Chapter 7 Processes & Threads¶
1 Processes¶
1. 1 Process Concept¶
- 程序:被动实体,是存储在磁盘上的可执行文件(字节序列)
- 进程:程序的执行实例(主动实体),加载到内存后成为进程,是资源分配和保护的基本单位
- 多个进程可关联同一个程序,在共享服务器上,每个用户都可以启动同一个应用程序的实例(如文本编辑器、命令行终端)
- 一个运行中的系统由多个进程组成,如操作系统进程、用户进程
- 作业(job)、任务(task)与进程(process)在一般语境下可以互换使用,用来指代一个工作单元,但在不同系统语境下有着不同的含义
进程地址空间布局图
C 程序的内存布局图
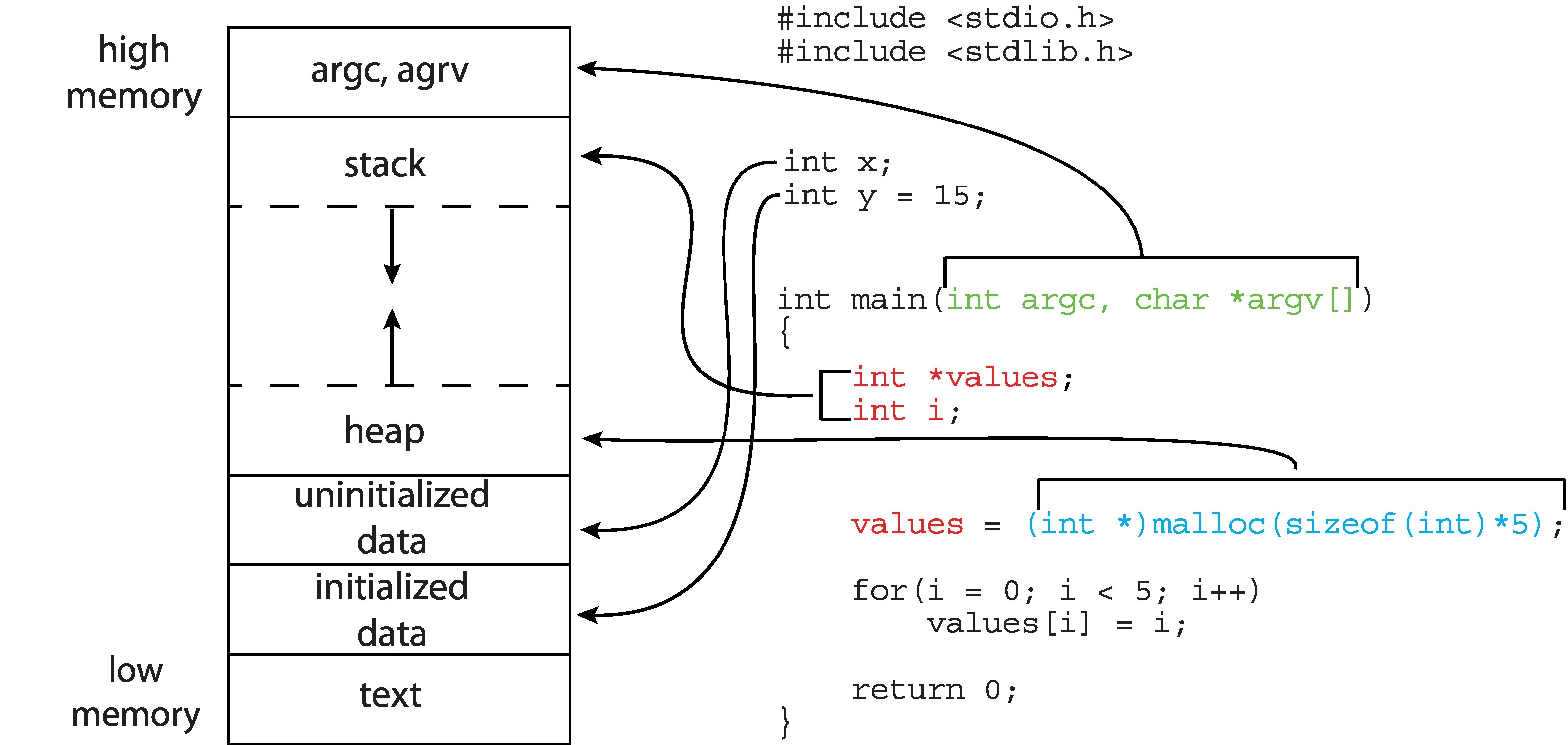
- 运行时栈(runtime stack):可执行压入或弹出操作的栈结构,是实现程序中连续函数/方法调用的机制,其管理完全由编译器自动完成
- 活动记录(activation records)/ 栈帧(stack frames):栈中的元素,包含了函数/方法调用的执行与返回所需的所有记录工作,包括函数参数、局部变量、返回地址、返回值、调用者寄存器状态等
- 调用序列越长,栈的规模就越大,栈过大可能达到某些系统指定的限制或触及堆的区域
- 栈向下增长,递归调用过深可能导致运行时栈溢出(runtime stack overflow),会触发内核终止进程
同一程序不同进程的内存分区对比图
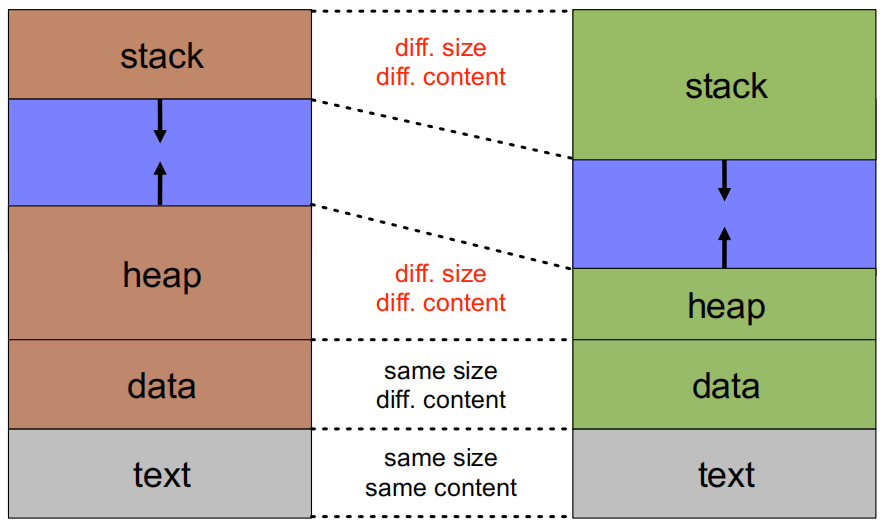
单任务与多任务操作系统的内存布局差异示意图
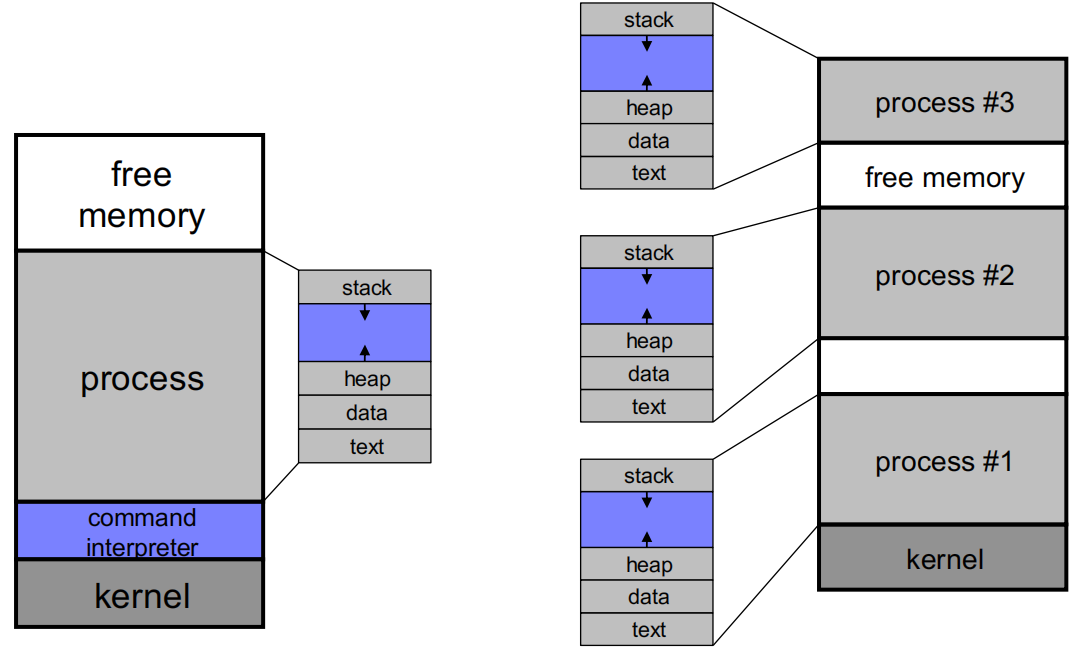
- 多任务 OS 通过创建新进程(如 Unix 的
fork())实现多程序并发,多个进程共享 CPU 和内存资源
1. 2 Process States¶
1. 2. 1 概览¶
| 状态 | 描述 |
|---|---|
| 新建(New) | 进程正在创建中 |
| 就绪(Ready) | 等待分配 CPU,已具备执行条件 |
| 运行(Running) | 指令正在 CPU 上执行 |
| 等待(Waiting) | 等待事件发生(如 I/O 完成、信号),释放 CPU |
| 终止(Terminated) | 进程执行完毕,资源待回收 |
状态转换关系图
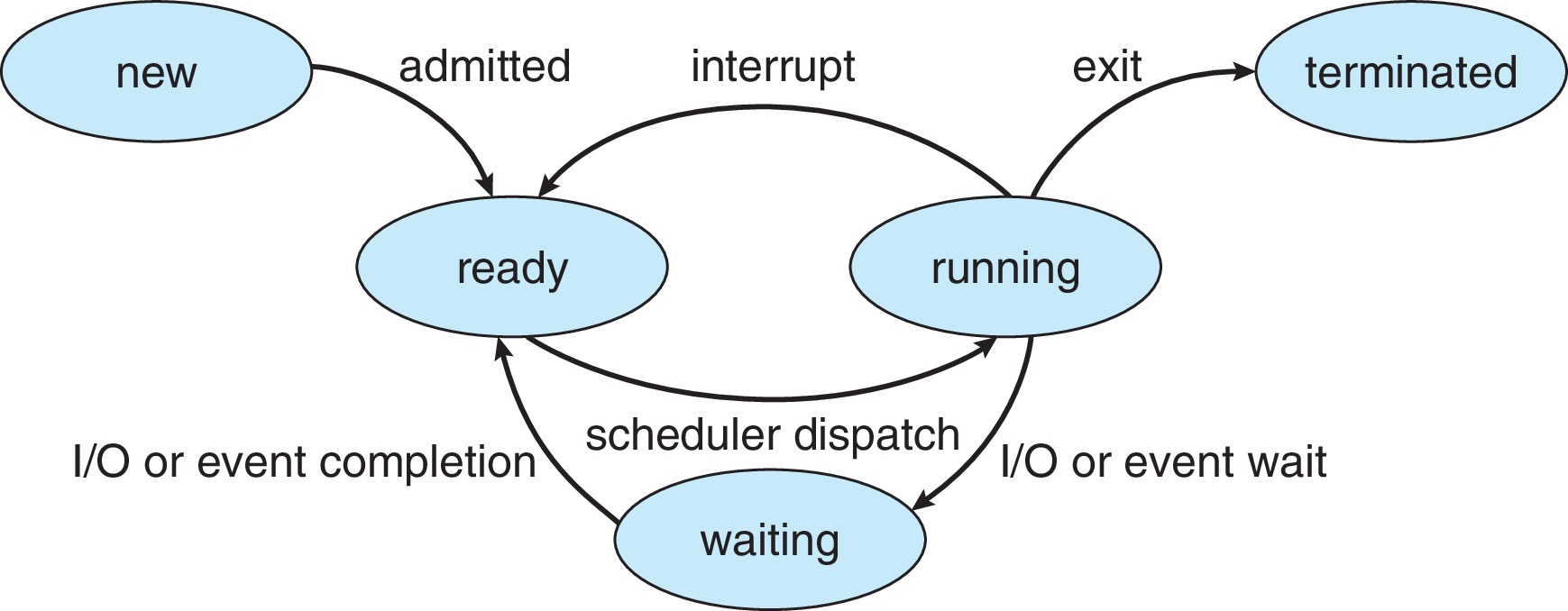
-
进程执行时会改变状态
-
进程控制块(PCB)存储了进程的所有关键信息,供操作系统管理进程,每个进程唯一对应一个PCB,创建时分配、终止时释放
PCB 的信息组成示意图

- 进程状态:运行/就绪/等待等
- 程序计数器(PC):下一条执行指令地址
- CPU 寄存器集合:进程当前寄存器状态
- CPU 调度信息:优先级、调度队列指针
- 内存管理信息:分配的内存地址空间
- 记账信息:CPU使用时间、进程启动后的流逝时钟时间、时间限制
- I/O 状态信息:打开的文件列表、分配的 I/O 设备
Process Representation (Linux)
在 Linux 中,每个进程/线程都用 task_struct 结构体描述,它包含了进程的所有关键信息:
pid_t pid; // 进程唯一标识 ID
long state; // 进程状态(-1不可运行/0可运行/>0停止)
unsigned int time_slice; // 调度剩余 CPU 时间片
struct task_struct *parent; // 父进程指针
struct list_head children; // 子进程链表头
struct files_struct *files; // 打开的文件列表
struct mm_struct *mm; // 进程虚拟地址空间描述
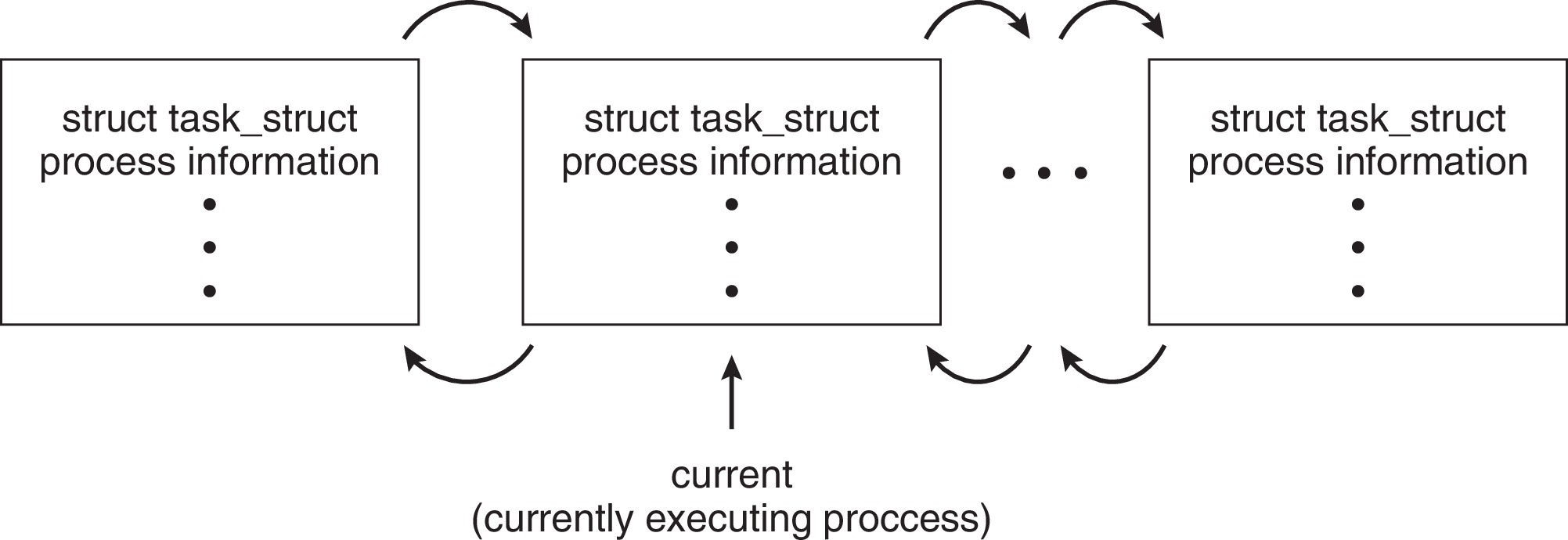
多个 task_struct 通过链表连接,current 表示当前正在执行的进程的 task_struct
struct task_struct {
// 宏:控制是否将 thread_info 内嵌到 task_struct
#ifdef CONFIG_THREAD_INFO_IN_TASK
// 因头文件依赖,thread_info 必须作为 task_struct 的第一个成员
struct thread_info thread_info;
#endif
volatile long state;
// 标记 task_struct 中可随机化字段的起始位置
randomized_struct_fields_start
void *stack; // 指向进程/线程的栈空间指针
refcount_t usage; // 进程引用计数:计数为 0 时可释放该结构体
};
thread_info 是存储线程/进程基础调度信息的结构体,有两种布局方式,current 是内核中用来快速获取当前正在执行进程的 task_struct 的宏,其实现方式也随着 thread_info 的布局而变化
thread_info 不在 task_struct 中 |
thread_info 在 task_struct 中 |
|
|---|---|---|
| 布局图 | 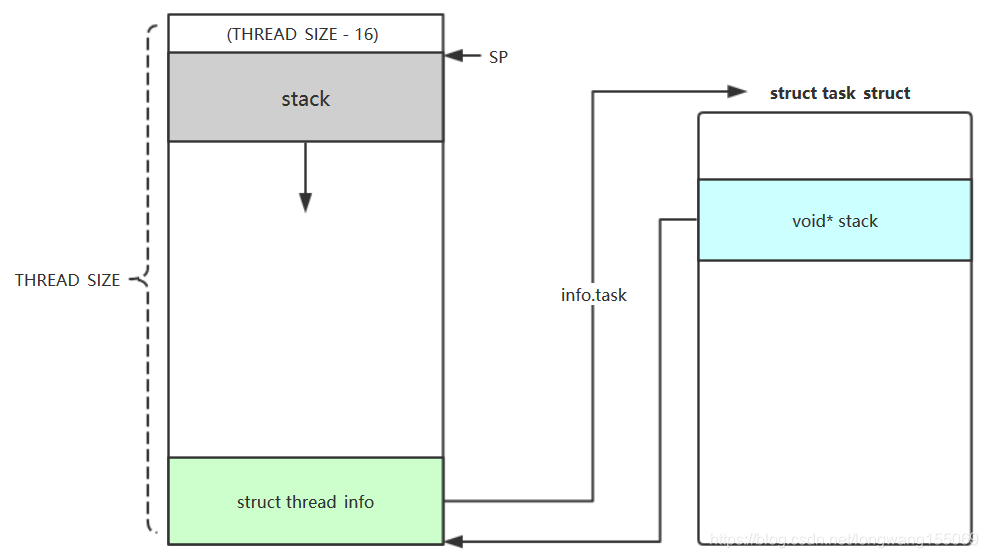 |
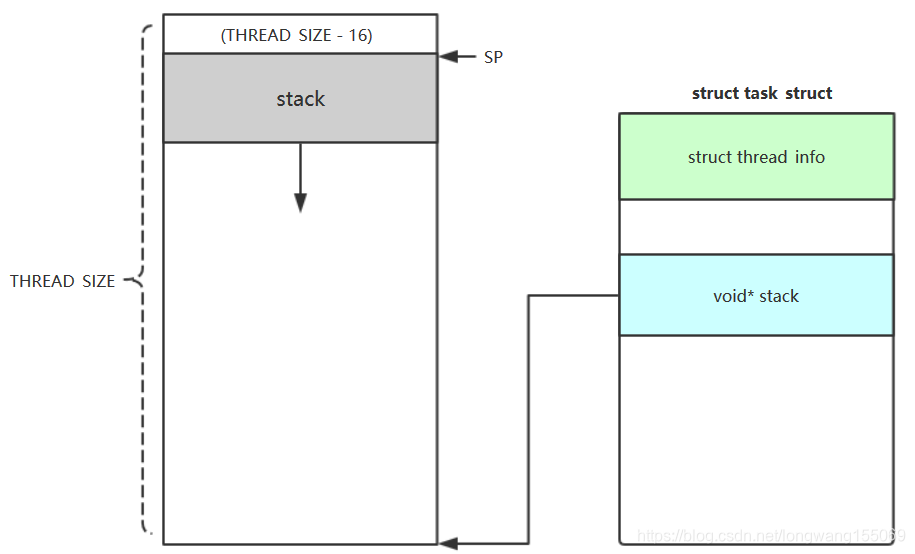 |
