Chapter 14 Indexing and Hashing¶
1 Basic Concepts¶
索引(index)是用来加速访问目标数据的机制。索引文件通常比原文件小得多,因此可以显著减少磁盘 I/O。
- 搜索键(Search key):用于查找文件中记录的一个属性或属性集
- 索引项 / 索引条目(Index entries):索引中的一条记录,通常形如
(search-key, pointer) - 有序索引(Ordered indices):搜索键按排序后的顺序存储,适合范围查询
- 哈希索引(Hash indices):通过哈希函数将搜索键均匀分布到不同的桶(bucket)中,适合等值查询
索引可用于快速定位记录,支持等值查找、范围查找和连接优化,代价是更新时需要额外维护索引。
索引评估指标(Index Evaluation Metrics)
- 高效支持的访问类型,如属性值为指定值的记录或属性值落在指定数值范围内的记录
- 访问时间、插入时间、删除时间、空间开销
2 Ordered Indices¶
在有序索引中,索引项按搜索键值排序存储。
- 主索引(Primary index):搜索键的值直接决定文件物理存储顺序的索引,又称聚簇索引(clustering index),其搜索键通常(但非必须)是主键
- 二级索引(Secondary index):搜索键定义的排序顺序与文件本身的物理存储顺序不一致的索引,又称非聚簇索引(non-clustering index)
示例
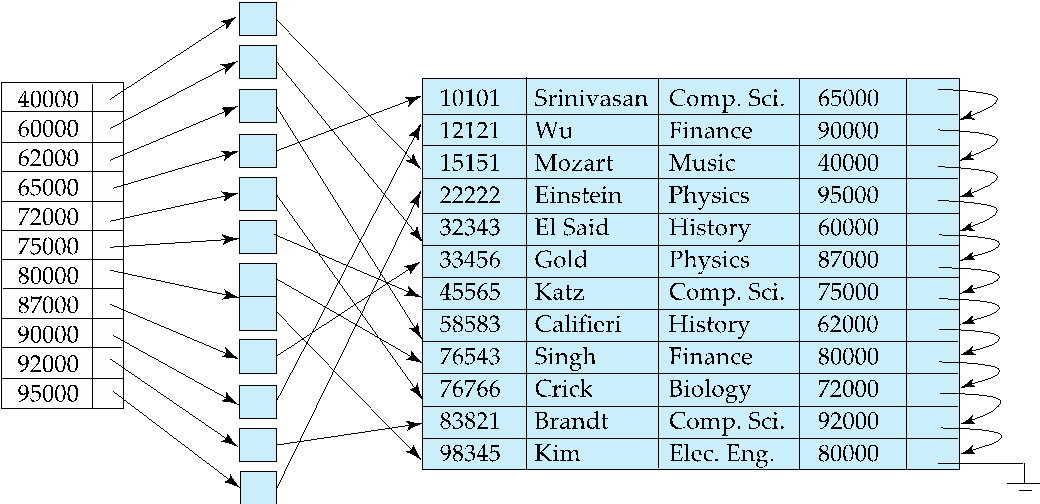
- 索引顺序文件(Index-sequential file):带有主索引的有序顺序文件
- 稠密索引(Dense index):文件中每个搜索键值都对应一条索引记录,被索引的文件可以是顺序文件,也可以是非顺序文件
示例
当 instructor 已按 dept_name 排序时,为 dept_name 建立的稠密索引属于主索引:
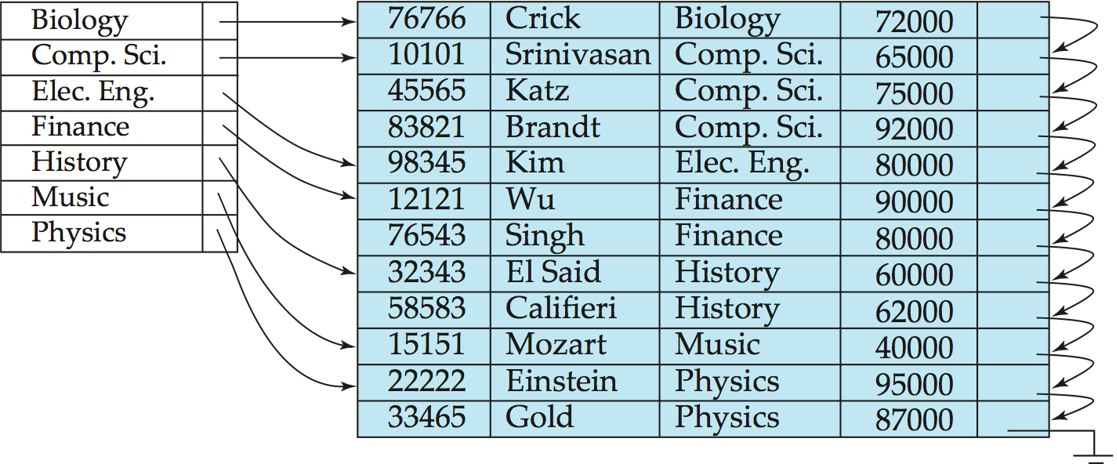
