Chapter 3 对称密钥加密以及伪随机性¶
引言
在上一讲中,我们假设敌手拥有无限计算能力,这样的方案叫做信息理论安全(information-theoretic notions of security),又称完美安全,而本讲讨论的计算安全(Computational security)稍弱一些,包含了以下两个放宽条件:
- 安全性仅在对抗有效 (指在可行的时间里运行) 的敌手时存在
- 敌手潜在的成功概率是非常小的
1 密码学的计算方法¶
1. 1 有效的算法和可忽略的成功概率¶
前置知识
-
如果对于每个多项式 \(p(\cdot)\) ,存在一个 \(N\) ,使得对于所有的整数 \(n > N\) ,都满足 \(f(n) < \frac{1}{p(n)}\),则称函数 \(f\) 为可忽略的(negligible)
-
如果存在一个多项式 \(p(\cdot)\) ,使得对于每个输入 \(x \in \{0,1\}^*\) ,\(A(x)\) 的计算最多在 \(p(|x|)\) 个步骤内终止(\(|x|\) 指字符串 \(x\) 的长度),则该算法 \(A\) 被认为在多项式时间内运行
-
有效的运算是指能够在概率多项式时间(PPT, probabilistic polynomial-time)内执行的计算
在课程中,我们使用渐进方法来定义计算安全,即:
- 如果每个 \(\text{PPT}\) 敌手以可忽略的概率成功攻破一个方案,那么该方案是安全的。
示例
函数 \(2^{-n}\),\(2^{-\sqrt{n}}\) 以及 \(n^{-\log n}\) 都是可忽略的函数,但它们接近零的速度是非常不同的
可忽略函数的运算性质(可作无穷小量理解)
令 \(\text{negl}_1\) 和 \(\text{negl}_2\) 为可忽略函数,则:
-
函数 \(\text{negl}_3 (n) = \text{negl}_1 (n) + \text{negl}_2 (n)\) 是可忽略的
-
对于任何正多项式 \(p\),函数 \(\text{negl}_4 (n) = p(n) \cdot \text{negl}_1 (n)\) 是可忽略的
1. 2 规约证明¶
- 指定 \(\text{PPT}\) 敌手 \(\mathcal{A}\) 攻击 \(\Pi\),将敌手的成功概率表示为 \(\varepsilon(n)\)
-
构造一个叫做规约的有效算法 \(\mathcal{A}'\),该算法将敌手 \(\mathcal{A}\) 作为子程序来使用,试图解决难题 \(X\)。这里很重要的一点是,\(\mathcal{A}'\) 对 \(\mathcal{A}\) 是如何工作的一无所知,\(\mathcal{A}'\) 知道的唯一的事情就是 \(\mathcal{A}\) 想要攻击 \(\Pi\)。所以,指定难题 \(X\) 的某个输入实例 \(x\),算法 \(\mathcal{A}'\) 将会对 \(\mathcal{A}\) 模拟出一个 \(\Pi\) 的实例,满足:
- 就 \(\mathcal{A}\) 而言,它和 \(\Pi\) 交互。更正式地说,当 \(\mathcal{A}\) 作为子程序被 \(\mathcal{A}'\) 运行时,\(\mathcal{A}\) 的分布应该和当 \(\mathcal{A}\) 自身和 \(\Pi\) 交互时的分布是相同的(或至少是很接近的)
- 如果 \(\mathcal{A}\) 成功攻破了由 \(\mathcal{A}'\) 模拟的 \(\Pi\) 的实例,则 \(\mathcal{A}'\) 解决给出的难题实例 \(x\) 成功的概率至少为多项式的倒数,即 \(1/p(n)\)
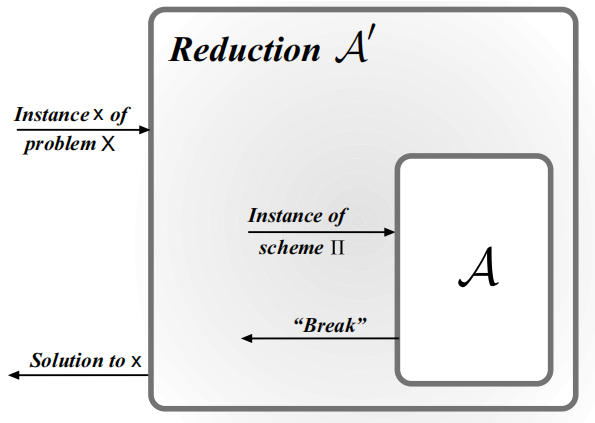
-
总起来考虑,如果 \(\varepsilon(n)\) 不是可忽略的,则 \(\mathcal{A}'\) 解决难题 \(X\) 的概率为不可忽略的概率 \(\varepsilon(n)/p(n)\)。如果 \(\mathcal{A}\) 是有效的,则存在有效的算法 \(\mathcal{A}'\) 以不可忽略的概率解决 \(X\),与原假设矛盾
