 \times \lceil \dfrac{b_r}{M-2} \rceil\)
若等值连接的属性是内层关系的键,则匹配到第一条结果时终止内层循环。内层循环交替正向、反向扫描以利用 LRU 缓存中仍驻留的块。若内层关系存在索引,则使用索引。
4. 3 Indexed Nested-Loop Join¶
当连接是等值连接或自然连接,且内层关系的连接属性上存在索引(也可专门构建)时,可以用外表每条记录去索引里查内表,若两边都有索引,则通常选更小的关系做外关系。
最坏情况下,缓冲区仅能容纳 r 的一个页块,且对于 r 中的每一条元组都需要对 s 执行一次索引查找。此时连接的成本为 \(b_r(t_T + t_S) + n_r \times c\),其中 \(c\) 是遍历索引并获取 r 中一条元组对应的所有匹配 s 元组的成本,可以估算为使用该连接条件对 s 执行一次单表选择操作的成本。
连接成本计算示例:计算 student ⋈ takes(student 作为外层关系)
假设 takes 表在 ID 属性上建有主键 B+ 树索引,每个索引节点包含 20 条记录项。由于 takes 表有 10000 条元组,该索引树的高度为 4,还需要额外 1 次访问才能读取实际数据。student 表有 5000 条元组。
- 块嵌套循环:块传输次数为 \(400 \times 100 + 100 = 40100\) ,寻道次数为 \(2 \times 100 = 200\)(假设为内存最坏情况,若内存更大,成本可显著降低)
- 索引嵌套循环:块传输与寻道总次数为 \(100 + 5000 \times 5 = 25100\) 次,CPU 开销通常低于块嵌套循环连接
4. 4 Merge Join¶
对两个关系先按连接属性排序,再同步扫描并合并,仅可用于等值连接和自然连接。
每个数据块仅需读取一次(假设同一连接属性值的所有元组都能装入内存),因此块传输次数为 \(b_r + b_s\),寻道次数为 \(\lceil \dfrac{b_r}{b_b} \rceil + \lceil \dfrac{b_s}{b_b} \rceil\),若关系未排序,还需额外加上排序操作的成本。
混合合并连接(hybrid merge-join)
当一个关系已排序,另一个关系在连接属性上建有二级 B+ 树索引时使用。
- 将已排序的关系与 B+ 树的叶子节点条目进行合并。
- 按未排序关系元组的物理地址,对上述结果进行排序。
- 按物理地址顺序扫描未排序关系,与上一步的结果合并,将地址替换为实际元组。
顺序扫描的效率远高于随机查找。
4. 5 Hash Join¶
先用同一个哈希函数对两个关系进行分区,并为每个分区在内存中预留一个块作为输出缓冲区,再在每个分区内做构建-探测。适用于等值连接和自然连接。
构建-探测(build-probe)
- 将 \(s_i\) 加载到内存中,基于连接属性构建一个内存哈希索引。该哈希索引使用的哈希函数与之前的 \(h\) 不同。
- 从磁盘中逐条读取 \(r_i\) 中的元组。对于每个元组 \(t_r\),使用内存哈希索引在 \(s_i\) 中定位所有匹配的元组 \(t_s\),并输出二者属性拼接后的结果。
其中关系 \(s\) 称为构建输入(build input),关系 \(r\) 称为探测输入(probe input),构建关系通常选更小的那边。
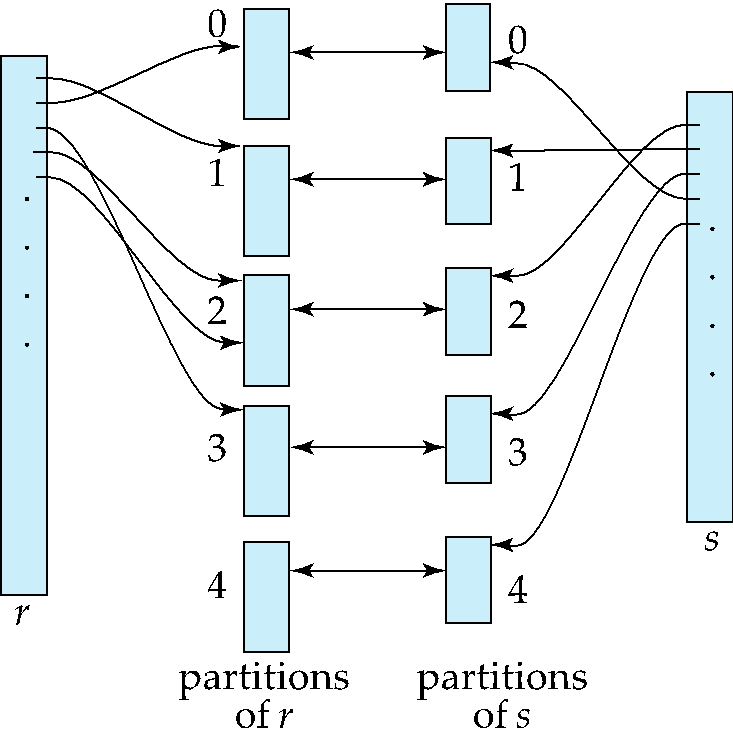
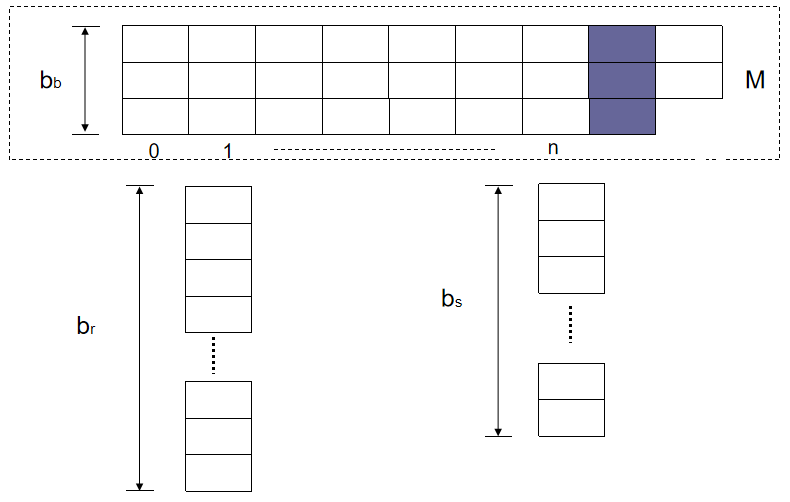
分区数 \(n\) 和哈希函数 \(h\) 需保证每个分区 \(s_i\) 都能装入内存,通常 \(n\) 的取值为 \(\lceil \dfrac{b_s}{M} \times f \rceil\),其中 \(f\) 是修正系数,一般约为 \(1.2\),探测关系的分区 \(r_i\) 无需装入内存。