| 解释 | \(\textbf{·}\) 线程栈的总大小为 THREAD_SIZE,栈的底部存放 struct thread_info \(\textbf{·}\) thread_info 内有 task 指针,指向对应的 task_struct \(\textbf{·}\) 同时 task_struct 的 stack 指针指向栈的位置,实现 task_struct 和 thread_info 的双向关联 |
ARM64 架构下,task_struct 的开头直接包含 struct thread_info,栈指针直接关联到 task_struct 本身,无需通过thread_info间接关联 |
| current 宏 |  |
 |
| 解释 | \(\textbf{·}\) current_thread_info 函数:用当前栈指针与 ~(THREAD_SIZE-1) 做位运算,得到栈的起始地址,即 thread_info 的地址\(\textbf{·}\) get_current 宏:通过 thread_info->task 获取对应的 task_struct,最终 current 等价于这个 task_struct |
内核通过汇编指令 mrs %0, sp_el0 读取 SP_EL0 寄存器的值即当前 task_struct 的地址,直接返回该地址即可得到 current |
思考
当程序运行在用户空间时,SP_EL0 是用户空间栈的栈指针(SP)。那在内核空间中,SP_EL0 为何能被用作 current的存储载体呢?
答案
内核空间通常使用 SP_EL1 作为栈指针,从用户态切换到内核态后,SP_EL0 变为空闲,因此能用作存储 current
1. 2. 2 进程创建:fork()¶
前置知识
- 一个进程可以创建新的进程,此时它会成为父进程,由此我们会得到一个进程树,每个进程都有一个进程 ID(pid),ppid 指的是父进程的进程 ID
进程树示例图
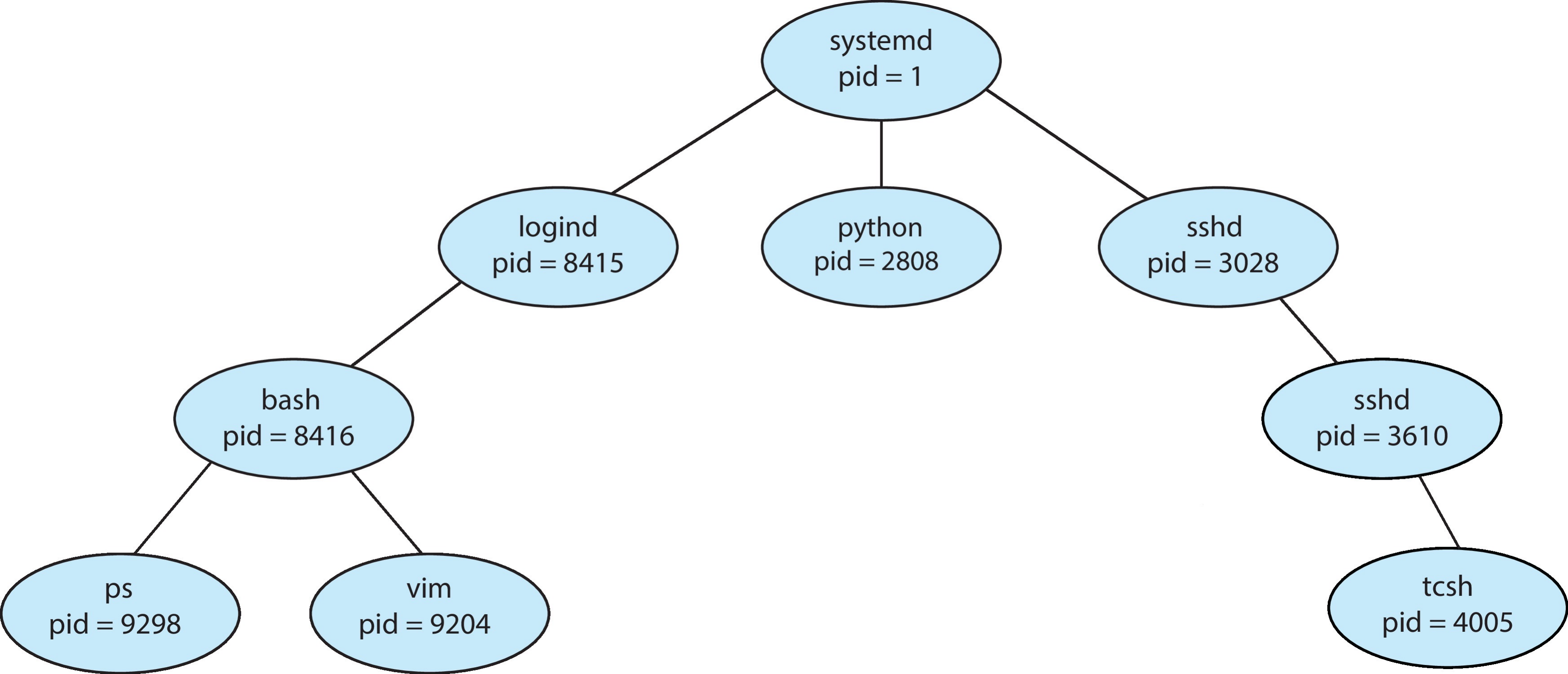
- 子进程可能会继承/共享父进程的部分资源,也可能拥有完全全新的资源
- 父进程也可以向子进程传递输入,在创建子进程后,父进程可以继续执行自身的任务,也可以等待子进程执行完成
- 子进程可以是父进程的克隆(即拥有父进程地址空间的副本),也可以是一个全新的程序
- 功能:创建一个新进程(子进程),子进程是父进程的副本(代码段、数据段、堆、栈初始相同),但进程 ID(pid, ppid)不同,资源使用率被初始化为 0
fork()会返回两次:给父进程返回子进程的 pid,给子进程返回 0,若失败则返回 -1,每个进程可以通过getpid()调用获取自身的pid,通过getppid()调用获取自身的ppid- 调用
fork()后,两个进程都会继续执行,新进程拥有独立的内存地址空间等资源,子进程修改全局变量不会影响父进程
What does the following code print?
int a = 12;
pid_t pid = fork();
If (pid == -1) {
fprintf(stdout,"Error: can't fork()\n");
perror("fork()");
}
if (pid > 0) { // PARENT
sleep(3); // ask the OS to put me in Waiting
fprintf(stdout,"a = %d\n",a);
while (1);
} else { // CHILD
a += 3;
while (1);
}
答案
a = 12
How many times does this code print "hello"?
pid1 = fork();
printf("hello\n");
pid2 = fork();
printf("hello\n");
答案
| 代码行 | 执行时的进程数 | 该步打印次数 |
|---|---|---|
| pid1 = fork(); | 1(仅 P0) | 0 |
| printf("hello\n"); | 2(P0、P1) | 2 |
| pid2 = fork(); | 2(P0、P1) | 0 |
| printf("hello\n"); | 4(P0、P1、P2、P3) | 4 |
故总共打印 6 次 hello
How many processes does this C program create?
int main (int argc, char *arg[])
{
fork();
if (fork ()) {
fork ();
}
fork ();
}
答案
| 代码行 | 执行进程数 | 新增进程数 |
|---|---|---|
第 1 个 fork() |
1(仅 P0) | 1(P0 新增 P1) |
if 内 fork() |
2(P0, P1) | 2(P0 新增 P2, P1 新增 P3) |
if 块内 fork() |
2(仅父进程 P0, P1) | 2(P0 新增 P4, P1 新增 P5) |
最后 1 个 fork() |
6(P0, P1, P2, P3, P4, P5) | 6 |
故最终产生 12 个进程
- 优点:简洁(Windows 的
CreateProcess需要 10 个参数);分工明确(fork搭建进程框架,exec为其赋予实际功能);能维持进程之间的关系。 - 缺点:复杂度较高,性能较差,存在安全问题
How does fork() return two values?