- 因而结论是,给定一个关于 \(X\) 的假设,不存在有效的敌手 \(\mathcal{A}\) 能够以不可忽略的概率成功攻破 \(\Pi\),换句话说,\(\Pi\) 是计算上安全的
温馨提示
规约证明的纯文字叙述较为晦涩,简而言之,就是假设有敌手 \(\mathcal{A}\) 能攻破 \(\Pi\),则可构造以 \(\mathcal{A}\) 为子程序的敌手 \(\mathcal{R}^{\mathcal{A}}\) 攻破 \(\Pi'\),常用于反证法
2 EAV-Secure¶
对称密钥加密方案
| 密钥 | 密文 | 明文 |
|---|---|---|
| \(k \leftarrow \text{Gen}(1^n), \lvert k \rvert \geq n\) | \(c \leftarrow \text{Enc}_k(m)\),\(m \in \{0,1\}^*\) | \(m := \text{Dec}_k(c)\) |
-
如果对于所有 \(\text{PPT}\) 敌手 \(\mathcal{A}\) ,存在一个可忽略函数 \(\text{negl}\) 使得: $$ \Pr\left[\text{PrivK}^{\text{eav}}_{\mathcal{A},\Pi}(n) = 1\right] \leqslant \frac{1}{2} + \text{negl}(n) $$
则一个对称密钥加密方案 \(\Pi = (\text{Gen}, \text{Enc}, \text{Dec})\) 具备在窃听者存在的情况下不可区分的加密
使用一个固定比特 \(b\),用 \(\text{output}\left( \text{PrivK}^{\text{eav}}_{\mathcal{A},\Pi}(n,b) \right)\) 来表示 \(\mathcal{A}\) 在 \(\text{PrivK}^{\text{eav}}_{\mathcal{A},\Pi}(n,b)\) 中的输出比特 \(b'\),则有等价定义:
-
如果对所有的概率多项式时间的敌手 \(\mathcal{A}\) ,存在一个可忽略函数 \(\text{negl}\) 使得:
\[ \left| \Pr\left[ \text{output}\left( \text{PrivK}^{\text{eav}}_{\mathcal{A},\Pi}(n,0) \right) = 1 \right] - \Pr\left[ \text{output}\left( \text{PrivK}^{\text{eav}}_{\mathcal{A},\Pi}(n,1) \right) = 1 \right] \right| \leqslant \text{negl}(n) \]则对称密钥加密方案 \(\Pi = (\text{Gen}, \text{Enc}, \text{Dec})\) 具有窃听者存在的情况下不可区分性
3 伪随机发生器(Pseudorandom Generator, PRG)¶
3. 1 直观定义¶
直观上来看,如果没有多项式时间的区分器能够区分一个根据 \(D\) 采样的字符串和一个均匀随机选择的字符串,则一个分布 \(D\) 是伪随机的。
-
令 \(\ell(\cdot)\) 为多项式,\(G\) 为确定多项式时间算法,该算法满足:对于任何输入 \(s \in \{0,1\}^n\) ,算法 \(G\) 输出一个长度为 \(\ell(n)\) 的字符串。如果满足下面两个条件,则称 \(G\) 是一个伪随机发生器:
- (扩展性:)对每个 \(n\) 来说,满足 \(\ell(n) > n\)
- (伪随机性:)对所有的概率多项式时间的区分器 \(D\) 来说,存在一个可忽略函数 \(\text{negl}\) ,满足 $$ \left|\Pr[D(r) = 1] - \Pr[D(G(s)) = 1]\right| \leq \text{negl}(n) $$