若 instructor 未按 dept_name 排序,则为 dept_name 建立的索引是二级索引,且二级索引始终为稠密索引。
此时索引项中的指针不会直接指向文件记录,而是指向一个 bucket。
- 稀疏索引(Sparse index):只为部分搜索键值建立索引项,适用于记录已按搜索键顺序排列的场景
示例
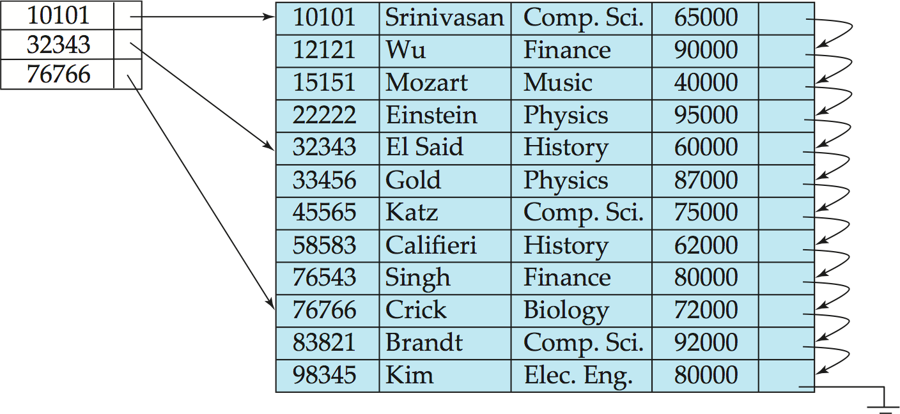
稠密索引更容易直接命中,但空间更大,更新更频繁;稀疏索引更省空间,插入、删除操作的维护开销更低,但定位记录的速度通常比稠密索引慢(需要额外的顺序扫描步骤)。
Good tradeoff
为文件中的每个数据块(block)建立一条索引项,索引项的值为该数据块内的最小搜索键值。
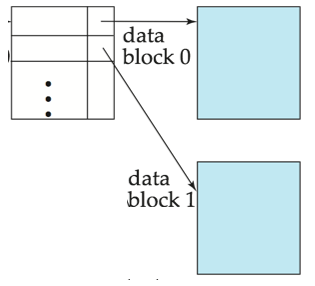
如果单层索引太大,不能完全放入内存,就可以在其上再建索引,形成多级索引(multilevel index)。
- 内层索引(inner index):底层索引文件
- 外层索引(outer index):指向内层索引的稀疏索引
示例
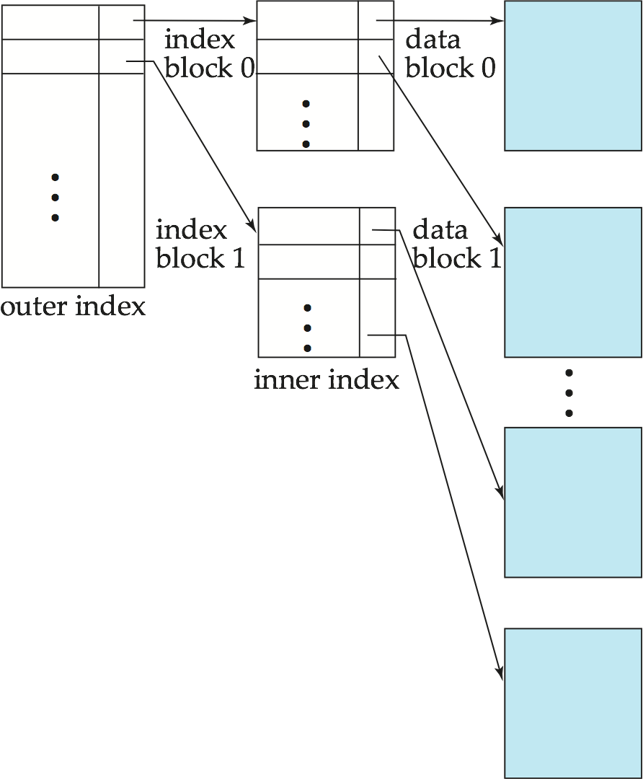
如果外层索引仍然太大,可以继续向上建索引。插入和删除时,所有层次都必须维护。
| 删除 | 插入 | |
|---|---|---|
| 稠密索引 | 删除对应搜索键的索引入口 | 若新记录的搜索键值不存在于索引中则插入 |
| 稀疏索引 | 若被删键值不是当前块的代表值,索引无需改动;若是,则用文件中下一个搜索键值替换该索引入口 | 仅当创建新数据块时,才将新块的首个搜索键值加入索引 |
复合搜索键(Composite search key):在 instructor 关系表上基于 (name, ID) 属性构建的索引
- 键值按字典序(lexicographical order)排序,如
(John, 12121) < (John, 13514),(John, 13514) < (Peter, 11223) - 支持仅基于