- 对于父进程来说,
fork()只是一个系统调用,和write调用类似 - 新进程 ID(new_pid)通过系统调用的返回值(保存在
pt_regs中)返回给父进程
1. 2. 3 进程镜像替换:exec*() 家族¶
- 功能:将当前进程的进程镜像(内存空间、代码、数据等)完全替换为指定程序的镜像,替换后进程 pid 不变,原进程的代码不会继续执行(除非
exec调用出错) - 内核接口:
execve()(系统调用),用户态包装函数execl/execle/execlp/execv/execvp等

使用示例
if (fork() == 0) { // 执行 ls -l ./
char *const argv[] = {“ls”, “-l”,”./”,NULL};
// 参数:可执行文件路径、命令行参数数组(以NULL结尾)、环境变量(可选)
execv(“/bin/ls”, argv);
}
为什么 strace 不会显示 fork?
fork是库函数包装器,底层调用 clone 系统调用,strace 跟踪系统调用,因此显示clone而非fork`
1. 2. 4 进程终止:exit()¶
- 进程通过
exit()系统调用自行终止,释放资源(物理内存与虚拟内存、已打开的文件、I/O缓冲区等),返回退出码(整数) - 一个进程可以通过信号和
kill()系统调用终止另一个进程
信号(Signals)
- 信号的本质是软件中断,异步通知进程处理事件(如终止、暂停、异常),可用于进程同步
- 大多数信号可以被忽略,或者通过用户编写的处理器来执行某些操作,但出于安全原因,
SIGKILL和SIGSTOP等信号无法被用户忽略或处理
Linux 系统中进程信号的编号与名称对应表
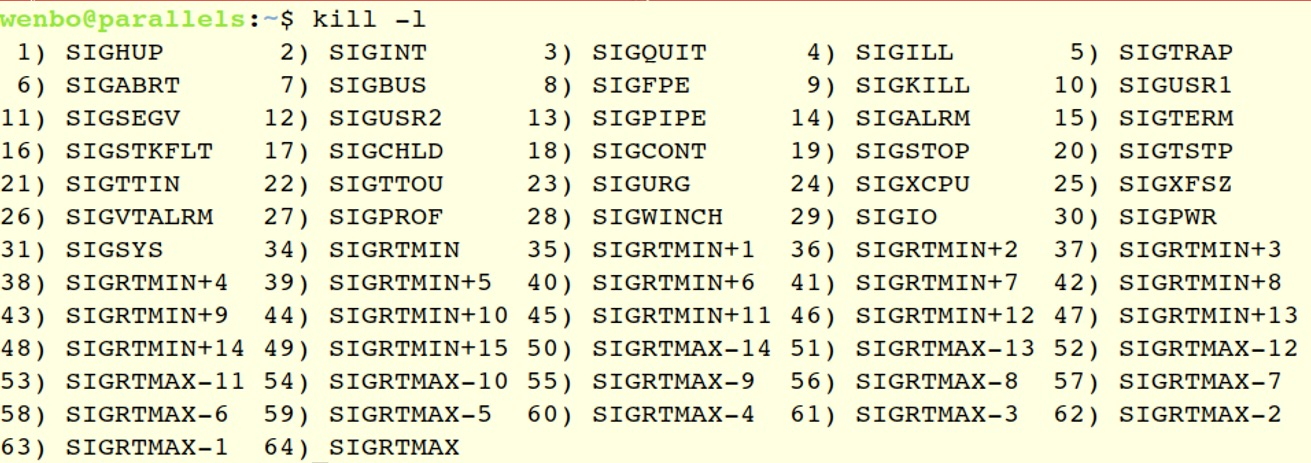
- SIGINT:键盘中断(Ctrl+C),默认终止
- SIGBUS:段错误
- SIGKILL:强制终止,不可忽略/处理
- SIGSTOP:暂停进程,不可忽略/处理
signal()系统调用允许进程指定收到信号时要执行的操作
信号处理函数示例
#include <signal.h>
#include <stdio.h>
// 自定义信号处理函数:参数 sig 用于接收触发函数的信号编号
void handler(int sig) {
fprintf(stdout,"I don't want to die!\n");
return;
}
main() {
// 忽略该信号
// signal(SIGINT, SIG_IGN);
// 将行为设为默认
// signal(SIGINT, SIG_DFL);
// 将 SIGINT 信号绑定到自定义 handler 函数
signal(SIGINT, handler);
// 无限循环:让程序持续运行,等待 SIGINT 信号触发(否则程序会直接退出)
while(1);
}
1. 2. 5 父进程等待子进程:wait()/waitpid()¶
- 避免子进程成为僵尸进程,回收子进程资源,获取退出码
| 系统调用 | 特性 |
|---|---|
wait() |
阻塞等待任意子进程终止,返回终止子进程 pid 及退出码 |
waitpid() |
可指定等待的子进程 pid,支持非阻塞(WNOHANG) |
进程控制代码示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#include <fcntl.h>
int main(int argc, char *argv[])
{
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed\n");
// 异常退出程序(退出码 1)
exit(1);
} else if (rc == 0) {
printf("hello, I am child (pid:%d)\n", (int) getpid());
// 关闭当前进程的标准输出(文件描述符 1)
// close(STDOUT_FILENO);
// 创建/打开文件 few.output,权限为只写、覆盖原有内容,文件权限是所有者可读可写可执行
// open("./few.output", O_CREAT | O_WRONLY | O_TRUNC, S_IRWXU);
char *myargs[3];
// 要执行的命令:wc(Unix 下统计文件行数/字数/字节数的工具)
myargs[0] = strdup("wc");
// wc 的参数:要统计的目标文件
myargs[1] = strdup("fork_exec_wait.c");
// execvp 要求参数数组以NULL结尾
myargs[2] = NULL;
// 执行 wc命令
execvp(myargs[0], myargs);
// 若 execvp 成功,这行代码永远不会执行(因为子进程已经被 wc 替换了)
printf("this shouldn't print out");
} else {
// 父进程等待子进程终止,NULL 表示不获取子进程的退出状态
int wc = wait(NULL);
printf("hello, I am parent of %d (wc:%d) (pid:%d)\n", rc, wc, (int) getpid());
}
return 0;
}
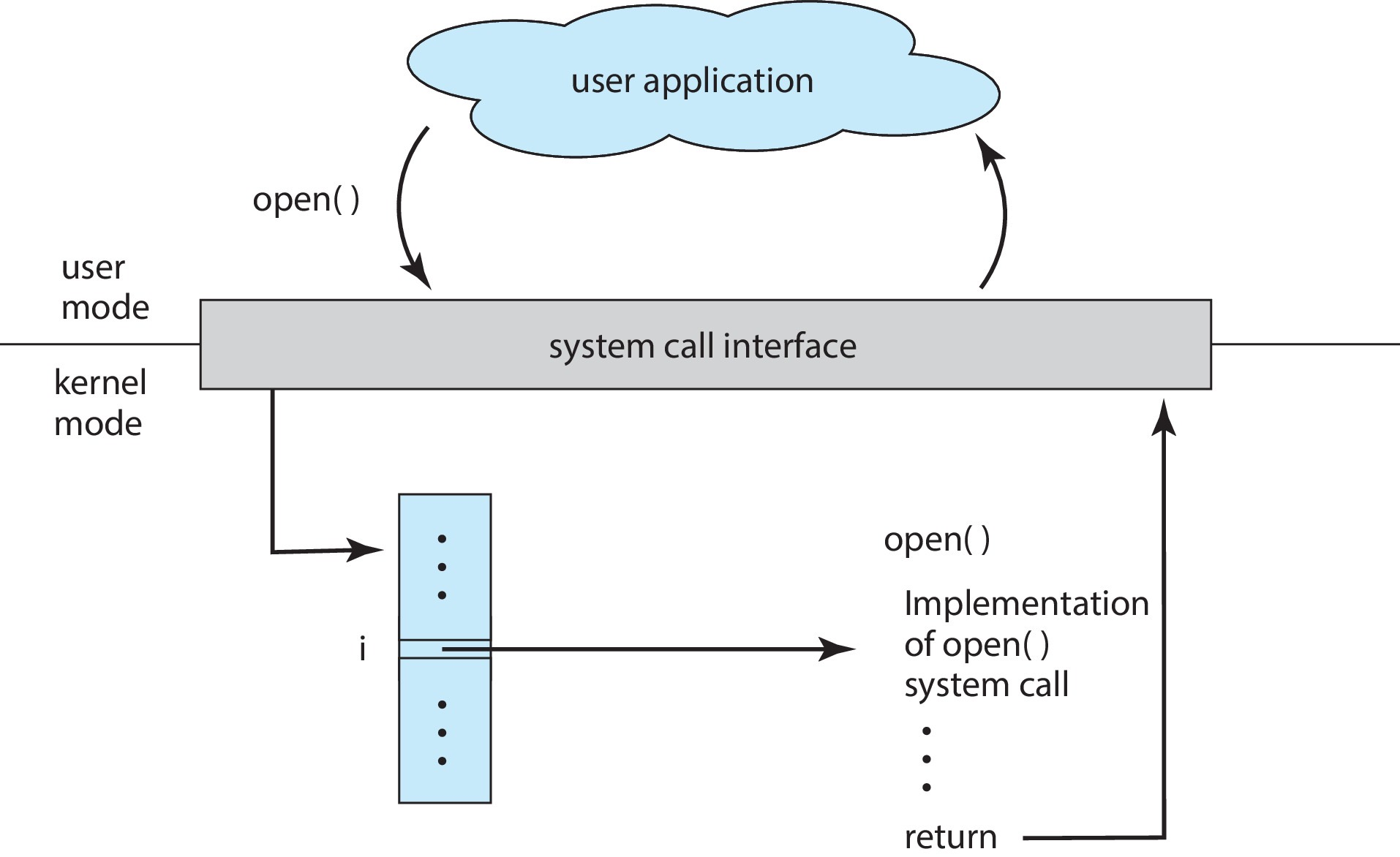
open() 系统调用
open() 会根据 pathname 打开指定文件,若指定文件不存在,open() 可以选择性地创建该文件。
open() 的返回值是一个文件描述符(一个小型的非负整数),后续系统调用会用它来指代已打开的文件,成功调用返回的文件描述符是当前进程中未打开的编号最小的文件描述符。
默认情况下,新的文件描述符会被设置为在 execve(2) 调用后仍保持打开状态(O_CLOEXEC 标志可以修改该默认设置),文件偏移量会被设为文件的起始位置。
调用 open() 会创建一个新的打开文件描述(open file description),它是系统级打开文件表中的一个条目,记录了文件偏移量和文件状态标志。文件描述符是对打开文件描述的一个引用,即便后续 pathname 被删除或修改,这个引用也不会受到影响。
1. 3 Process Scheduling¶
- 调度目标:最大化 CPU 利用率,快速切换进程至 CPU 核心,保证公平性和响应性
-
进程调度器(process scheduler)会从就绪进程中,选择下一个在 CPU 核心上执行的进程
进程调度的状态转换示意图
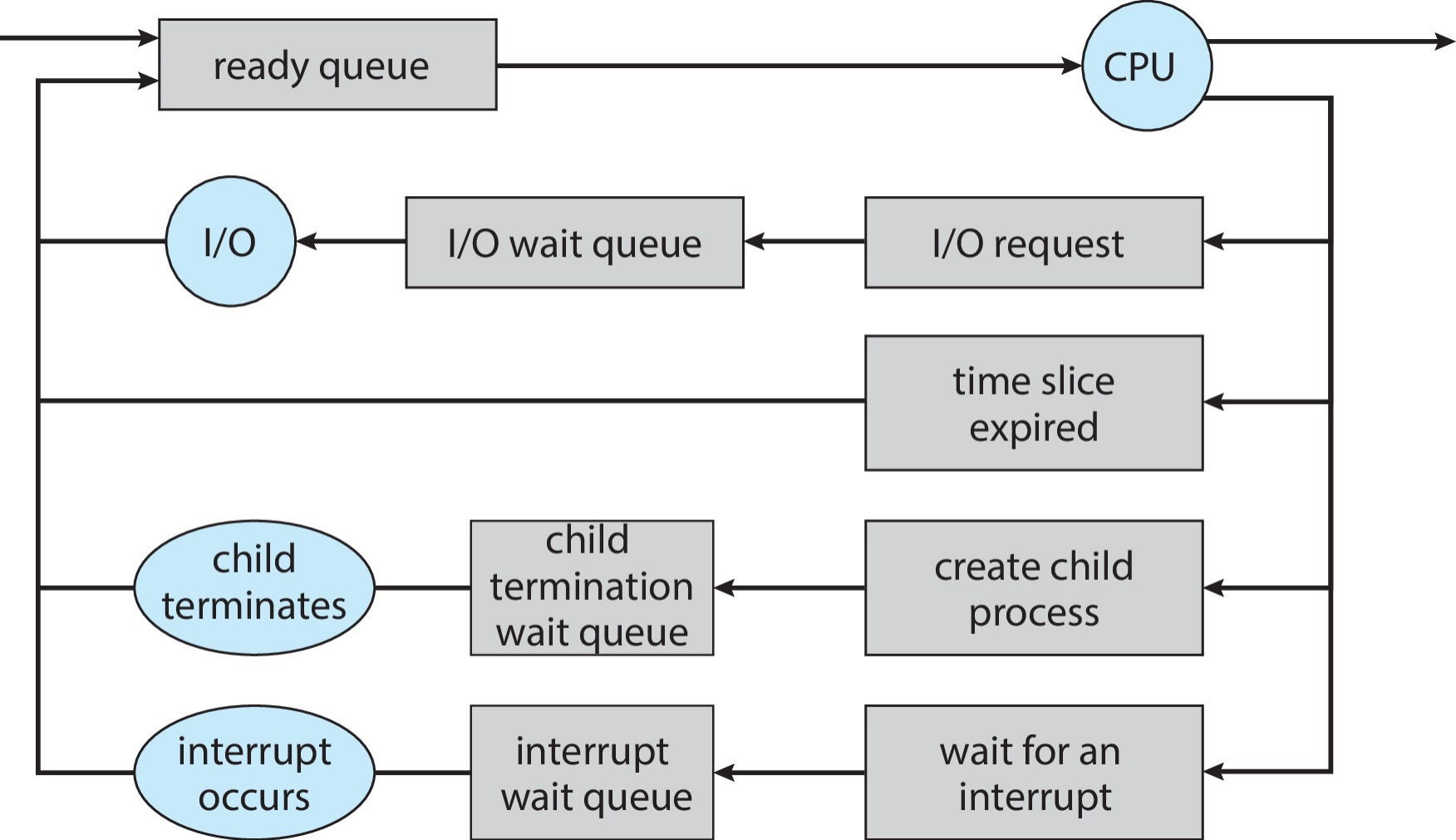
-
调度队列(scheduling queues)
- 就绪队列(ready queues):所有驻留在主存中、处于就绪状态并等待执行的进程集合
- 等待队列(wait queues):等待某个事件(如 I/O 操作)的进程集合
Ready and Wait Queues 示意图
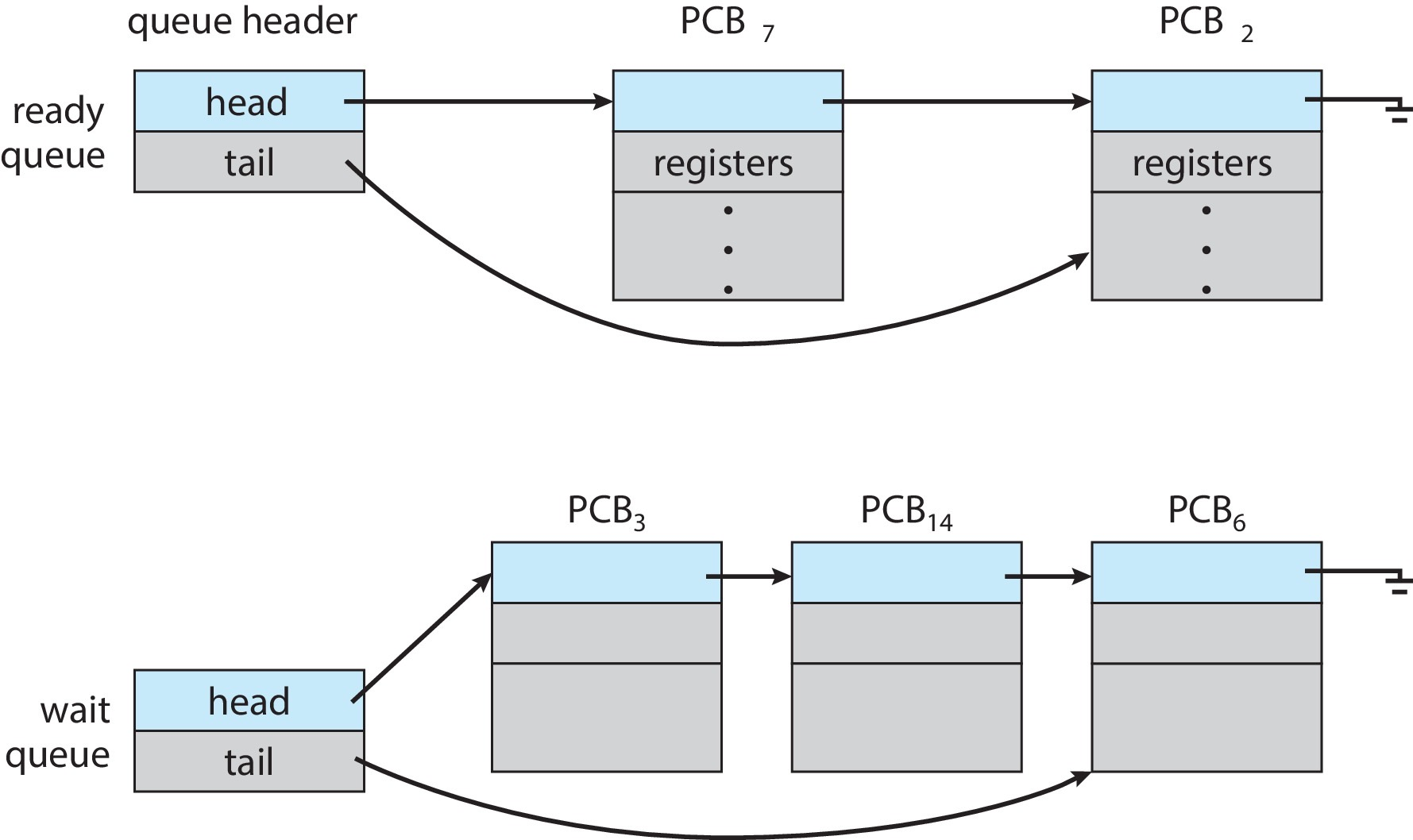
- 进程会在不同队列之间迁移
1. 4 Context Switch¶