其中 \(r\) 是从 \(\{0,1\}^{\ell(n)}\) 中均匀随机选择的,种子 \(s\) 是从 \(\{0,1\}^n\) 中均匀随机选择的,函数 \(\ell(\cdot)\) 被称为 \(G\) 的扩展系数。
3.2 计算不可区分性(Computational Indistinguishability)¶
概念补充
- 概率总体(Probability Ensemble)
- 无限的概率分布序列
- 若对每个自然数 \(n\) ,都存在一个概率分布 \(X_n\) ,则集合 \(\mathcal{X} = \{ X_n \}_{n \in \mathbb{N}}\) 称为一个概率总体
- 若分布 \(X_n\) 可通过某个函数 \(t\) 与另一序列的分布关联,即 \(X_n = Y_{t(n)}\) ,则概率总体可表示为 \(\{ Y_{t(n)} \}_{n \in \mathbb{N}}\)
- 高效可采样的概率总体(Efficiently Sampleable Probability Ensemble)
- 若概率总体 \(\mathcal{X} = \{ X_n \}_{n \in \mathbb{N}}\) 满足:存在一个概率多项式时间算法 \(S\) ,使得“算法 \(S\) 输入 \(1^n\) (长度为 \(n\) 的全 1 字符串,传递安全参数规模)后输出的随机变量”与“分布 \(X_n\) 的随机变量”同分布,则称 \(\mathcal{X}\) 是高效可采样的
计算不可区分性的实际定义与概率总体有关,以下是对两个分布不可区分的形式化定义:
-
两个概率总体 \(X = \{X_n\}_{n \in \mathbb{N}}\) 和 \(Y = \{Y_n\}_{n \in \mathbb{N}}\) 是计算不可区分的,表示为 \(X \stackrel{c}{\equiv} Y\),如果对于每一个概率多项式时间的区分器 \(D\) ,都存在一个可忽略函数 \(\text{negl}\),使得: $$ |\Pr[D(1^n, X_n) = 1] - \Pr[D(1^n, Y_n) = 1]| \leq \text{negl}(n) $$
其中标记 \(D(1^n, X_n)\) 表明 \(x\) 的选取符合分布 \(X_n\) ,然后运行 \(D(1^n, x)\) 。
计算不可区分性具有传递性,即:若 \(\mathcal{X} \stackrel{c}{\equiv} \mathcal{Y}\) 且 \(\mathcal{Y} \stackrel{c}{\equiv} \mathcal{Z}\),则 \(\mathcal{X} \stackrel{c}{\equiv} \mathcal{Z}\)
伪随机性只是计算不可区分性的一个特例,令 \(U_{l(n)}\) 表示 \(\{0,1\}^{l(n)}\) 上的均匀分布(uniform distribution),则有下列定义:
- 如果对于某个多项式 \(l\) ,全体 \(X\) 和全体 \(U = \{U_{l(n)}\}_{n \in \mathbb{N}}\) 是计算不可区分的,则全体 \(X = \{X_n\}_{n \in \mathbb{N}}\) 是伪随机的。
据此,我们可以对伪随机发生器重新进行定义:
- 令 \(l(\cdot)\) 是多项式,同时令 \(G\) 为(确定的)多项式时间算法,其中对于所有 \(s\) 有 \(|G(s)| = l(|s|)\) 成立。如果下列两个条件成立,就称 \(G\) 是伪随机发生器:
- (可扩展性:)对于每一个 \(n\) 有 \(l(n) > n\) 成立
- (伪随机性:)全体 \(\{G(U_n)\}_{n \in \mathbb{N}}\) 是伪随机的
4 构造安全加密方案¶
4. 1 一个安全的定长加密方案¶
伪随机发生器的加密方案
令 \(G\) 是一个带扩展因子 \(\ell\) 的伪随机发生器。定义一个消息长度为 \(\ell\) 的对称密钥加密方案如下:
- \(\text{Gen}\):输入 \(1^n\) ,输出密钥 \(k \leftarrow \{0,1\}^n\)