name的查询,也支持基于(name, ID)的组合查询
3 B+ Tree Index¶
3. 1 Basic Ideas¶
索引顺序文件(Indexed-sequential files)的缺点
随着文件规模增长,性能会逐渐下降,因为插入操作会产生大量溢出块(overflow blocks),破坏数据的连续性,需要对整个文件进行定期重组(periodic reorganization),才能维持访问性能。
B+ 树的优缺点
- 优点:在面对插入、删除操作时,B⁺树可以通过小规模的节点调整,自动完成自身重组与平衡,无需对整个文件进行全局重组,就能长期维持稳定的访问性能。
- 缺点:存在额外的插入/删除操作开销,以及一定的空间开销(需要存储树节点中的指针信息)。
B+-tree 是数据库里最常用的 ordered index。
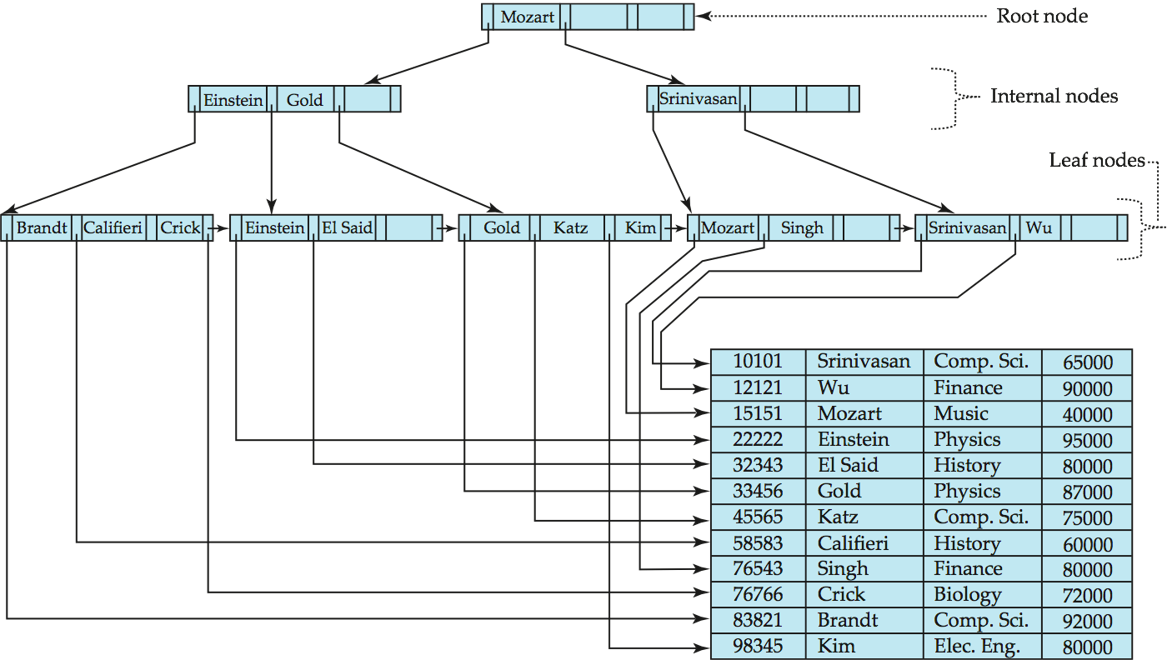
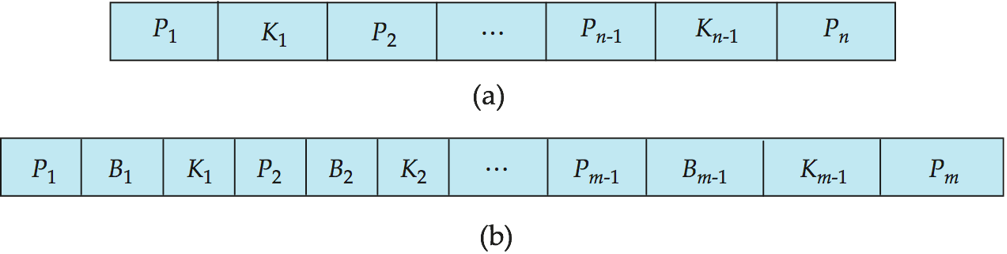
- 所有叶节点在同一层,非叶节点只负责导航,不存放数据记录
- 每个节点有 \(n\) 个指针存储位置,以及 \(n-1\) 个搜索键值存储位置
- 非根内部节点:子节点数量在 \(\lceil n/2 \rceil\) 到 \(n\) 之间
- 叶节点:搜索键值数量在 \(\lceil (n-1)/2 \rceil\) 到 \(n-1\) 之间
- 特殊情况:若根节点不是叶节点,则它至少有 \(2\) 个子节点,否则可存储 \(0\) 到 \(n-1\) 个键值

- \(K_i\) 是搜索键值,\(P_i\) 是指针
- 叶节点:\(P_n\) 指向按搜索键值排序的下一个叶节点,\(P_1\) 至 \(P_{n-1}\) 指向搜索键值为 \(K_i\) 的文件记录或记录存储桶
- 非叶节点:为叶节点构建了多级稀疏索引,指向子节点
- 节点内的所有搜索键值按升序排列(\(K_1 < K_2 < K_3 < \dots < K_{n-1}\)),便于范围扫描
B+ 树的特性
节点间通过指针连接,逻辑上相邻的数据块在物理存储上不必相邻。