进程上下文切换的流程示意图
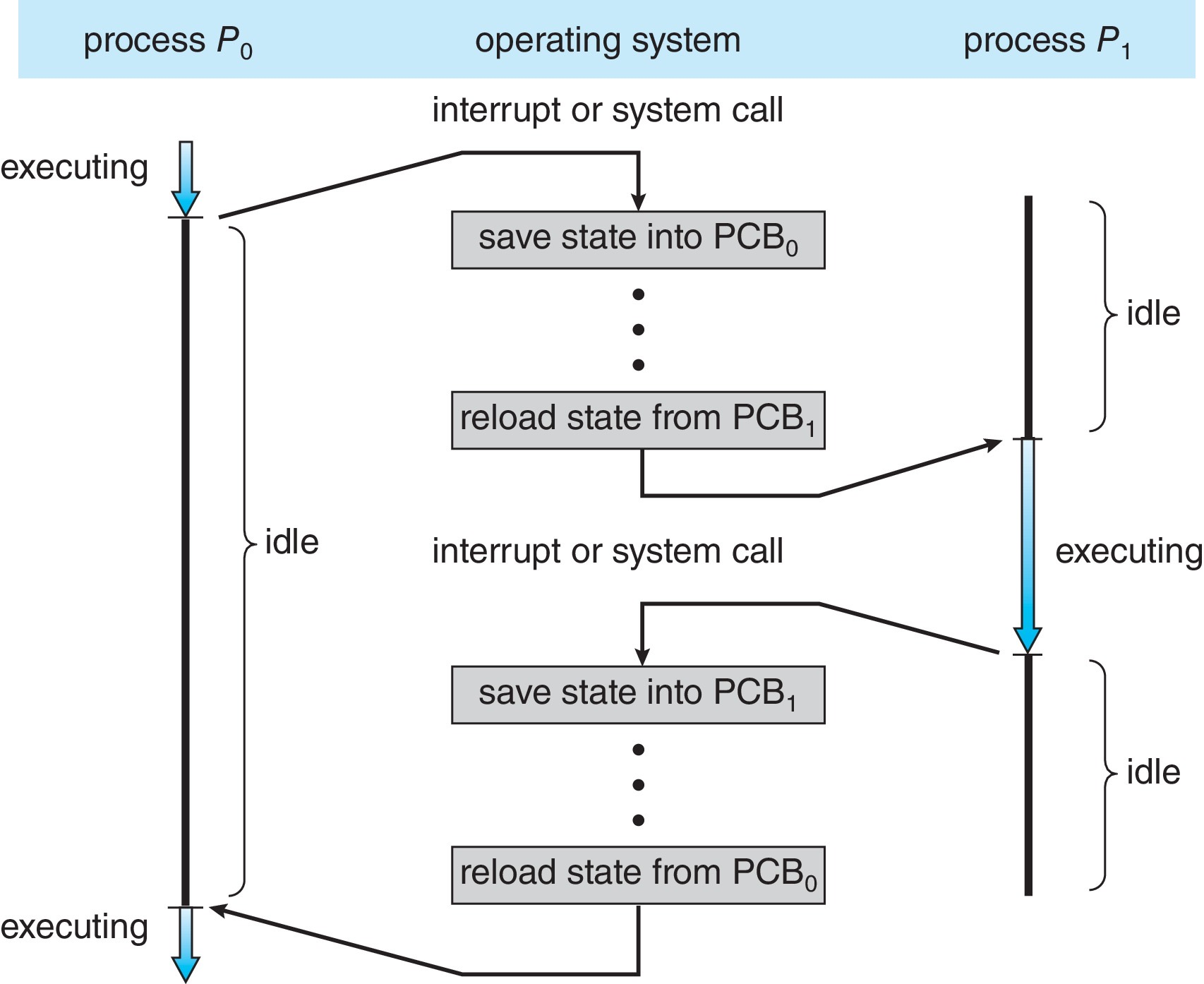
- CPU 从一个进程切换到另一个进程时,需要通过上下文切换(Context Switch)保存旧进程状态、加载新进程状态
- 进程的上下文由 PCB 表示
- 上下文切换的时间属于系统开销,切换过程中 CPU 不执行有用工作,OS 和 PCB 越复杂,上下文切换的时间越长
- 上下文切换的时间取决于硬件的支持,部分硬件会为每个 CPU 提供多组寄存器,以供一次性保存/加载多个上下文
Context Switch (ARM64)
extern struct task_struct *cpu_switch_to(struct task_struct *prev, struct task_struct *next);
ENTRY(cpu_switch_to)
mov x10, #THREAD_CPU_CONTEXT
add x8, x0, x10
mov x9, sp
stp x19, x20, [x8], #16
stp x21, x22, [x8], #16
stp x23, x24, [x8], #16
stp x25, x26, [x8], #16
stp x27, x28, [x8], #16
stp x29, x9, [x8], #16
str lr, [x8] ; 保存链接寄存器 lr。记录 prev 下次恢复时的返回地址
add x8, x1, x10
ldp x19, x20, [x8], #16
ldp x21, x22, [x8], #16
ldp x23, x24, [x8], #16
ldp x25, x26, [x8], #16
ldp x27, x28, [x8], #16
ldp x29, x9, [x8], #16
ldr lr, [x8] ; 恢复 lr
mov sp, x9 ; 切换 CPU 栈指针到 next 的sp
msr sp_el0, x1 ; 设置 EL0(用户态)栈指针为 next 的 task_struct 地址
ret ; 跳转到恢复的 lr 地址,执行 next 的代码,完成上下文切换
ENDPROC(cpu_switch_to)
前置知识
- 所有寄存器都运行内核代码的上下文称为内核上下文
- 上下文切换必须在内核态中进行
| 内核线程之间的上下文切换 | 用户线程之间的上下文切换 | |
|---|---|---|
| 保存时间 | context_switch 中的 cpu_switch_to 中 |
\(\textbf{·}\) 用户上下文寄存器:kernel_entry \(\textbf{·}\) 内核上下文寄存器: cpu_switch_to |
| 保存位置 | PCB 中的 thread_struct |
\(\textbf{·}\) 用户上下文寄存器:pt_regs \(\textbf{·}\) 内核上下文寄存器: thread_struct |
| 示意图 | 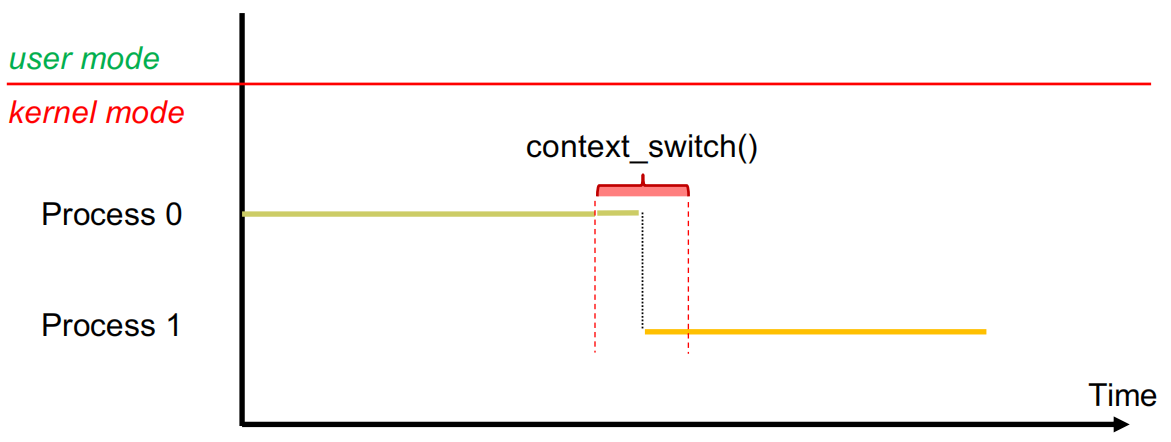 |
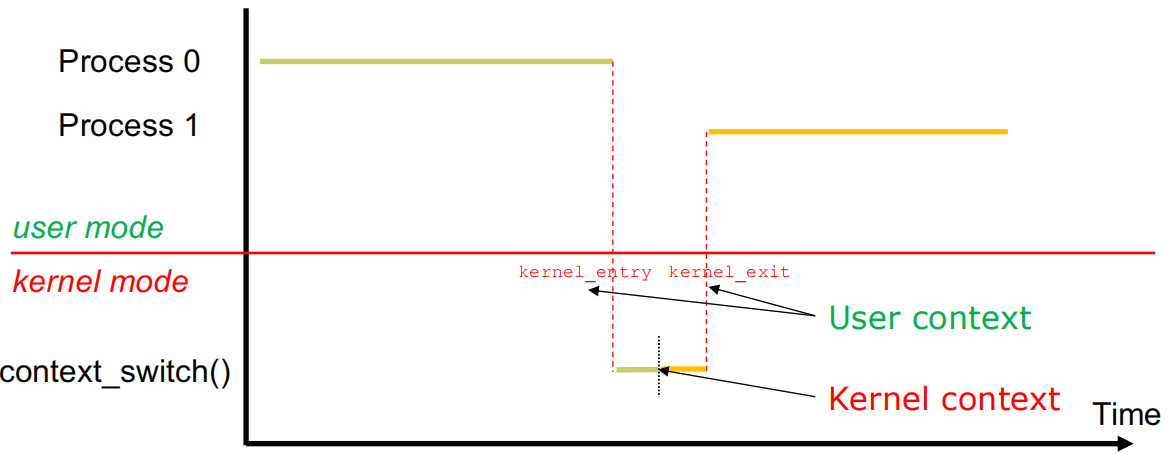 |
栈结构示意图
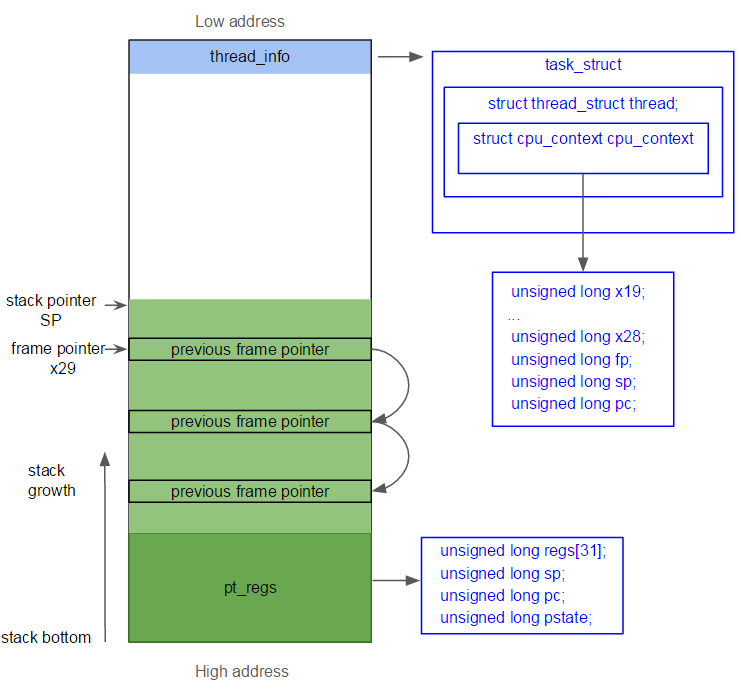
pt_regs:- 位于内核栈的高端,主要用于在用户态-内核态切换时保存用户寄存器
- 回到用户空间后,执行的第一条指令对应的地址是
pt_regs->pc
cpu_context:- 位于
task_struct->thread_struct中,主要用于保存上下文切换时的寄存器 - 上下文切换到某个进程后,会立即执行
cpu_context->pc对应的指令
- 位于
Where does cpu_switch_to() return to? When is the value set?
- 返回位置:
cpu_switch_to()会返回到它的调用者,最终回到调度函数schedule() - 返回值的生效场景:若进程 1 调用
schedule()主动放弃 CPU,当该进程后续被切回运行时,会直接返回到本次schedule()执行之后的位置
Linux 版本演进
| Linux 版本 | task_struct 相关 |
就绪队列 | 等待队列 |
|---|---|---|---|
| Linux 0.11(1991) | \(\textbf{·}\) 无链表概念 \(\textbf{·}\) 固定 PCB 表(最大64) |
\(\textbf{·}\) 无就绪队列 \(\textbf{·}\) 直接遍历 PCB 表选择下一个进程 |
\(\textbf{·}\) 无等待队列 \(\textbf{·}\) 使用固定数组 |
| Linux 2.3.0(1999) | \(\textbf{·}\) 引入链表 \(\textbf{·}\) 固定PCB表(最大512, struct task_struct *task[NR_TASKS]={&init_task,};) |
\(\textbf{·}\) 无名就绪队列(链表实现) \(\textbf{·}\) task_struct 含 prev_run/next_run 字段 \(\textbf{·}\) 遍历链表选择下一个进程 |
\(\textbf{·}\) 有名等待队列 \(\textbf{·}\) sleep_on 将 current 加入 motor_wait 的等待队列 |
| Linux 2.4.0(2001) | 数量可动态调整 | \(\textbf{·}\) 有名就绪队列(名为 runqueue_head,链表实现)\(\textbf{·}\) 用 task_struct->run_list \(\textbf{·}\) 通过 next_task/prev_task 链接进程 \(\textbf{·}\) 遍历链表选择下一个进程 |
\(\textbf{·}\) 有名等待队列 \(\textbf{·}\) sleep_on 将 current 加入 motor_wait 的等待队列 |
| Linux 2.6.0(2003) | 数量可动态调整 | \(\textbf{·}\) 有名就绪队列(名为 runqueue_head,用 struct runqueue 实现)\(\textbf{·}\) 用 task_struct->run_list \(\textbf{·}\) 通过 task_struct->sibling 链接进程 \(\textbf{·}\) 遍历优先级数组选择下一个进程 |
\(\textbf{·}\) 有名等待队列 \(\textbf{·}\) sleep_on 将 current 加入 motor_wait 的等待队列 |
| Linux 6.x(最新版本) | - | \(\textbf{·}\) 每个调度策略对应专用数据结构 \(\textbf{·}\)支持多种结构:链表、链表+数组、树 |
- |
1. 5 僵尸进程与孤儿进程¶
1. 5. 1 僵尸进程(Zombie)¶
- 当子进程终止时,若父进程未调用
wait()/waitpid()进行回收,子进程无法自行释放 PCB,会以僵尸进程的形式处于未完全消亡的状态 - 僵尸进程并非真正的进程,不会消耗 CPU 等资源,只会占用内存中的一个位置,最终可能会占满内存位置导致