- \(\text{Enc}\):输入密钥 \(k \in \{0,1\}^n\) 和消息 \(m \in \{0,1\}^{\ell(n)}\) ,输出密文 \(c := G(k) \oplus m\)
- \(\textnormal{Dec}\):输入密钥 \(k \in \{0,1\}^n\) 和密文 \(c \in \{0,1\}^{\ell(n)}\) ,输出明文 \(m := G(k) \oplus c\)
- 若 \(G\) 是伪随机发生器,则上述加密方案是窃听者存在下的不可区分长密钥对称加密方案。
证明(教材中给出的证明方法)
假设存在概率多项式时间敌手 \(\mathcal{A}\) ,定义敌手优势: $$ \varepsilon(n) \stackrel{\text{def}}{=} \Pr\left[ \text{PrivK}^{\text{eav}}_{\mathcal{A},\Pi}(n) = 1 \right] - \frac{1}{2} $$
构造区分器 \(D\),指定字符串 \(w \in \{0,1\}^{\ell(n)}\) 作为输入,假设 \(n\) 能够被 \(\ell(n)\) 确定: 1. 运行 \(\mathcal{A}(1^n)\) 获取消息对 \(m_0, m_1 \in \{0,1\}^{\ell(n)}\) 2. 随机选比特 \(b \leftarrow \{0,1\}\) ,计算密文 \(c := w \oplus m_b\) 3. 将 \(c\) 给 \(\mathcal{A}\) ,若 \(\mathcal{A}\) 输出 \(b' = b\) ,则 \(D\) 输出 1,否则输出 0
-
当 \(w\) 是真随机串:此时加密等价于一次一密(完善保密),令 \(\widetilde{\Pi}\) 为带安全参数的一次一密方案,则: $$ \Pr\left[ D(w) = 1 \right] = \Pr\left[ \text{PrivK}^{\text{eav}}_{\mathcal{A},\widetilde{\Pi}}(n) = 1 \right] = \frac{1}{2} $$
-
当 \(w = G(k)\):此时加密是方案 \(\Pi\) ,故 $$ \Pr\left[ D(G(k)) = 1 \right] = \Pr\left[ \text{PrivK}^{\text{eav}}_{\mathcal{A},\Pi}(n) = 1 \right] = \frac{1}{2} + \varepsilon(n) $$
由上述分析,区分器 \(D\) 对真随机串和 \(G\) 输出的区分优势为: $$ \left| \Pr\left[ D(w) = 1 \right] - \Pr\left[ D(G(k)) = 1 \right] \right| = \varepsilon(n) $$
因为 \(G\) 是伪随机发生器,所以 \(\varepsilon(n)\) 必须是可忽略函数,结合 \(\varepsilon(n)\) 的定义可得,加密方案 \(\Pi\) 满足“窃听者存在下的不可区分加密”,证毕。
证明(作规约图证明)
运用反证法,假设存在敌手 A 能攻破上述加密方案的 EAV-安全,则可以构造一个敌手 B 来攻破 PRG 的安全性
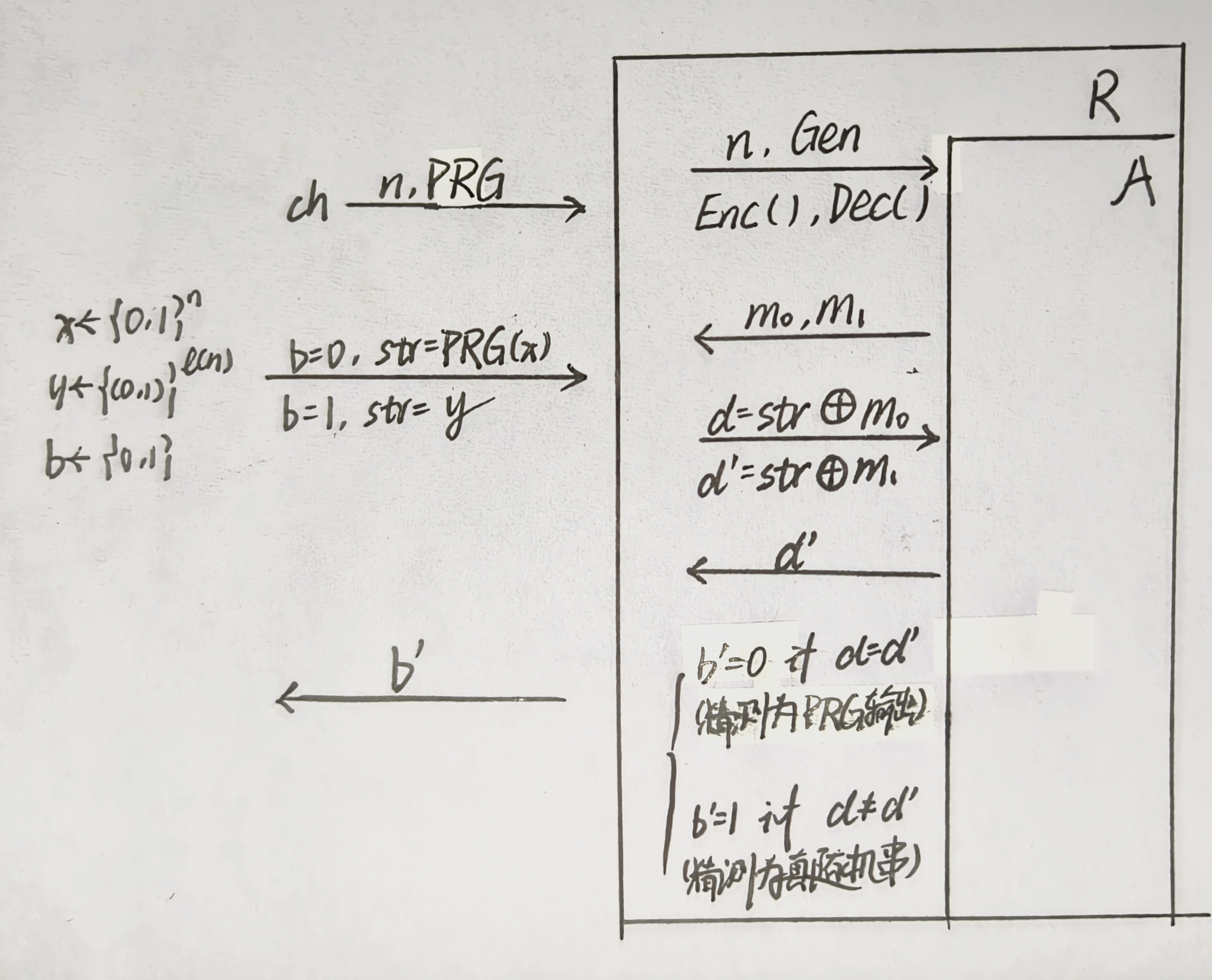
作规约图如上,假设 \(Pr[\text{A wins EAV}] = \frac{1}{2} + \Delta\),其中 \(\Delta\) 表示 not small,则: $$ \begin{aligned} Pr[R^A \text{ wins PRG}] &= P[b = 0] \cdot Pr[R^A \text{ wins} \mid b = 0] + P[b = 1] \cdot Pr[R^A \text{ wins} \mid b = 1] \\ &= \frac{1}{2}Pr[\text{A wins EAV}] + \frac{1}{2} \cdot \frac{1}{2} = \frac{1}{2} + \frac{\Delta}{2} \end{aligned} $$