| 树高 \(h\) | 叶节点层最少键值数 | 叶节点层最多键值数 |
|---|---|---|
| \(h=1\)(仅根节点) | \(0\) | \(n-1\) |
| \(h=3\) | \(2 \times \lceil n/2 \rceil \times \lceil (n-1)/2 \rceil\) | \(n^2 \times (n-1)\) |
| 通用 \(h\) | \(2 \times (\lceil n/2 \rceil)^{h-2} \times \lceil (n-1)/2 \rceil\) | \(n^{h-1} \times (n-1)\) |
- 最大树高:用最少键值公式 \(2 \times (\lceil n/2 \rceil)^{h-2} \times \lceil (n-1)/2 \rceil = K\) 求解 \(h\),再对结果向下取整。
- 最小树高:用最多键值公式 \(n^{h-1} \times (n-1) = K\) 求解 \(h\),再对结果向上取整。
- 若文件中共有 \(K\) 个搜索键值,树高不超过 \(\lceil \log_{\lceil n/2 \rceil}(K) \rceil\),查询操作可高效完成。
- 对主文件的插入、删除操作可被高效处理,索引的重构时间复杂度为对数级。
3. 2 B+ Tree Search / Insert / Delete¶
- 查询:从根开始,逐层比较,直到叶子
- 插入:叶子满时分裂,向上递归调整
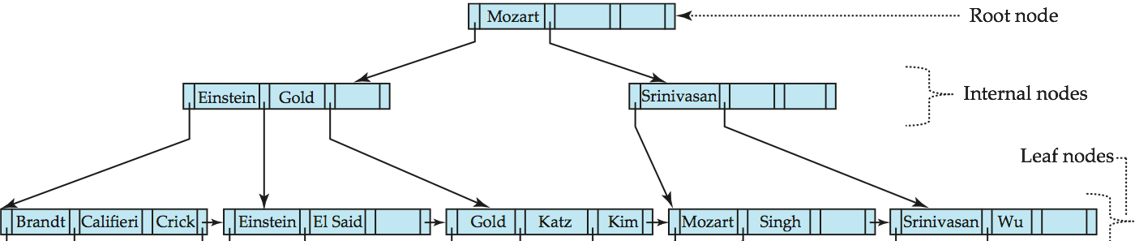
示例
- B+ Tree before and after insertion of "Adams"
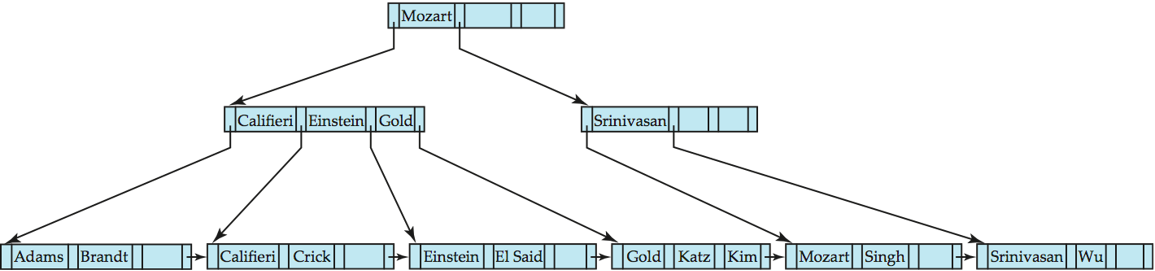
- B+-Tree before and after insertion of "Lamport", causes splitting of internal node
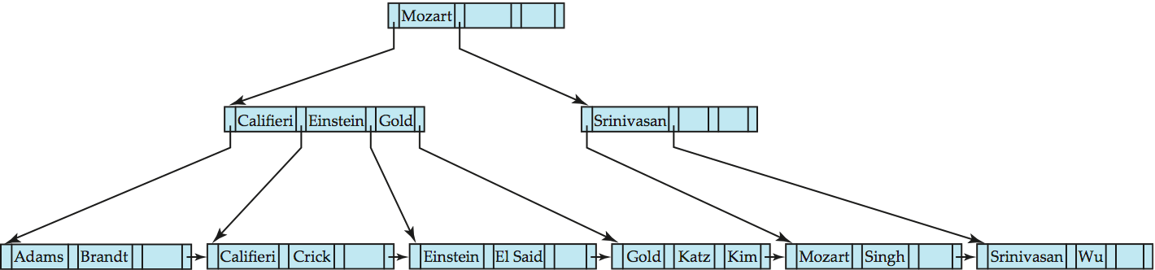