fork()失败 - 僵尸进程会持续存在,直到其父进程为该子进程调用
wait()函数或其父进程终止 - 当子进程退出时,会向父进程发送一个 SIGCHLD 信号
- 父进程可为 SIGCHLD 信号关联一个调用
wait()的处理函数,确认所有子进程的终止状态
1. 5. 2 孤儿进程(Orphan)¶
- 产生原因:父进程先于子进程终止,子进程无父进程
- 处理机制:孤儿进程会被进程 ID(PID)为 1 的进程(Linux 系统中对应 init 进程,Mac OS X 系统中对应 launchd 进程)收养,该进程会通过 SIGCHLD 信号的处理函数(调用
wait())来处理子进程的终止,故孤儿进程永远不会变成僵尸进程 - 【Trick】创建完全独立于父进程的进程(父进程后续无需承担责任)
- 创建孙进程并终止其子进程,此时子进程会变成僵尸进程,父进程需要正确处理子进程的退出
2 IPC¶
2. 1 基本概念¶
进程分类
- 独立进程:不会影响其他进程的执行,也不会被其他进程的执行所影响
- 协作进程:可与其他进程相互影响(包括共享数据),存在协作需求
- 协作进程的原因:信息共享、计算加速、模块化、便利性、安全性
协作进程之间的通信方式被称为进程间通信(IPC, Inter-process Communication),有共享内存(Shared Memory) 和消息传递(Message Passing) 两种典型通信模型。
实际案例:Chrome 浏览器的多进程架构
谷歌 Chrome 浏览器采用多进程架构,解决了单进程浏览器一个页面故障导致整体崩溃的问题,包含 3 种不同类型的进程:
- 浏览器进程(Browser process):负责管理用户界面、磁盘及网络 I/O 操作
- 渲染进程(Renderer process):每个网站独立创建,负责渲染网页,处理 HTML、JavaScript,运行在沙箱环境中(限制磁盘与网络 I/O 操作,降低安全风险)
- 插件进程(Plug-in process):每种插件对应一个独立的插件进程
| 共享内存(Shared Memory) | 消息传递(Message Passing) | |
|---|---|---|
| 核心原理 | 进程共享一块内存区域,直接读写该区域 | 进程通过发送/接收消息通信,不共享地址空间 |
| 系统开销 | 低:初始少量系统调用,后续无额外开销 | 高:每次通信都需系统调用 |
| 用户使用便捷性 | 高:类似操作 RAM,符合常规读写习惯 | 较低:代码需嵌入 send/recv 操作,略显繁琐 |
| 操作系统实现难度 | 高:需打破内存隔离的核心抽象 | 低:维持内存隔离,逻辑简单 |
| 适用场景 | 大量数据交换 | 少量数据交换、分布式场景(跨主机) |
2. 2 共享内存模型¶
- 由一个进程创建共享内存段后,其他进程可以将该内存段附加到自身地址空间,这与多道程序设计的内存保护理念完全相悖
- 进程通过对共享内存区域进行读写来实现通信,操作系统不参与中间过程
- 需用户自行保证进程间同步(避免读写冲突),确保进程间互不干扰
Producer-Consumer Problem
Producer-Consumer 是协作进程的典型模式,生产者进程生成信息,供消费者进程消费,有无界缓冲区(对缓冲区的大小没有实际限制)和有界缓冲区(缓冲区大小固定)两种实现方式。
有界缓冲区实现代码示例
#define BUFFER_SIZE 10
typedef struct {} item;
item buffer[BUFFER_SIZE];
int in = 0; // 生产者写入位置
int out = 0; // 消费者读取位置
// 生产者逻辑:生成数据并放入缓冲区
item next_produced;
while (true) {
produce_item(&next_produced);
// 缓冲区满则等待
while (((in + 1) % BUFFER_SIZE) == out);
buffer[in] = next_produced;
in = (in + 1) % BUFFER_SIZE;
}
// 消费者逻辑:从缓冲区取出数据并消费
item next_consumed;
while (true) {
// 缓冲区空则等待
while (in == out);
next_consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
consume_item(&next_consumed);
}
POSIX 共享内存
// 1. 创建共享内存段(IPC_PRIVATE 表示私有,指定读写权限)
int id = shmget(IPC_PRIVATE, size, IPC_R | IPC_W);
// 2. 附加到当前进程地址空间
char *shared_memory = (char *)shmat(id, NULL, 0);
// 3. 向共享内存读写数据
sprintf(shared_memory, "hello");
// 4. 脱离共享内存
shmdt(shared_memory);
// 5. 彻底删除共享内存段
shmctl(id, IPC_RMID, NULL);
- 进程获知共享内存段的 ID 没有通用的解决方案
- 在
posix_shm_example.c中,ID 是在fork()之前创建的,这样父进程和子进程都能获取到它 - ID 可以作为命令行参数传递,也可以存储在文件中,还可以通过消息传递来通信
- 在
- 在支持 POSIX 的系统上,可以用
ipcs -a命令查看 IPC 的状态 - 使用 shm ipcs 的代码相当繁琐,因此共享内存类型的代码现在很少被使用,但进程在底层仍然会共享内存(如标准库函数的代码段),在多个运行上下文之间,共享内存是通过线程实现的
2. 3 消息传递模型¶
- 维持内存隔离抽象,进程无共享地址空间
- 有
send(发送消息)和recv(接收消息)两个基本操作 - 消息传递是分布式计算的核心机制(不同主机上的进程无法共享物理内存),在同一主机内的进程通信中也十分实用
- 进程间通信需先建立通信链路(communication link),可通过多种方式实现,甚至可以基于共享内存来实现
- 物理层面:共享内存,硬件总线,网络
- 逻辑层面:直接式或间接式,同步式或异步式,自动缓冲或显式缓冲
| Direct Communication | Indirect Communication | |
|---|---|---|
| 核心逻辑 | 进程必须明确指定彼此的名称 | 消息通过邮箱/端口(mailboxes/ports)进行收发,邮箱 ID 唯一,进程共享邮箱即可通信 |
| 使用示例 | send(P, message), receive(Q, message) |
send(A, message), receive(A, message) |
| 链路特性 | 链路自动建立,一对一关联,通常双向 | 链路需共享邮箱建立,支持多进程关联,可多链路通信,支持单向/双向 |
多进程共享邮箱时,如何确认消息接收者?