说明 \(R^A\) 可以攻破 PRG,矛盾!故有 EAV-Secure.
注意
上面的规约图画得有一点小问题,但差不多是这个意思。
Tip
其实上述两种证明方法本质上是一样的,本门课程中通常使用作规约图证明的方法。
4. 2 处理变长消息¶
- 一个确定的多项式时间算法 \(G\),如果满足以下三个条件,则 \(G\) 是一个输出长度可变的伪随机发生器,如果满足以下条件:
- 令 \(s\) 为一个字符串,整数 \(\ell > 0\),则 \(G(s,1^\ell)\) 输出一个长度为 \(\ell\) 的字符串
- 对所有的 \(s, \ell, \ell'\), \(\ell < \ell'\),字符串 \(G(s,1^\ell)\) 是 \(G(s,1^{\ell'})\) 的前缀
- 定义 \(G_\ell(s) \stackrel{\text{def}}{=} G(s,1^{\ell(|s|)})\),则对于每个多项式 \(\ell(\cdot)\),有 \(G_\ell\) 是一个扩展因子为 \(\ell\) 的伪随机发生器
任何标准的伪随机发生器都能够被转化成为一个输出长度可变的伪随机发生器。与定长加密方案相似的,可以给出构造方案: $$ c := G(k,1^{|m|}) \oplus m,m := G(k,1^{|c|}) \oplus c $$
4. 3 流密码(Stream Ciphers)和多个加密¶
上述构造方案被称作流密码,其加密的执行是先生成一个伪随机比特流,然后将该比特流和明文做异或运算。
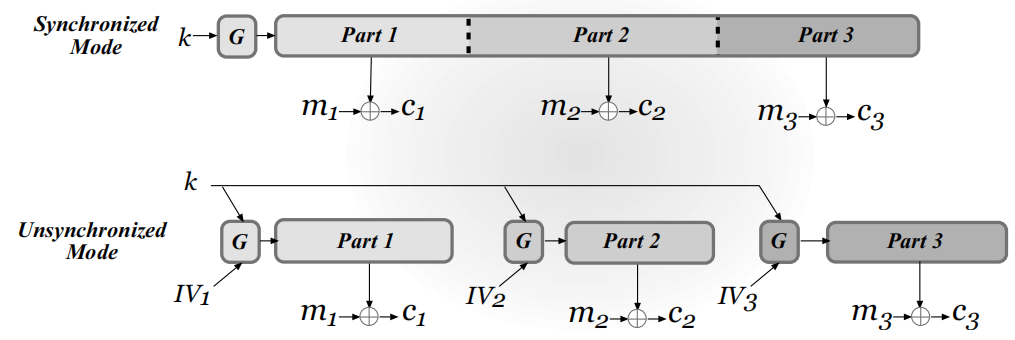
流密码的两种工作机制
流密码有同步模式与非同步模式两种工作机制:
多消息窃听实验 \(\text{PrivK}^{\text{mult}}_{\mathcal{A},\Pi}(n)\)
- 敌手 \(\mathcal{A}\) 被给定输入 \(1^n\) ,输出一对消息向量 \(\vec{M_0} = (m_0^1, \dots, m_0^t)\) 以及 \(\vec{M_1} = (m_1^1, \dots, m_1^t)\) ,对于所有 \(i\) ,满足 \(|m_0^i| = |m_1^i|\)
- 通过运行 \(\text{Gen}(1^n)\) 生成一个密钥 \(k\) 和选择一个随机比特 \(b \leftarrow \{0,1\}\) 。对于所有 \(i\) ,计算密文 \(c^i \leftarrow \text{Enc}_k(m_b^i)\) ,并且将密文向量 \(\vec{C} = (c^1, \dots, c^t)\) 给 \(\mathcal{A}\)
- \(\mathcal{A}\) 输出一个比特 \(b'\)
- 如果 \(b' = b\) ,该实验的输出为 \(1\),否则输出 \(0\)。
-
一个对称密钥加密方案 \(\Pi = (\text{Gen}, \text{Enc}, \text{Dec})\),如果对所有的概率多项式时间敌手 \(\mathcal{A}\),存在一个可忽略函数 \(\text{negl}\),满足 $$ \Pr\left[ \text{PrivK}^{\text{mult}}_{\mathcal{A},\Pi}(n) = 1 \right] \leqslant \frac{1}{2} + \text{negl} $$
则称其具备窃听者存在的情况下不可区分多次加密。
值得注意的,单个加密的安全并不意味着在多次加密下的安全,即:
- 存在这样的对称密钥加密方案,满足窃听者存在情况下不可区分的加密,但不满足窃听者存在情况下不可区分的多次加密。
证明
仍然使用前面构造的加密方案,其单次加密的安全性已经得证,构造敌手 \(\mathcal{A}\) 参与多消息窃听实验 \(\text{PrivK}^{\text{mult}}_{\mathcal{A},\Pi}(n)\) ,执行如下操作:
-
输出消息向量 \(\vec{M_0} = (0^n, 0^n)\) 和 \(\vec{M_1} = (0^n, 1^n)\),满足所有位置明文长度相等