若分区数 \(n\) 大于内存页数 \(M\),则需要使用递归分区(recursive partitioning),先将两个关系分为 \(M-1\) 个分区,再使用不同的哈希函数进一步分区。实际场景中递归分区很少用到。
Handling of Overflows
当某些分区的元组数量远多于其他分区时,称为倾斜(skewed)分区。
\(s\) 中大量元组的连接属性值相同或哈希函数设计不当可能导致分区 \(s_i\) 无法装入内存,进而发生哈希表溢出(Hash-table overflow)。
- 溢出解决:在构建阶段处理溢出,使用不同的哈希函数对分区 \(s_i\) 和 \(r_i\) 进行进一步分区
- 溢出避免:通过谨慎的分区操作避免构建阶段发生溢出,例如先将构建关系划分为多个分区,再合并分区
当存在大量重复值时,上述两种方法均会失效,可以对发生溢出的分区改用块嵌套循环连接。
| 场景 | 块传输次数 (I/O 开销) | I/O 寻道次数 |
|---|---|---|
| 无递归分区 | 分区阶段:\(2(b_r + b_s) + 2n_h\) 构建+探测阶段:\((b_r + b_s) + 2n_h\) 总代价:\(3(b_r+b_s)+4n_h\) |
分区阶段:\(2(\lceil \frac{b_r}{b_b} \rceil + \lceil \frac{b_s}{b_b} \rceil)\) 构建+探测阶段:\(2n_h\) |
| 递归分区 | \(2(b_r + b_s) \cdot \lceil \log_{\lfloor M/b_b \rfloor -1}{(\frac{b_s}{M})} \rceil + b_r + b_s\) | \(2(\lceil \frac{b_r}{b_b} \rceil + \lceil \frac{b_s}{b_b} \rceil) \cdot \lceil \log_{\lfloor M/b_b \rfloor -1}{(\frac{b_s}{M})} \rceil\) |
| 构建关系可全部装入内存 | \(b_r + b_s\) | 无需额外寻道 |
混合哈希连接(Hybrid Hash-Join)
当内存容量相对较大,但构建关系(build input)的大小仍超过内存时,混合哈希连接能发挥优势。
混合哈希连接将构建关系的第一个分区完整保留在内存中,无需写入磁盘。
假设内存大小为 25 块,instructor 表(构建关系)有 100 块,分为 5 个分区,每个分区 20 块;teaches 表(探测关系)有 400块,分为 5 个分区,每个分区 80 块。
则 instructor 的第 1 个分区全程留在内存,无需写入磁盘,teaches 的第 1 个分区读取后直接与内存中的哈希表进行探测匹配,也无需写入磁盘。
此时块传输总次数为 \(3 \times (80 + 320) + 20 + 80 = 1300\),省略了第 1 个分区的读写开销。
4. 6 Complex Join Conditions¶
- 带合取条件的连接(Conjunctive Join):先做最便宜的部分连接,再过滤剩余条件
- 带析取条件的连接(Disjunctive Join):把各个子连接的结果取并集
5 Other Operations¶
- 重复元组消除(Duplicate Elimination):可以通过哈希(Hashing)或排序(Sorting)两种方式实现。
- 投影操作(Projection):先投影,再去重
- 聚合运算(Aggregation):先分组,再计算聚合值
优化方案:部分聚合计算
在外部排序的有序片段生成(run generation)和中间归并(merge)阶段,就可以提前计算并合并部分聚合值,无需等到所有数据归并完成后再计算,大幅减少 I/O 开销。
- 集合运算(Set Operations):都可以通过排序归并法和哈希法实现。
- 外连接(Outer Join):可以先执行普通的内连接再为未匹配的元组补充空值(