a. 限制一条链路最多关联 2 个进程
b. 同一时间仅允许一个进程执行接收操作
c. 由系统随机选择接收进程,并通知发送方具体接收者是谁
| 阻塞/同步(blocking/synchronous) | 非阻塞式/异步(Non-blocking/asynchronous) | |
|---|---|---|
send() |
sender 会被阻塞,直到消息被接收 | sender 发送消息后继续执行后续操作 |
recv() |
receiver 会被阻塞,直到有消息可用 | receiver 接受有效消息或空消息 |
阻塞式(同步)IPC 示例代码
// 生产者调用阻塞式的 send() 函数,等待消息被传递到接收方或邮箱
message next_produced;
while (true) {
/* 生产一个内容并存入 next_produced */
send(next_produced);
}
// 消费者调用 `receive()`,阻塞直到有消息可用
message next_consumed;
while (true) {
receive(next_consumed);
/* 消费 next_consumed 中的内容 */
}
| 缓冲类型 | 容量特点 | 发送方行为 |
|---|---|---|
| 零容量(Zero capacity) | 链路上无消息排队 | 必须等待接收方 |
| 有界容量(Bounded capacity) | 有限长度(可容纳 n 条消息) | 若链路已满,必须等待 |
| 无界容量(Unbounded capacity) | 无限长度 | 无需等待 |
2. 4 典型 IPC 技术¶
典型 IPC 技术
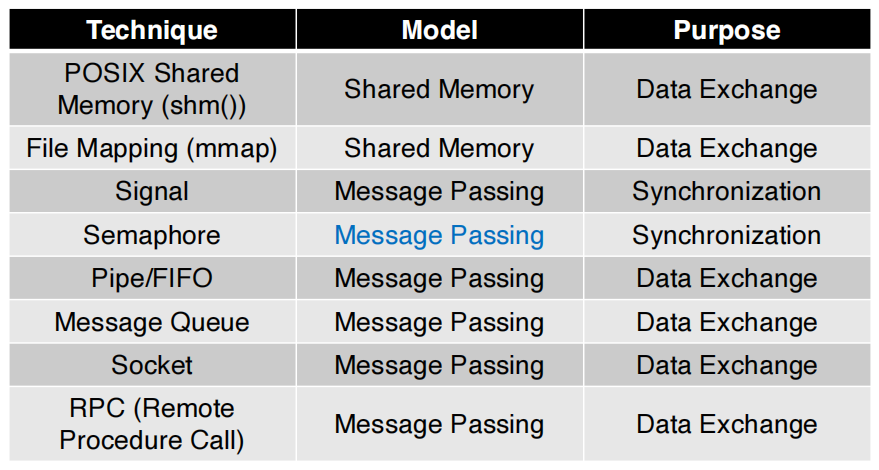
2. 4. 1 管道(Pipe)¶
- 允许两个进程进行通信的简单管道(conduit)
半双工和全双工
- 半双工(Half-Duplex):同一时间只能单向传输数据
- 全双工(Full-Duplex):同一时间可以双向传输数据
| 类型 | 普通管道(Ordinary Pipe) | 命名管道(Named Pipe) |
|---|---|---|
| 通信方向 | 管道本身是单向的,但建立两个即可实现半双工通信 | 半双工通信 |
| 进程关系 | 进程之间必须存在父子进程关系,fd[0] 是读端,fd[1] 是写端 |
无需存在父子进程关系 |
| 跨网络支持 | 不支持 | \(\textbf{·}\) 在 Windows 环境下可通过 SMB 协议实现跨网络访问 \(\textbf{·}\) 在 Linux/Unix 及通用网络编程中不支持跨网络,仅用于本地进程间通信 |
| 系统支持 | UNIX、Windows 均支持,被称为匿名管道 | UNIX、Windows 均支持,在 UNIX/Linux 系统中被称为 FIFO |
UNIX 管道
- 在 UNIX 中,管道是单向的,包含写端和读端两个部分,若要实现双向通信,必须使用两个管道
- 命令行中用
|表示,如ls | grep foo表示 ls 写管道,grep 读管道 - 双向通信需两个管道,支持多管道串联,如
ls -R | grep foo | grep -v bar | wc -l
2. 4. 2 套接字(Socket)¶
客户端-服务器通信(Client-Server Communication)
应用程序通常被构建为一组通信进程,常见于跨机器场景(如 Web 浏览器与 Web 服务器),也能在单台机器内的进程间使用,下面将介绍 3 种常用的通信方式:套接字(Sockets)、远程过程调用(RPCs)和 Java 远程方法调用(Java RMI)。
- 包含两个端点的通信抽象,可供两个进程进行通信,由 IP 地址 + 端口号 唯一标识
- 通常用于跨主机通信(网络编程核心),也支持本机进程通信
2. 4. 3 远程过程调用(RPC, Remote Procedure Calls)¶
- 将远程函数调用抽象为本地调用,隐藏消息传递细节
- 由客户端存根(Client Stub)实现,功能如下:
- 编组(Marshal):将结构化参数转换为字节流
- 发送请求至服务器并等待响应
- 解组(Unmarshal):将字节流还原为结构化返回值
- RPC 调用失败可能导致 RPC 被部分执行或 RPC 因不必要的重试被多次执行
- RPC 语义
- 最多一次(弱语义):服务器通过记录入站消息的时间戳过滤重复请求,避免重复执行,但服务器可能始终不执行该操作
- 恰好一次(强语义):服务器执行后发送确认(ack),客户端重试直到收到确认(实现复杂)
2. 4. 4 Java 远程方法调用(Java RMI)¶
- 本质是面向对象的 Java 版 RPC,支持跨 JVM 方法调用
- JVM 会自动处理参数编组/解组,对象会通过
java.io.Serializable接口实现序列化和反序列化 - 支持本地对象拷贝传递和远程对象引用传递
- 隐藏 IPC 底层细节,便捷性高,但功能与 Socket 等价
3 Threads¶
Why Threads?
- 应用程序的多项任务可以通过线程来实现,如更新显示、获取数据、拼写检查、响应网络请求等
- 进程的创建是重量级的(需分配独立的全套资源),而线程的创建是轻量级的(线程共享所属进程的大部分资源,创建线程时只需分配线程私有资源,如线程栈、寄存器上下文、线程控制块 TCB 等)
- 线程能够简化代码、提升效率
3. 1 基本概念¶
- 线程是进程内的基本执行单元,一个进程可包含多个线程
- 线程共享进程的大部分资源(如代码段、数据段、堆、已打开的文件与信号等),仅维护自身必要的执行状态(如线程 ID、PC、寄存器组、栈等)
单线程与多线程进程的资源结构对比图
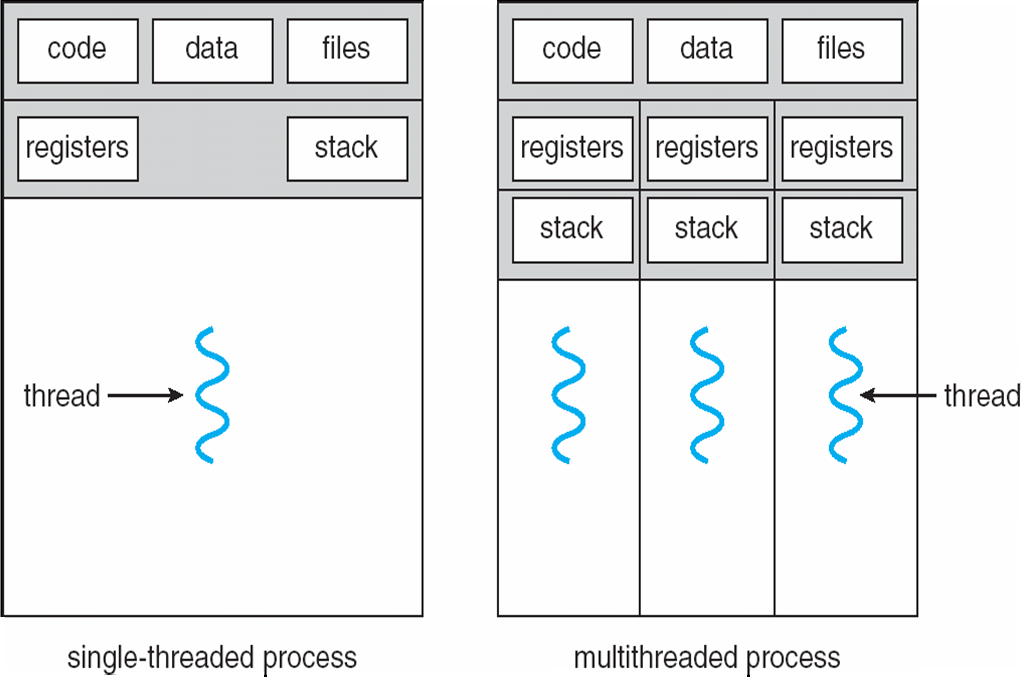
多线程进程的资源分布详细视图
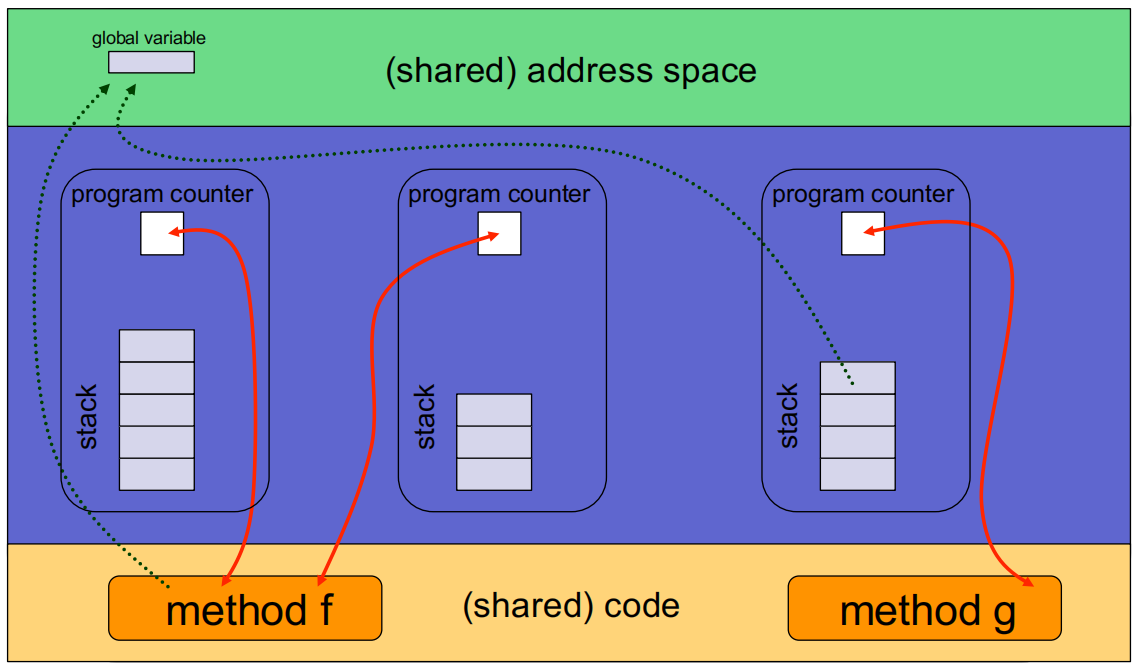
-
优点:
- 经济性:创建线程比进程成本低(无需重新分配代码/数据/堆);线程上下文切换无需刷新缓存,比进程切换高效
- 资源共享:天然共享进程内存空间,无需使用 IPC,在同一地址空间中实现并发活动的能力非常强大
- 响应性:并发活动的程序响应性强,一个线程阻塞时其他线程可继续执行,相比进程具备更优的资源共享性与开销优势
客户端-服务器架构中线程处理请求的流程示意图
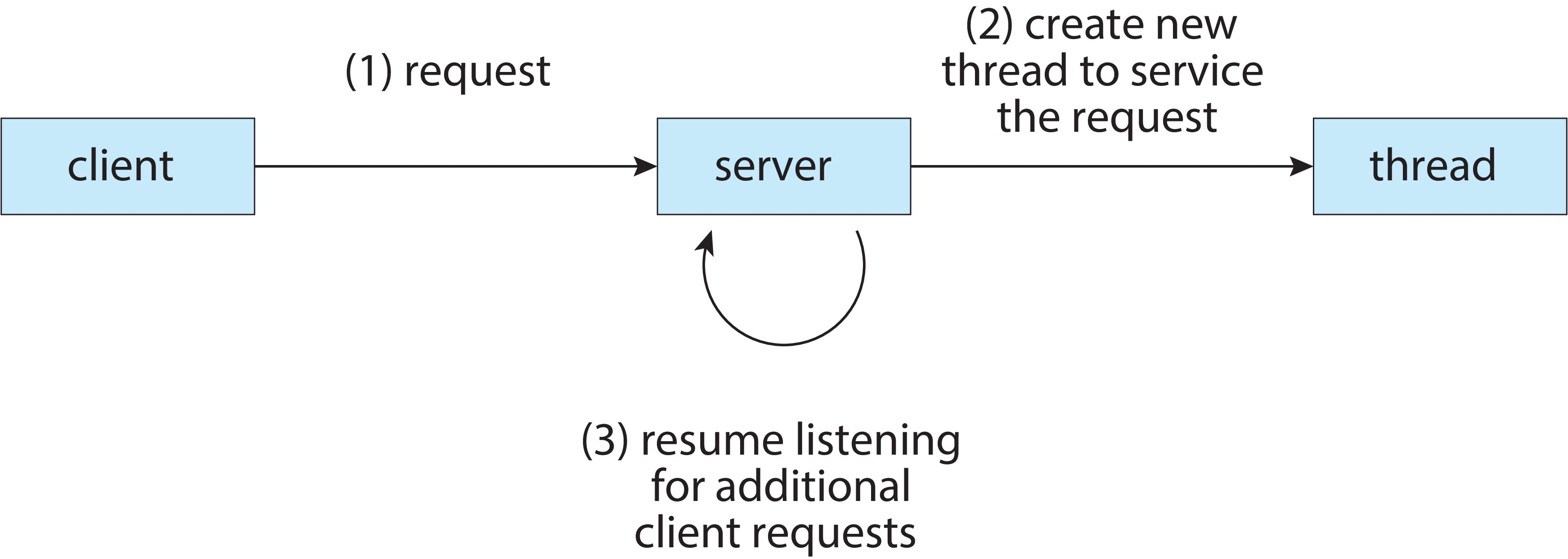
- 服务器无需等待请求处理完成,直接恢复监听新的客户端请求,借助线程实现了处理请求与监听新请求的并发,让服务端更高效、响应更快
NGINX 中线程池的工作机制
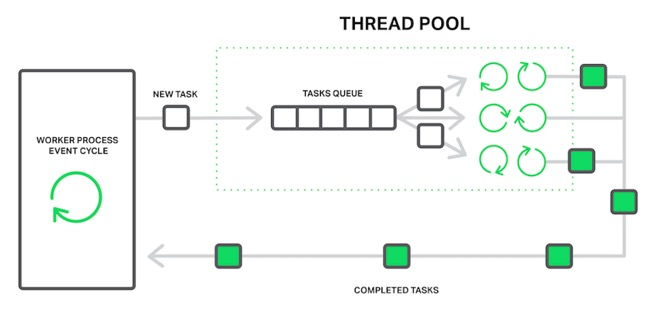
- 工作进程不用阻塞等待任务完成,可继续处理新事件,线程池复用已创建的线程(避免频繁创建 / 销毁线程的开销),实现轻量、高效的并发处理,提升性能
- 可扩展性:多核心环境下,多线程可并行执行,充分利用硬件资源,相比进程具备更优的资源共享性与开销优势
-
缺点:
- 弱隔离性:单个线程崩溃(如段错误)会导致整个进程终止(Chrome 浏览器用采用多进程并发实现标签页隔离)
- 内存限制:受单个进程地址空间大小限制(64 位架构已基本解决该问题)
- 无内存保护:并发编程难度高(但进程结合共享内存段的并发编程同样难度不小)
| 并发执行(Concurrency) | 并行执行(Parallelism) | |
|---|---|---|
| 定义 | 独立执行进程(广义概念,非 Linux 进程)的组合式编程 | (可能相关的)计算任务的同时执行式编程 |
| 执行方式 | 单核通过分时切换多个任务(如 T₁/T₂/T₃/T₄ 交替执行),是看起来同时处理 | 多核同时执行不同任务(如 core1 跑 T₁/T₃、core2 跑 T₂/T₄),是实际同时处理 |