-
接收密文向量 \(\vec{C} = (c^1, c^2)\) ,若 \(c^1 = c^2\) 则输出 \(b' = 0\) ,否则输出 \(b' = 1\)
我们采用的构造方法的加密函数 \(\text{Enc}\) 是确定函数,相同密钥和明文会产生相同密文,所以有:
-
若 \(b = 0\) :加密 \(\vec{M_0}\) ,两个明文均为 \(0^n\) ,故 \(c^1 = \text{Enc}_k(0^n) = c^2\) ,敌手输出 \(b' = 0 = b\)
-
若 \(b = 1\) :加密 \(\vec{M_1}\) ,明文分别为 \(0^n\) 和 \(1^n\) ,故 \(c^1 = \text{Enc}_k(0^n) \neq \text{Enc}_k(1^n) = c^2\) ,敌手输出 \(b' = 1 = b\)
综上,敌手 \(\mathcal{A}\) 输出 \(b' = b\) 的概率为 \(1\),该加密方案不具备窃听者存在情况下的不可区分多次加密,命题得证
根据以上可以知道,相同消息被重复发送是危险的,概率加密是必要的,可形式化为以下定理:
- 令 \(\Pi = (\text{Gen}, \text{Enc}, \text{Dec})\) 为一个加密方案, \(\text{Enc}\) 是密钥和消息的一个确定函数,则 \(\Pi\) 不具备窃听者存在情况下不可区分多次加密。
4. 4 提高扩展系数¶
- 如果存在扩展系数为 \(l(n) = n + 1\) 的伪随机发生器 \(\hat{G}\),那么对于任意多项式 \(p(n) > n\),存在扩展系数为 \(l(n) = p(n)\) 的伪随机发生器 \(G\)
构造方法
令输入的种子 \(s \in \{0,1\}^n\),则 \(G'\) 的构造方法如下:
- 令 \(p'(n) = p(n) - n\),这是所期望的 \(G\) 对输入长度的扩展量
- 设 \(s_0 := s\) ,对于 \(i = 1, \cdots, p'(n)\) ,则:
- 令 \(s'_{i-1}\) 表示 \(s_{i-1}\) 的开始 \(n\) 比特,令 \(\sigma_{i-1}\) 表示剩下的 \(n - 1\) 比特(当 \(i = 1\) 时, \(\sigma_0\) 为空串)
- 设 \(s_i := (\hat{G}(s'_{i-1}), \sigma_{i-1})\)
- 输出 \(s_{p'(n)}\)
简而言之,就是如果我们有一个 “每次能多造 \(1\) 位伪随机数” 的基础工具,想造多长的伪随机串,就把这个工具反复用多少次,每次多攒 \(1\) 位,最后凑出需要的长度。
温馨提示
有时我们使用 \(||\) 表示拼接,例如上式可以写作 \(s_i := \hat{G}(s'_{i-1}) \, || \, \sigma_{i-1}\)
5 选择明文攻击(CPA)的安全性¶
加密预言机 (encryption oracle) 可视为一个黑盒子,会使用密钥 \(k\) 加密 \(\mathcal{A}\) 选择的消息,在 选择明文攻击 (chosen-plaintext attacks) 中,敌手 \(\mathcal{A}\) 被允许和加密预言机自由交互。当 \(\mathcal{A}\) 询问预言机并提供明文消息 \(m\) 作为输入时,预言机将返回密文 \(c \leftarrow \text{Enc}_k(m)\),当 \(\text{Enc}\) 是随机的时,预言机每次回答一个询问时都会保证新的随机性。
安全性的定义要求:即使 \(\mathcal{A}\) 具备访问加密预言机能力, \(\mathcal{A}\) 也不能区分两个任意消息的加密。
CPA 不可区分实验 \(\text{PrivK}^{\text{cpa}}_{\mathcal{A},\Pi}(n)\)
- \(k \leftarrow \text{Gen}(1^n)\)
- 输入 \(1^n\) 给敌手 \(\mathcal{A}\),敌手 \(\mathcal{A}\) 可以访问预言机 \(\text{Enc}_k(\cdot)\) ,输出一对长度相等的消息 \(m_0, m_1\)