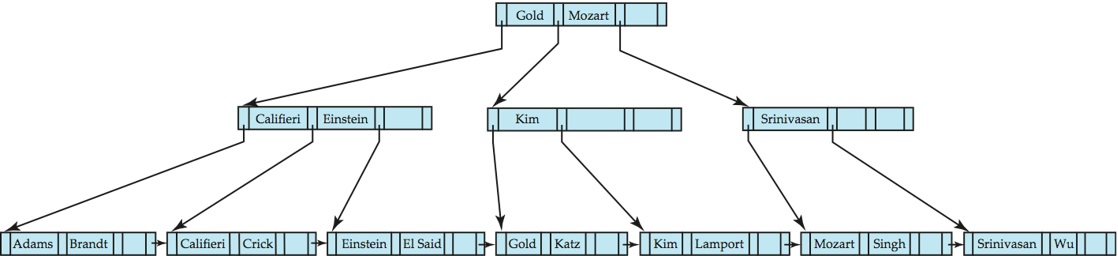
- 删除:下溢时先重分配,不行再合并,并向上修正父节点
示例
- B+ Tree before and after deleting "Srinivasan", causes merging of under-full leaves, and merging and spit of parent nodes
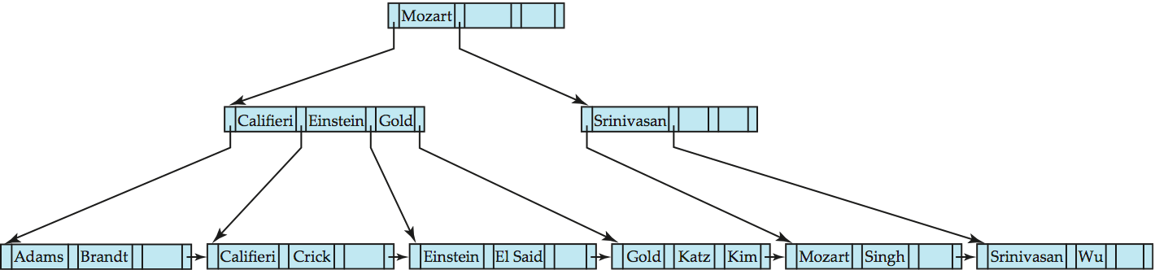
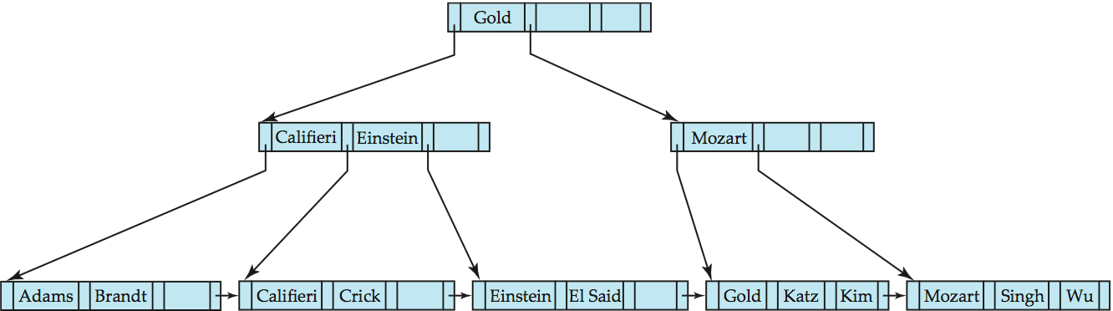
- Deletion of "Singh" and "Wu" from result of previous example, causes redistribution of two leaf nodes
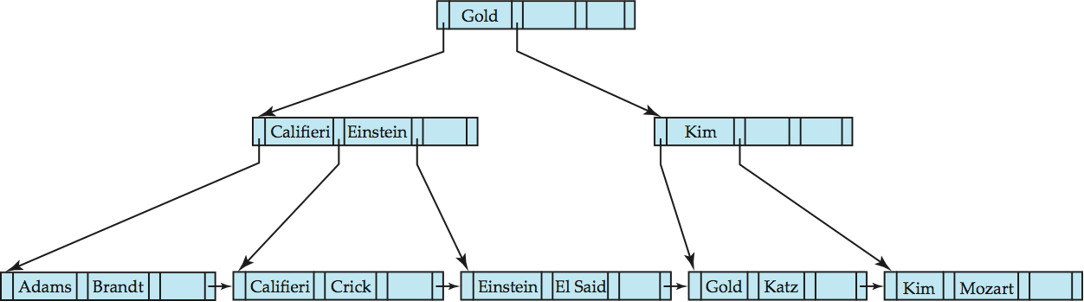

Non-Unique Search Keys
| 方案 | 优点 | 缺点 |
|---|---|---|
| 桶/指针列表 | 空间开销小,查询快 | 处理长列表、删除重复记录时代码复杂,开销高 |
| 加记录标识符 | 代码简单,易维护 | 键的存储空间会增加 |
B+ Tree Optimizations
- 变长字符串键(Variable-length keys):节点分裂的判断标准由指针数量改为空间利用率
- 前缀压缩(Prefix compression):内部节点只保存足够区分子树的前缀
- 批量加载(Bulk loading):大量插入时先排序再自底向上构树,效率更高
3. 3 B Tree¶
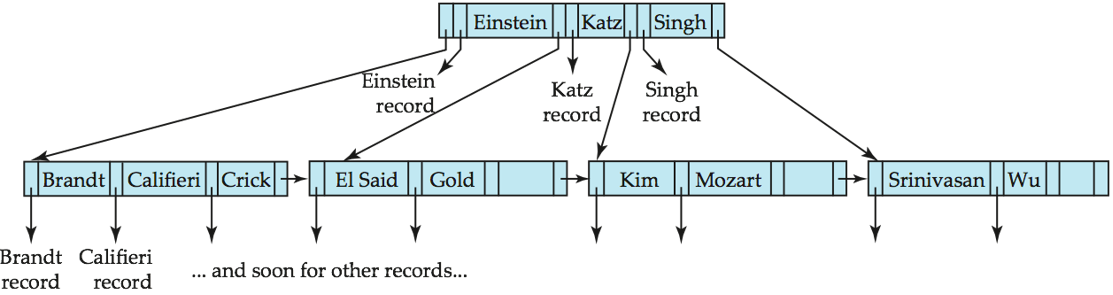
B 树的搜索键值仅会出现一次,消除了搜索键的冗余存储。非叶子节点中的搜索键不会在 B 树的其他位置出现,因此非叶子节点中每个搜索键都必须额外包含一个指针字段。
- 优点:可能使用更少的树节点,有时可以在到达叶子节点之前就找到搜索键值。
- 缺点:
- 只有一小部分搜索键值能被提前找到
- 非叶子节点体积更大,导致扇出(可容纳的子节点数)降低,B 树的深度通常比对应的 B+ 树更大
- 插入和删除操作比 B+ 树更复杂,实现难度高于 B+ 树
4 Hash Indices¶
示例
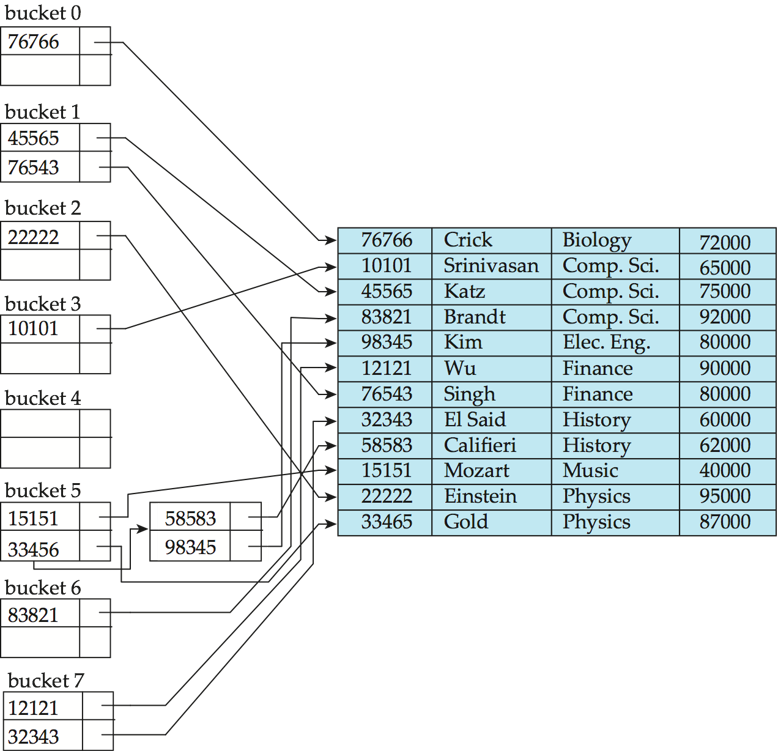
4. 1 Static Hashing¶
哈希函数把搜索键值映射到桶地址,不同搜索键值的记录可能被映射到同一个桶,定位记录时需要对整个桶进行顺序查找。
Hash File Organization
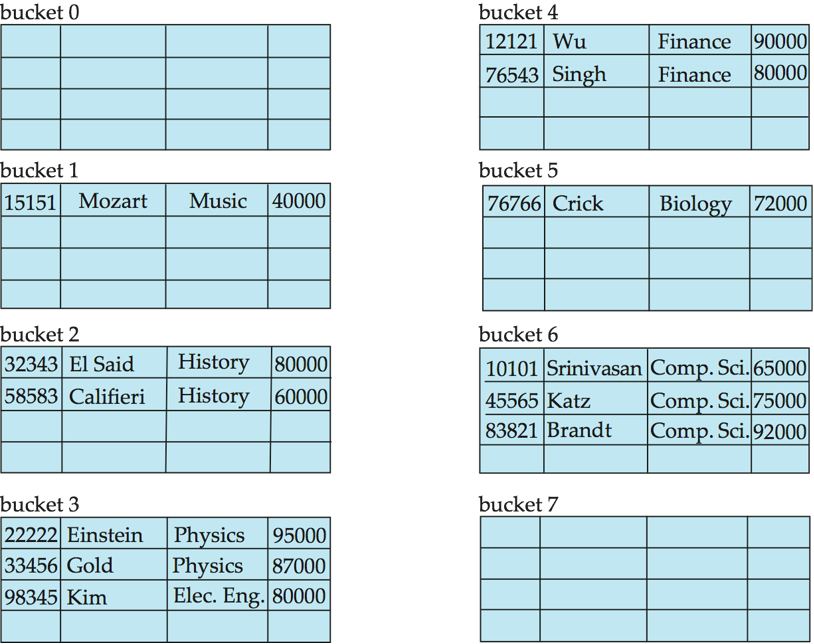
桶的数量不足或记录分布不均可能导致桶溢出(Bucket overflow),可以用溢出链(Overflow chaining)处理,这种方式称为闭散列(closed hashing)。
示例
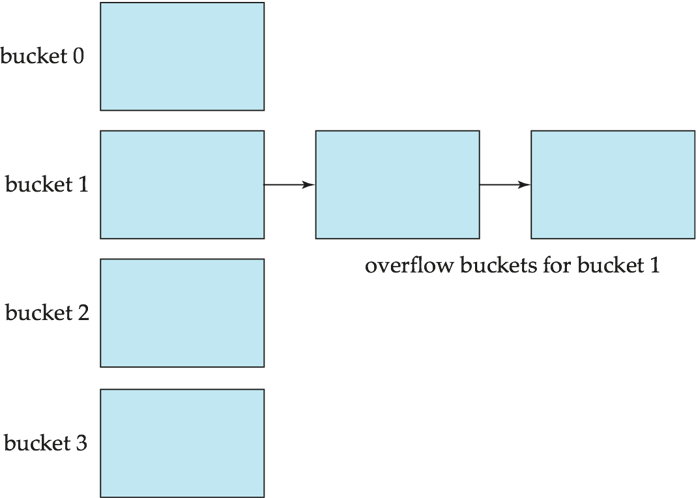
另一种不使用溢出桶的方案称为开散列(open hashing),但它不适用于数据库应用场景。
4. 2 Extendible Hashing¶
可扩展哈希(Extendable hashing) 是一种动态哈希(Dynamic hashing ),适合数据库这种会增长和收缩的场景。
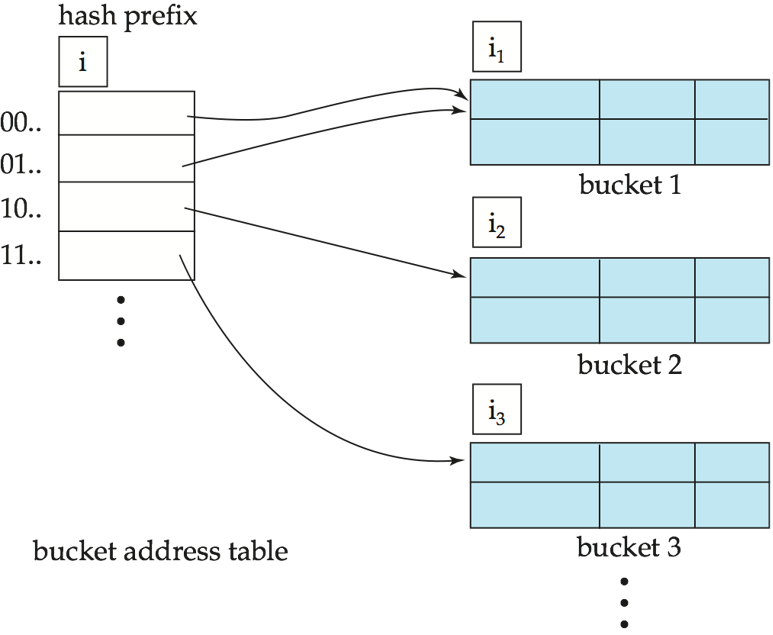
哈希函数会生成一个大范围的值,通常为 \(b\) 位整数(典型值为 \(b=32\)),任意时刻,仅使用哈希值的前缀部分来索引桶地址表。
设前缀长度为 \(i\) 位(\(0 \le i \le 32\)),则桶地址表的大小为 \(2^i\),初始状态下 \(i=0\),\(i\) 的值会随着数据库数据量的增减而动态变化。
桶地址表中的多个条目可能指向同一个桶,因此实际的桶数量小于 \(2^i\),桶的数量也会因桶的合并与分裂而动态变化。
假设每个桶 \(j\) 存储一个值 \(i_j\),对于所有指向同一个桶的条目,其哈希值的前 \(i_j\) 位都相同。