| 核心目标 | 同时处理(dealing with)多件事 | 同时做(doing)很多事 |
| 侧重方向 | 侧重结构设计(用并发结构组织任务) | 侧重执行效率(用多核同时执行任务) |
| 关联关系 | 是一种问题解决方案的结构,可能支持并行(但不是必须) | 是并发结构的一种执行方式,二者相关但不相同 |
| 示意图 |  |
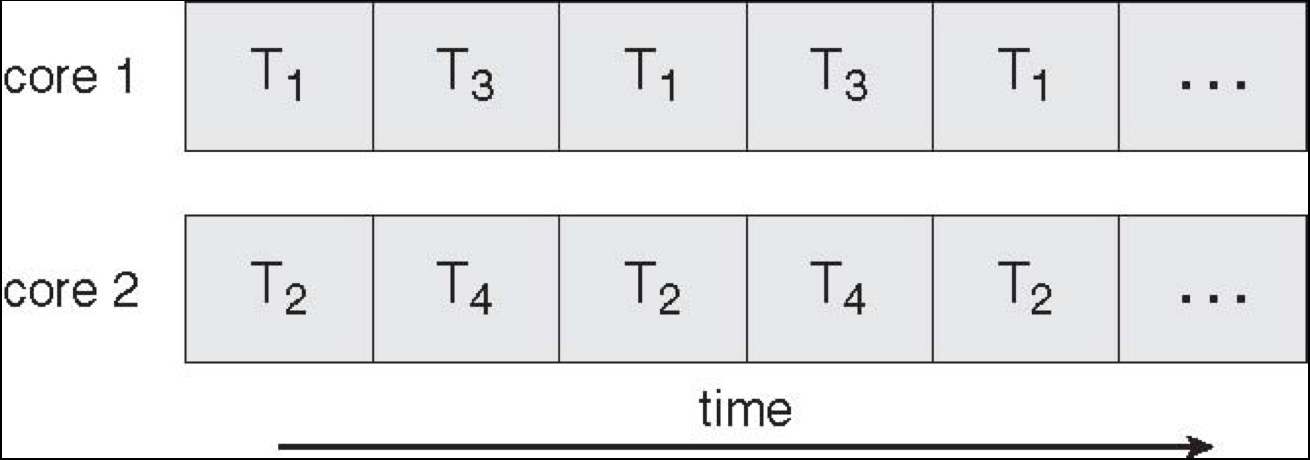 |
3. 2 线程实现模型¶
| 内核级线程(Kernel-level Threads) | 用户级线程(User-level Threads) | |
|---|---|---|
| 定义 | 由操作系统内核直接支持和管理,内核统一维护线程表(TCB, thread control block)并提供系统调用以供线程的创建和管理 | 完全由运行时系统(用户级库)管理,内核无感知,仅将进程视为单线程 |
| 优点 | 内核知晓所有线程,可优化调度,给多线程进程分配更多时间片,适合频繁阻塞的应用 | \(\textbf{·}\) 可在不支持线程的 OS 上实现,无需修改 OS \(\textbf{·}\) 线程表示简单,仅由 PC、寄存器、栈和小型控制块表示,且都存储在用户进程的地址空间中 \(\textbf{·}\) 线程操作(创建/切换)无需内核干预,速度快(接近函数调用),适合细粒度并发场景 |
| 缺点 | 运行缓慢且低效;内核复杂度增加(需维护 TCB) | \(\textbf{·}\) 内核无法感知用户级线程,与 OS 的集成度差,可能作出糟糕的调度决策(如调度包含空闲线程的进程、某一线程发起 I/O 操作时阻塞整个进程;或取消持有锁的线程的调度) \(\textbf{·}\) 线程与内核缺乏协调,进程整体获一个时间片,线程的控制权需要主动让渡给其他线程 \(\textbf{·}\) 依赖非阻塞系统调用(即需要多线程内核),否则一个线程阻塞会导致整个进程阻塞 |
| 模型 | Many-to-One | One-to-One | Many-to-Many | Two-Level |
|---|---|---|---|---|
| 特点 | 多个用户线程映射到 1 个内核线程 | 1 个用户线程映射到 1 个内核线程 | 多个用户线程映射到多个内核线程 | 多对多基础上,支持用户线程绑定内核线程 |
| 优点 | 低开销,无系统调用 | 支持多核心,无整体阻塞 | \(\textbf{·}\) 平衡开销与并行性 \(\textbf{·}\) 一个线程阻塞时内核可创建新的内核线程,避免整体阻塞 \(\textbf{·}\) 新建用户线程不一定需要创建新的内核线程 \(\textbf{·}\) 可在多核机器上实现真正的并发 |
灵活优化关键线程 |
| 缺点 | \(\textbf{·}\) 无法利用多核心 \(\textbf{·}\) 一个线程阻塞则全阻塞 |
线程创建/切换需内核干预,开销较高,速度较慢 | 实现复杂 | 实现复杂 |
3. 3 Thread Libraries¶
-
Pthreads
- 遵循 POSIX 标准(IEEE 1003.1c)的 API,用于线程的创建与同步,仅定义行为,不规定实现(可用户级/内核级)
- 适用于 C/C++ 中的 UNIX 类系统(Linux、Mac OS X)
代码示例
单线程累加求和#include <pthread.h> #include <stdio.h> #include <stdlib.h> int sum; // 共享变量 void *runner(void *param); // 线程入口函数 int main(int argc, char *argv[]) { pthread_t tid; // 线程标识符 pthread_attr_t attr; // 线程属性结构体 pthread_attr_init(&attr); // 初始化线程属性为默认值 pthread_create(&tid, &attr, runner, argv[1]); // 创建线程 pthread_join(tid,NULL); // 等待线程结束 printf("sum = %d\n",sum); } void *runner(void *param) { int i, upper = atoi(param); sum = 0; for (i = 1; i <= upper; i++) sum += i; pthread_exit(0); }等待 10 个工作线程全部执行完毕#define NUM_THREADS 10 pthread_t workers[NUM_THREADS]; // 线程 ID 数组 // 循环等待所有线程执行完毕 for (int i = 0; i < NUM_THREADS; i++) pthread_join(workers[i], NULL); -
Win32 threads:由内核实现,适用于 C/C++ 中的 Windows 系统
代码示例
Windows 平台多线程累加#include <windows.h> #include <stdio.h> DWORD Sum; // 定义全局共享变量 Sum,子线程写、主线程读 // 线程入口函数 DWORD WINAPI Summation(LPVOID Param){ DWORD Upper = *(DWORD*)Param; for (DWORD i = 1; i <= Upper; i++) Sum += i; return 0; } int main(int argc, char *argv[]) { DWORD ThreadId; HANDLE ThreadHandle; int Param; Param = atoi(argv[1]); // 创建子线程 ThreadHandle = CreateThread( NULL, // 默认安全属性:子线程继承当前进程的安全设置 0, // 默认栈大小:使用与主线程相同的栈大小 Summation, // 子线程要执行的入口函数 &Param, // 传递给 Summation 的参数 0, // 默认创建标志:子线程创建后立即运行 &ThreadId); // 输出参数:将创建的子线程 ID 存入 ThreadId // 等待子线程执行完毕 WaitForSingleObject(ThreadHandle,INFINITE); // 关闭线程句柄,释放线程句柄对应的系统资源 CloseHandle(ThreadHandle); printf("sum = %d\n",Sum); } -
OpenMP
- 适用于 C、C++、FORTRAN 的一套编译器指令与 API,支持共享内存环境下的并行编程,支持并行区域(parallel regions)标识,
#pragma omp parallel会创建与 CPU 核心数相同数量的线程 - 是 Pthreads 之上的一层封装,便于在简单场景下便捷地实现多线程
代码示例
基础并行区域#include <omp.h> #include <stdio.h> int main(int argc, char *argv[]) { /* 串行代码区域(这部分由单个主线程执行) */ #pragma omp parallel { // 并行区域内的代码:每个线程都会执行这条 printf 语句 printf("I am a parallel region."); } /* 串行代码区域(并行区域结束后,所有线程合并回单个主线程继续执行) */ return 0; }并行化 for 循环// #pragma omp parallel for for (i = 0; i < N; i++) { // 每个迭代的计算任务:将数组 a、b 对应下标的元素相加,结果存入数组 c // 注:不同线程会处理不同的 i 值,实现并行计算(替代单线程串行遍历) c[i] = a[i] + b[i]; } - 适用于 C、C++、FORTRAN 的一套编译器指令与 API,支持共享内存环境下的并行编程,支持并行区域(parallel regions)标识,