NULL),也可以直接修改现有的连接算法使其支持外连接逻辑。- 基于归并连接(Merge Join)的左外连接:\(r - \Pi_R(r \bowtie s)\),在归并过程中,对于关系 \(r\) 中每一个没有匹配到 \(s\) 中任何元组的元组 \(t_r\),直接将其输出,并在 \(s\) 对应的属性列填充
NULL值。 - 基于哈希连接(Hash Join)的左外连接:
- 当 \(r\) 作为探测关系时,只需在探测阶段输出所有未匹配到哈希表的 \(r\) 元组,并在 \(s\) 对应的属性列填充
NULL值。 - 当 \(r\) 作为构建关系时,需要额外记录哪些 \(r\) 元组被匹配到。在探测阶段,标记出与 \(s\) 元组匹配的 \(r\) 元组。当 \(s\) 的分区 \(s_i\) 处理完成后,将未被标记的 \(r\) 元组输出,并在 \(s\) 对应的属性列填充
NULL值。
- 当 \(r\) 作为探测关系时,只需在探测阶段输出所有未匹配到哈希表的 \(r\) 元组,并在 \(s\) 对应的属性列填充
- 基于归并连接(Merge Join)的左外连接:\(r - \Pi_R(r \bowtie s)\),在归并过程中,对于关系 \(r\) 中每一个没有匹配到 \(s\) 中任何元组的元组 \(t_r\),直接将其输出,并在 \(s\) 对应的属性列填充
6 Evaluation of Expressions¶
- 物化(Materialization):先计算表达式的结果,然后将结果物化,即存储到磁盘上,再继续计算后续操作。每一步操作的中间结果都需要写入磁盘,再由下一个操作读取。
优化方案:双缓冲(Double Buffering)
为每个操作分配两个输出缓冲区,当其中一个缓冲区写满时,将其写入磁盘;同时,另一个缓冲区继续接收新数据。
该方案让磁盘写入操作与 CPU 计算并行执行,减少整体执行时间,缓解 I/O 瓶颈。
- 流水线(Pipelining):在操作执行的过程中,一边生成元组,一边将元组传递给它的父操作,不需要等待整个操作完成再传递结果,避免了中间结果写入磁盘的开销。
- 优势:开销更低,省去了中间结果写入磁盘的 I/O 成本。
- 限制:不是所有场景都适用,比如排序、哈希连接这类阻塞型操作就无法直接使用。
流水线的执行分为两种模式:
- 需求驱动(Demand-Driven):父算子按需向子算子要下一个元组。两次请求之间操作必须维护自身的状态。又称为拉模型(Pull Model)或惰性求值(Lazy Evaluation)。
求驱动流水线的实现
需求驱动流水线的每个操作都会被实现为一个迭代器(iterator),该迭代器必须支持以下三个核心操作:
open():负责初始化迭代器的状态,为后续数据读取做准备。next():根据当前状态,计算并返回下一个元组,同时更新迭代器状态。close():在所有元组读取完成后,执行资源释放、状态清理等收尾工作。
- 生产者驱动(Producer-Driven):子算子主动把元组推给父算子。又称为推模型(Push Model)或积极流水线(Eager Pipelining)。
阻塞操作通常可以拆分为两个子阶段,我们可以把它们当作独立的操作来处理,从而适配流水线。
Pipelining for Continuous-Stream Data
- 数据流(Data streams):数据以持续、无界的方式进入数据库,例如传感器网络数据、用户点击流、实时日志等。
- 连续查询(Continuous queries):查询结果会随着新数据的流入持续更新,通常基于窗口聚合实现,例如滚动窗口(tumbling windows)将时间切分为固定单位(如小时、分钟),按窗口聚合数据。
- 流水线处理要求:必须使用流水线处理算法以实时响应数据流入
- 标点(Punctuations):一种特殊标记,用于通知系统某个窗口的所有数据已全部接收,触发窗口计算。