- 插入:桶满时分裂,必要时目录翻倍
示例
- Initial Hash structure, bucket size = 2
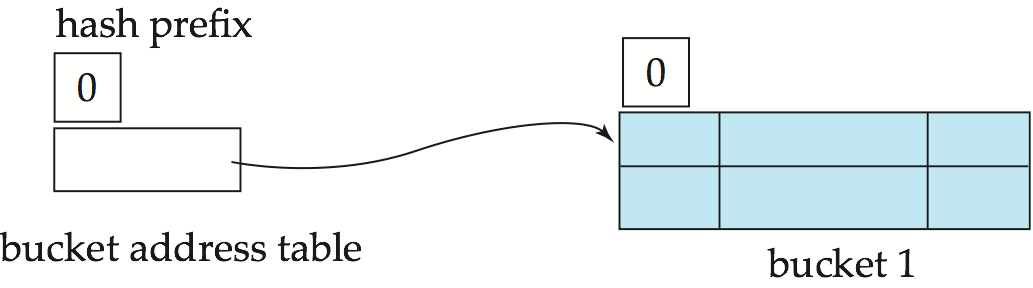
- Hash structure after insertion of "Mozart", "Srinivasan", and "Wu" records
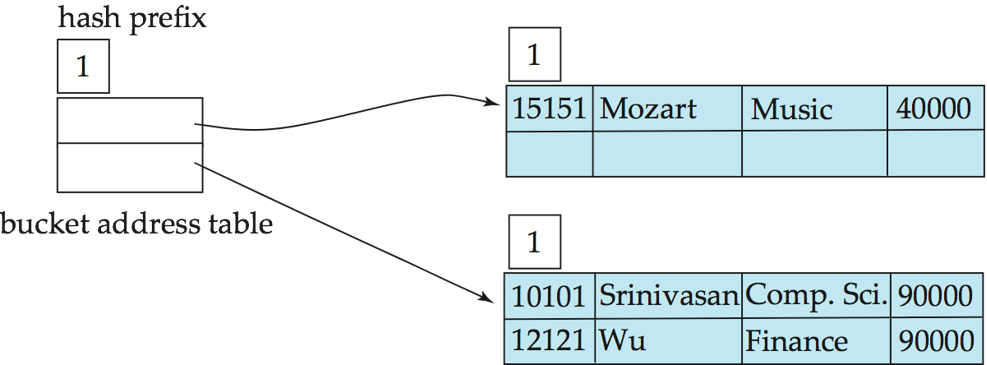
- Hash structure after insertion of "Einstein" record
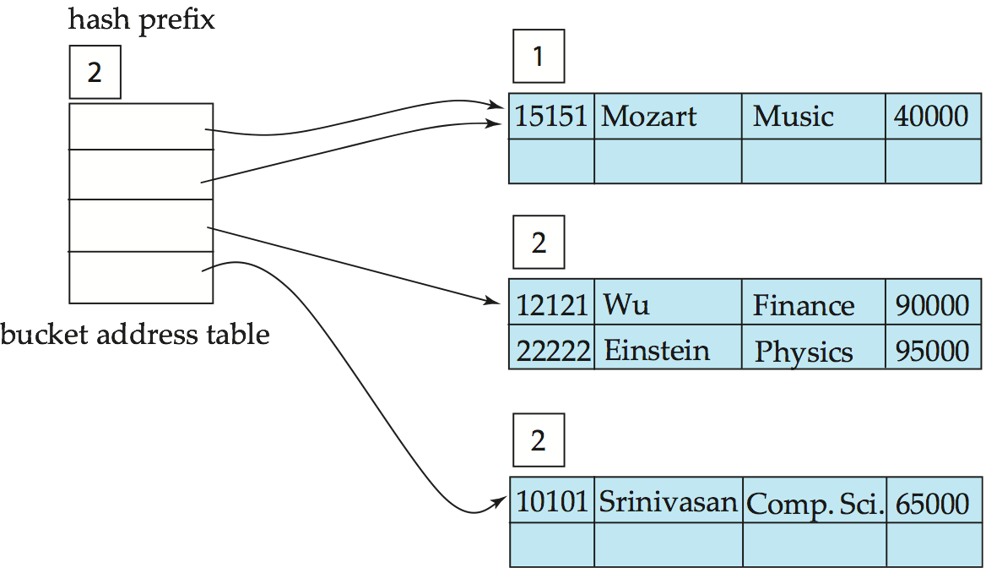
- Hash structure after insertion of "Gold" and "El Said" records
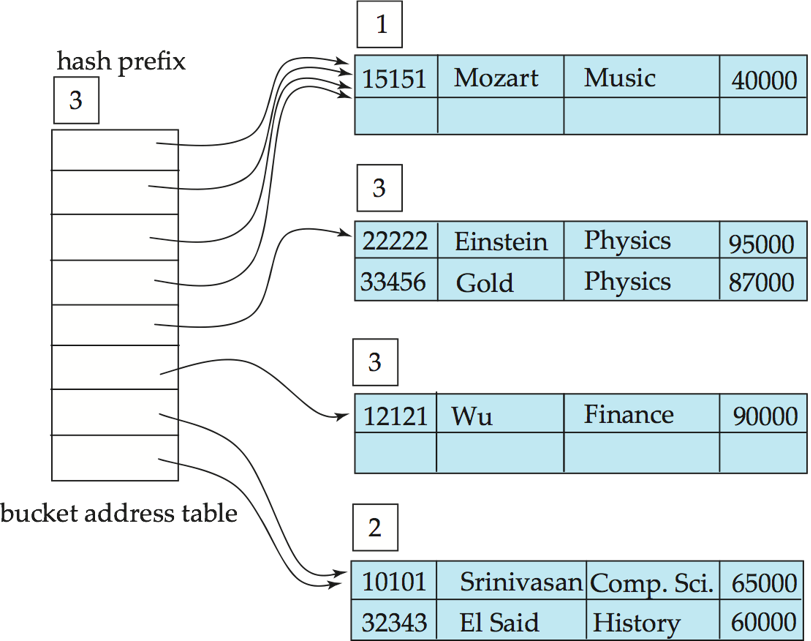
- Hash structure after insertion of "Katz" record
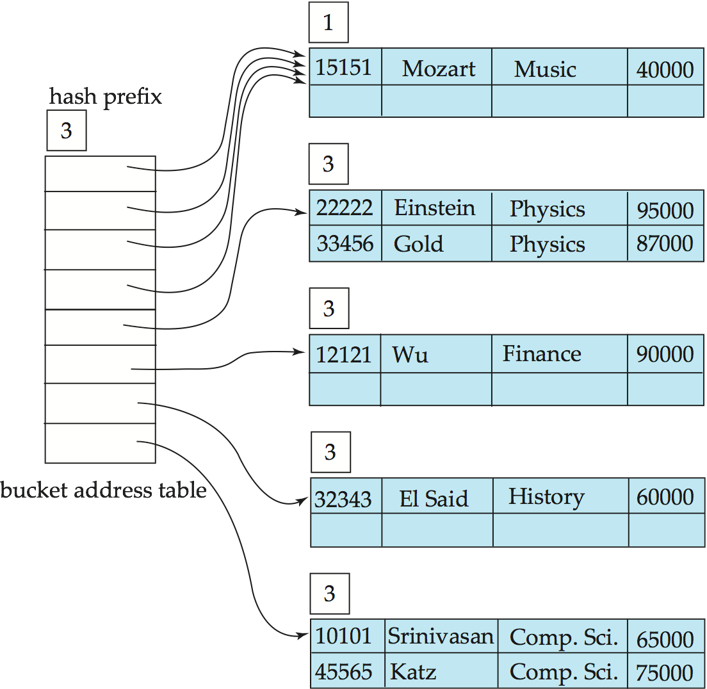
- And after insertion of eleven records
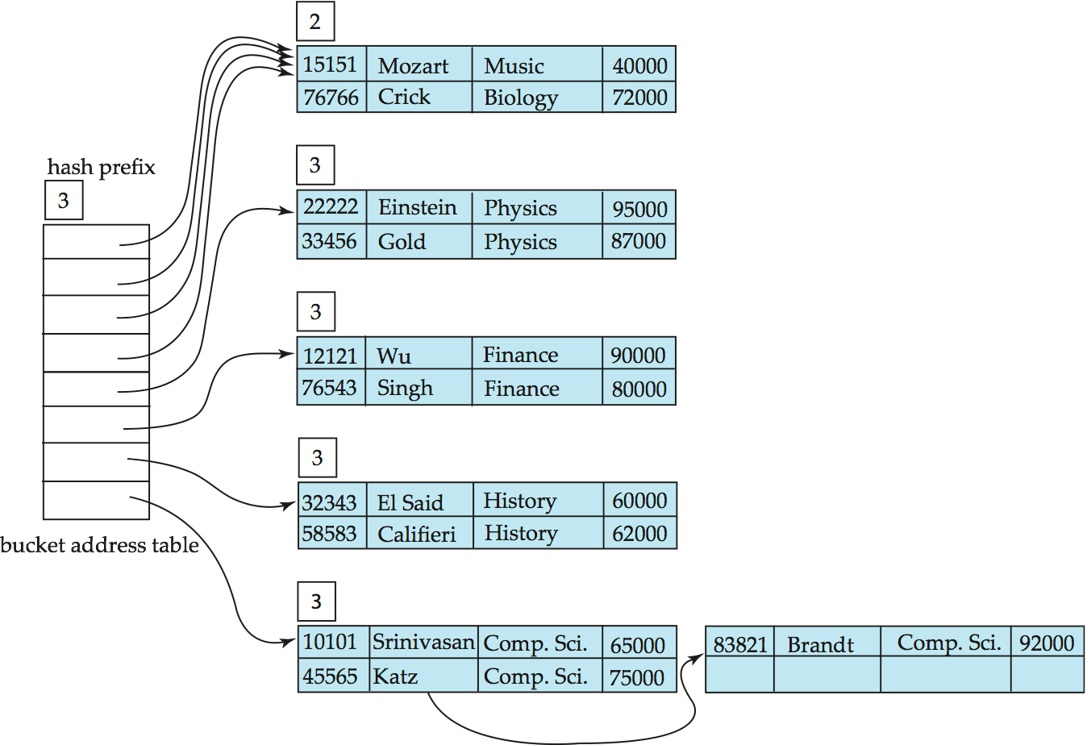
- And after insertion of "Kim" record in previous hash structure
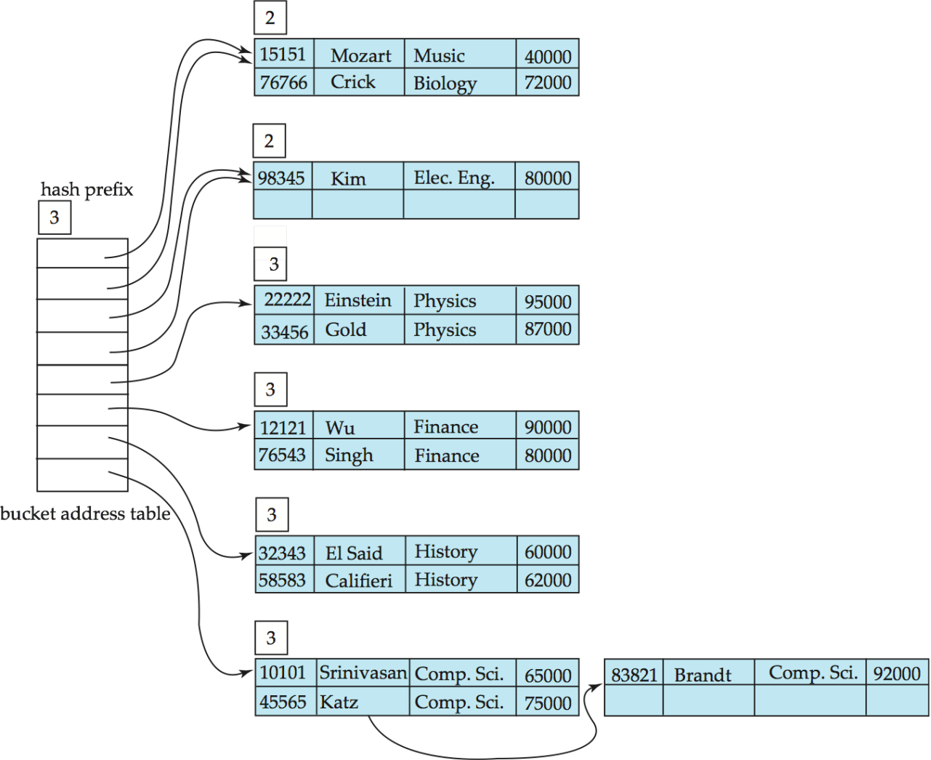
- 删除:空桶可删除,可合并桶,也可缩小目录,但代价较高
5 Multiple-Attribute Access¶
多个单属性索引可用于复合查询,可以先用一个索引筛选,再在内存中验证其他条件,或对多个索引得到的指针集合求交集,适合 AND 条件,但通常不如合成索引高效。
复合索引 (A, B, C) 对查询的支持遵循左前缀思路,可高效处理 A = ... and B = ...,也可处理 A = ... and B < ...,但对 A < ... and B = ... 通常不理想。