-
Java Threads
- 由 JVM(Java 虚拟机)实现,依赖内核线程
- 自动管理内存,避免内存泄漏
创建方式
方式 1:继承 Thread 类class MyThread extends Thread { // 重写 run 方法:线程启动后会执行此方法内的逻辑 public void run() { // 线程的业务逻辑(此处省略具体代码) ... } } MyThread t = new MyThread(); // 创建线程方式 2:实现 Runnable 接口public interface Runnable { // 抽象方法run:实现该接口的类需重写此方法,定义线程要执行的任务 public abstract void run(); }早期 JVM 绿色线程(用户级线程)
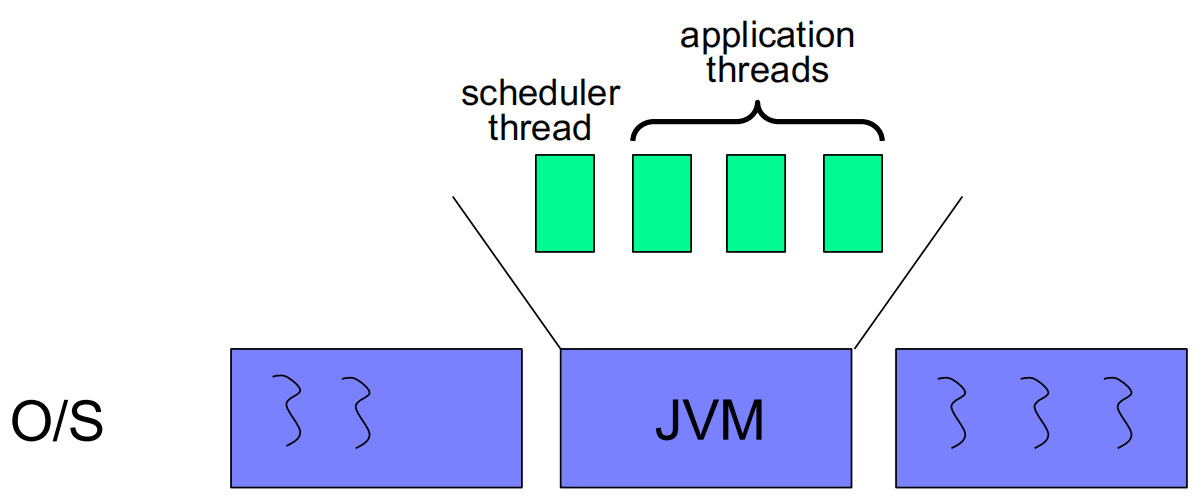
- JVM 自己实现了线程管理,由内部的调度器线程负责调度、管理多个应用程序线程
- OS 无法直接感知 JVM 内部的应用程序线程,只能与 JVM 进程本身的线程交互,即绿色线程对 OS 不可见
- 绿色线程具备用户级线程的所有缺点,如无法利用多核、多处理器架构,在现代 JVM 中通常已不可用
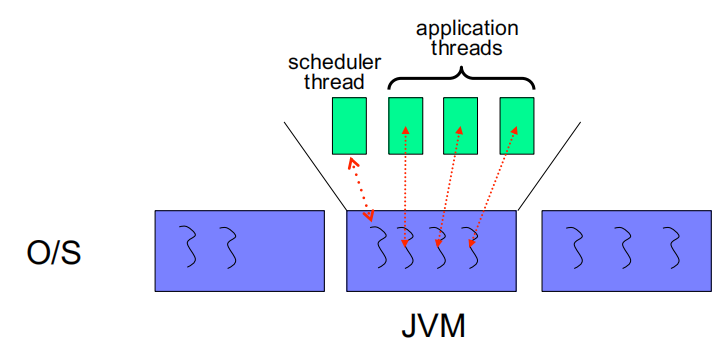
原生线程(native threads)
- 应用程序线程被映射到内核线程
3. 4 Threading Issues¶
3. 4. 1 fork() 与 exec() 的语义¶
fork:- 新进程仅复制调用
fork()的线程,Linux 采用该选项 - 新进程仅复制原进程的所有线程,包括调用
fork()的线程
- 新进程仅复制调用
exec():加载新程序,替换进程的代码/数据/堆,原线程全部终止并清空
3. 2. 2 信号处理¶
- 在多线程程序中,信号传递存在多种选项,包括:传递给目标线程、所有线程、特定线程,或指定线程接收所有信号
- 大多数 UNIX 版本中,线程可以指定自己接受哪些信号、不接受哪些信号
3. 2. 3 线程取消¶
- 异步取消(Asynchronous)
- 一个线程立即终止另一个线程
- 易导致状态不一致或同步问题
- 延迟取消(Deferred cancellation)
- 线程定期检查自己是否应该终止(如
pthread_testcancel),到达取消点时终止,随后会调用清理处理程序 - 代码繁琐,但安全,是默认的取消类型
- 在 Linux 系统中,线程取消是通过信号来处理的
- 在 Java 中,
Thread.stop()方法已被弃用,因此取消操作必须采用延迟式
- 线程定期检查自己是否应该终止(如
- 发起线程取消操作是请求取消,但实际取消是否执行取决于线程的状态
- 如果线程禁用了取消功能,取消请求会处于挂起状态,直到线程启用取消功能
| 模式(Mode) | 状态(State) | 类型(Type) |
|---|---|---|
| 关闭(Off) | 禁用(Disabled) | — |
| 延迟(Deferred) | 启用(Enabled) | 延迟型(Deferred) |
| 异步(Asynchronous) | 启用(Enabled) | 异步型(Asynchronous) |
3. 2. 4 线程本地存储(TLS, Thread-local Storage)¶
- 允许每个线程拥有独立的数据副本,适用于线程池(无法控制线程创建过程)
- 跨函数调用可见,区别于仅函数内可见的局部变量
- 与静态数据类似,TLS 对每个线程来说都是唯一的
3. 2. 5 调度器激活(Scheduler Activations)¶
轻量级进程(LWP, Lightweight Process)
- 轻量级进程(LWP)多对多模型和两级模型中,用户线程与内核线程之间的中间数据结构
- 作为用户线程与内核线程之间的中间层,对用户线程库表现为虚拟处理器(可在其上调度用户线程)
- 每个 LWP 都附着于一个内核线程,内核线程阻塞会导致 LWP 阻塞,进而导致用户线程阻塞
- 内核负责调度内核线程,用户线程库负责调度用户线程,内核需将重要调度事件通知给线程库以避免次优调度
Further Reading
-
在计算机操作系统中,LWP 是实现多任务的一种方式,传统定义中(如 Unix System V 和 Solaris 系统中的用法),LWP 运行在用户空间,基于单个内核线程,且与同一进程内的其他 LWP 共享地址空间和系统资源。由线程库管理的多个用户级线程,可以部署在一个或多个 LWP 之上,这使得多任务能在用户级完成,从而带来一定的性能优势。
-
在部分操作系统中,内核线程与用户线程之间并没有独立的 LWP 层,这意味着用户线程是直接基于内核线程实现的。在这种场景下,LWP 一词通常指代内核线程,而线程则可指代用户线程。在 Linux 系统中,用户线程是通过让特定进程共享资源来实现的,这些进程有时也会被称为LWP。
- 核心机制:内核通过上调用(upcall)通知线程库调度事件(如线程阻塞),线程库可切换用户线程到 LWP,避免资源浪费
3. 5 Operating System Examples¶
3. 5. 1 Windows Threads¶
- 采用一对一映射模型,属于内核级线程
- 每个线程包含:线程ID,表示处理器状态的寄存器组,用户栈与内核栈,运行时库和动态链接库(DLL)使用的私有数据存储区
- 寄存器组、栈以及私有存储区统称为线程的上下文
-
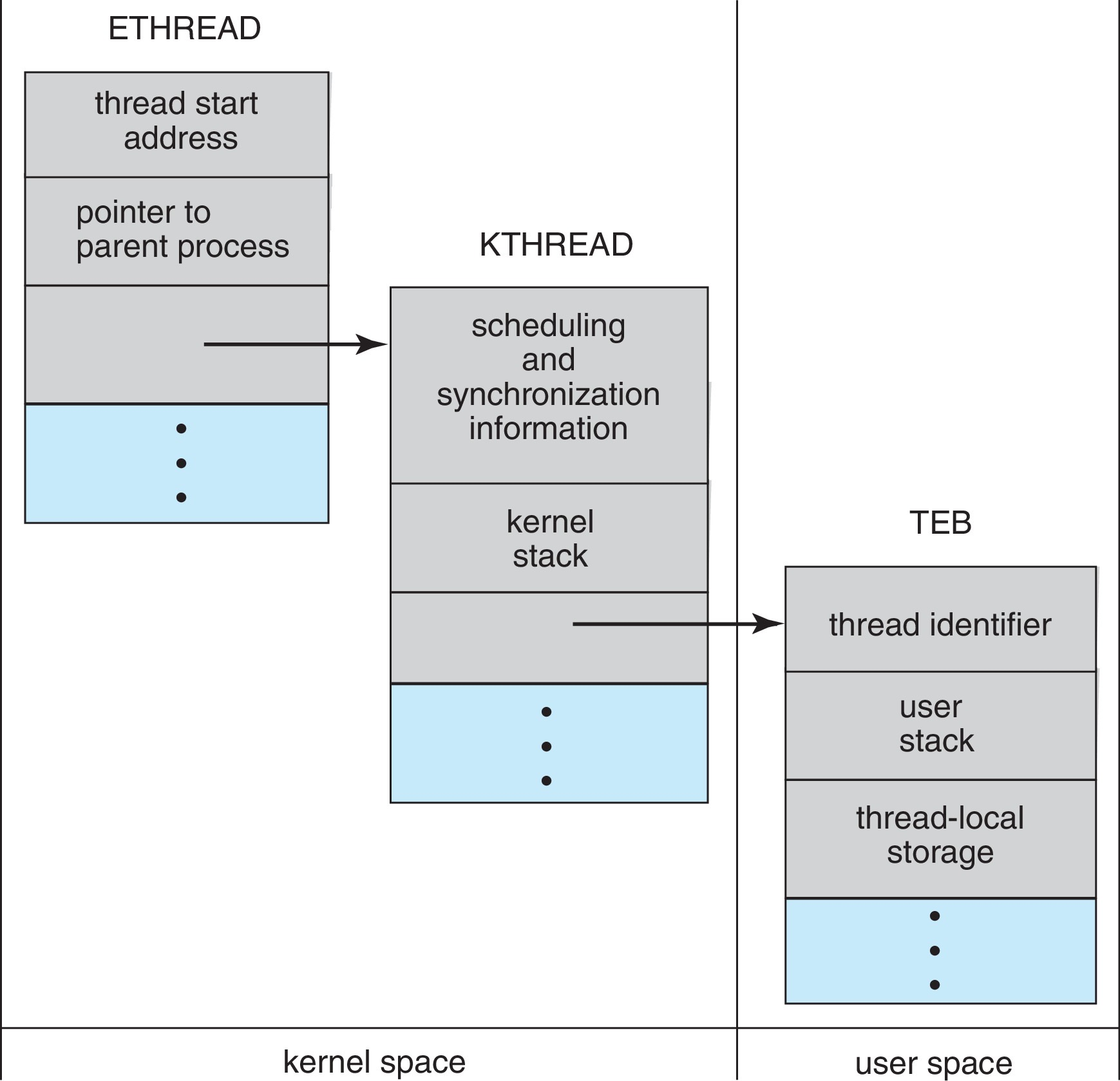
核心数据结构
- ETHREAD(执行线程块):包含指向所属进程和 KTHREAD 的指针,位于内核空间
- KTHREAD(内核线程块):包含调度与同步信息、内核栈、指向 TEB 的指针,位于内核空间
- TEB(线程环境块):包含线程 ID、用户栈、TLS
Windows Threads 数据结构示意图
3. 5. 2 Linux Threads¶
- 在 Linux 中,内核线程也被称为 LWP
- 用
task_struct统一表示进程和线程 - 进程的定义
- 单个线程 + 一个地址空间:其 PID 就是该线程的 ID
- 多个线程 + 一个地址空间:其 PID 是主线程的 ID
-
clone()系统调用用于创建线程或进程,与父进程共享执行上下文,通过标志控制资源共享clone()标志标志 含义 CLONE_FS 文件系统信息会被共享 CLONE_VM 共享同一内存空间 CLONE_SIGHAND 信号处理器会被共享 CLONE_FILES 已打开的文件集合会被共享 -
一个任务对应一个
task_struct(即PCB),在一个线程中执行 - 执行空间:
- 用户空间:运行用户代码,使用用户空间栈
- 内核空间(如调用系统调用时):执行流陷入内核,运行内核代码、使用内核空间栈
- 相同的
task_struct(PCB)代表同一个线程,属于一对一映射(用户线程与内核线程是同一线程,可在用户态/内核态执行) - 内核线程:无用户空间部分,仅运行内核代码(如刷新脏缓冲区到磁盘)
SYSCALL_DEFINE0(getpid) {
// 获取当前任务所属线程组的 ID(即进程 ID)
return task_tgid_vnr(current);
}
SYSCALL_DEFINE0(gettid)
{
// 获取当前 task_struct 对应的 ID(即线程自身的 ID)
return task_pid_vnr(current);
}