覆盖索引(Covering indices)在索引中添加额外的属性,让部分查询可以直接从索引中获取所需数据,无需再去读取实际的记录行。额外的属性只存储在索引的叶子节点中,对二级索引尤其有用。
主键索引通常由 DBMS 自动建立,一些系统也会自动为外键建索引。索引能加速查询,但会增加更新成本,许多数据库提供调优助手(index advisor)/ 向导(wizard),可根据查询与更新负载来帮助选择合适的索引。
SQL 中的索引定义
create index <索引名> on <表名>(<属性列表>)
- 使用
create unique index可以间接指定并强制要求搜索键为候选键,如果数据库支持 SQL 的unique完整性约束,那么这个语句并非必需。
drop index <索引名>
大多数数据库系统都支持指定索引的类型和聚簇方式。
6 Specialized Indexes¶
写优化索引(Write Optimized Indices)
对于写密集型工作负载,B+ 树的性能可能不佳:
- 假设所有内部节点都在内存中,每次叶子节点操作需要一次 I/O
- 机械硬盘上,单盘每秒插入数不足 100 次
- 闪存上,每次插入需要一次页覆盖写入。
两种降低写操作开销的方法:
- 日志结构合并树(Log-structured merge tree, LSM 树)
- 缓冲树(Buffer tree)
6. 1 LSM Trees¶
LSM tree 使用插入 + 删除来表示更新,适合写入密集型负载。
- 删除用特殊
deleteentry 标记 - 查询时要同时检查原记录和删除标记
- 合并时若删除标记与原项匹配,两者一起丢弃
6. 2 Bitmap Index¶
Bitmap index 适合取值种类少的属性。
- 每个 distinct value 对应一个 bit array
- 第 \(j\) 位表示第 \(j\) 条记录是否取该值
- 很适合多条件
AND/OR组合
常见场景: gender、state、country、分层收入等