- \(b \leftarrow \{0,1\}\),\(c \leftarrow \text{Enc}_k(m_b)\),交给 \(\mathcal{A}\)
- 敌手 \(\mathcal{A}\) 继续访问预言机 \(\text{Enc}_k(\cdot)\) ,输出一个比特 \(b'\)
- 如果 \(b = b'\),该实验的输出被定义为 \(1\),否则定义为 \(0\),若 \(\text{PrivK}^{\text{cpa}}_{\mathcal{A},\Pi}(n) = 1\) ,则认为 \(\mathcal{A}\) 成功
-
一个对称密钥加密方案 \(\Pi = (\text{Gen}, \text{Enc}, \text{Dec})\),如果对所有的概率多项式敌手 \(\mathcal{A}\),存在一个可忽略函数 \(\text{negl}\),使得 $$ \Pr\left[ \text{PrivK}^{\text{cpa}}_{\mathcal{A},\Pi}(n) = 1 \right] \leqslant \frac{1}{2} + \text{negl}(n) $$
则是选择明文攻击(CPA)条件下的不可区分加密。
任何方案如果是选择明文攻击条件下的不可区分加密,则也是窃听者存在的情况下不可区分加密,因为 \(\text{PrivK}^{\text{eav}}\) 是 \(\text{PrivK}^{\text{cpa}}\) 的一种特殊情况,即敌手没有使用预言机。
和多次加密的安全一样,任何确定加密方案都不能抵御选择明文攻击,即:任何 CPA 安全的加密方案必须是概率性的。
LR 预言机实验 \(\text{PrivK}^{\text{LR-cpa}}_{\mathcal{A},\Pi}(n)\)
- \(k \leftarrow \text{Gen}(1^n)\),\(b \leftarrow \{0,1\}\)
- 输入 \(1^n\) 给敌手 \(\mathcal{A}\),敌手 \(\mathcal{A}\) 可以访问预言机 \(\text{LR}_{k,b}(\cdot,\cdot)\)
- 敌手 \(\mathcal{A}\) 输出一个比特 \(b'\)
- 如果 \(b = b'\),该实验的输出被定义为 \(1\),否则定义为 \(0\),若 \(\text{PrivK}^{\text{LR-cpa}}_{\mathcal{A},\Pi}(n) = 1\) ,则认为 \(\mathcal{A}\) 成功
相似的,将 CPA 单次加密扩展到多次加密,则有:
-
一个对称密钥加密方案 \(\Pi = (\text{Gen}, \text{Enc}, \text{Dec})\),如果对所有的概率多项式敌手 \(\mathcal{A}\),存在一个可忽略函数 \(\text{negl}\),使得 $$ \Pr\left[ \text{PrivK}^{\text{LR-cpa}}_{\mathcal{A},\Pi}(n) = 1 \right] \leqslant \frac{1}{2} + \text{negl}(n) $$
则是选择明文攻击(CPA)条件下的不可区分多次加密。
温馨提示
CPA 实验是敌手先自由要密文,再选消息对赌密文;LR 实验是敌手直接和预言机赌加密的是左消息还是右消息,两者本质等价,但交互形式和预言机功能不同,LR 实验更直接地刻画了 CPA 下的不可区分性,可直接运用于多次加密。
与窃听敌手(EAV)的情况不同的是,单次加密的 CPA 安全即意味着多次加密的 CPA 安全,即:
- 任何在选择明文攻击条件下的不可区分加密的对称密钥加密方案,也是在选择明文攻击条件下的不可区分多次加密方案。
证明:混合论证(Hybrid Argument)
定义 \(n+1\) 个中间游戏 \(\text{Game}_0, \text{Game}_1, \dots, \text{Game}_n\),其中 \(\text{Game}_k\) 规则为对第 \(1 \sim k\) 个消息对用 \(b=1\) 处理,对第 $k+1 \sim n $个消息对用 \(b=0\) 处理,其返回的密文序列为:
考虑相邻游戏 \(\text{Game}_k\) 和 \(\text{Game}_{k+1}\),二者仅第 \(k+1\) 个消息对的处理方式不同,即只相差一次 CPA,则:
因此,\(\mathcal{A}\)在\(\text{Game}_k\)和\(\text{Game}_{k+1}\)中的区分优势,等于\(\mathcal{B}\)在IND-CPA中的优势:
由 IND-CPA 的安全性知 \(\text{Adv}_{\text{IND-CPA}}(\mathcal{B})\) 是可忽略的,则 \(\text{Game}_k\) 与 \(\text{Game}_{k+1}\) 不可区分,则:
\(\therefore \text{Adv}_{\text{LR-IND-CPA}}(\mathcal{A}) \leq \sum_{k=0}^{n-1} \text{Adv}_{\text{IND-CPA}}(\mathcal{B}_k)\),为可忽略函数
6 CPA 安全的加密方案构建¶
6. 1 基于伪随机函数的 CPA 安全加密¶
伪随机函数(PRFs, Pseudorandom functions)
令 \(F:\{0,1\}^*×\{0,1\}^*→\{0,1\}^*\) 是有效的、长度保留的、带密钥的函数。如果对所有多项式时间区分器 \(D\),存在一个可忽略函数 \(\text{negl}\),满足: $$ \left| \Pr\left[D^{F_k(\cdot)}(1^n) = 1\right] - \Pr\left[D^{f(\cdot)}(1^n) = 1\right] \right| \leq \text{negl}(n) $$
则称 \(F\) 是一个伪随机函数,其中 \(k \leftarrow \{0,1\}^n\) 是均匀随机选择的,并且 \(f\) 是从将 \(n\) 比特字符串映射到 \(n\) 比特字符串的函数集合中均匀随机选择出来的。
-
设 \(F\) 是一个伪随机函数,则有构造 CPA 安全的加密方案如下:
密钥 密文 明文 \(k \leftarrow \text{Gen} \, (1^n)\) \(c := <r , F_{k}(r) \oplus m>\) \(m := F_{k}(r) \oplus s\) 其中 \(r\) 为随机数,\(s = F_{k}(r) \oplus m\)
6. 2 伪随机置换和分组加密¶
伪随机置换 (Pseudorandom Permutations)
令 \(F:* \times \{0,1\}^* \to \{0,1\}^*\)是有效的、长度保留的、带密钥的函数。如果对每个 \(k\),函数 \(F_k(\cdot)\) 是单射(因为 \(F\) 是长度保留的,因而 \(F_k\) 实际上是双射)。把 \(F\) 称作一个带密钥的置换。如果给定 \(k\) 和 \(x\),存在一个多项式时间算法能够计算 \(F_k(x)\),并且如果给定 \(k\) 和 \(x\),也存在一个多项式时间算法能够计算 \(F_k^{-1}(x)\),则这个带密钥的置换是有效的。
对于空间 \(\{0,1\}^n\),\(size(\text{Perm}_n) = (2^n)!\)
- 如果 \(F\) 是一个伪随机置换,则也是一个伪随机函数。
强伪随机置换
令 \(F:\{0,1\}^* \times \{0,1\}^* \to \{0,1\}^*\) 是有效的带密钥的置换。如果对于所有概率多项式时间区分器 \(D\),存在一个可忽略函数 \(\mathrm{negl}\),使得
则称 \(F\) 是强伪随机置换,其中 \(k \leftarrow \{0,1\}^n\) 是随机均匀选择的,\(f\) 是从 \(n\) 比特字符串置换的集合中均匀随机选择的。
6. 3 加密操作模式¶
模式 1:电子密码本(ECB)模式¶
给定一个明文消息 \(m = m_1, m_2, \cdots, m_\ell\),密文 \(c = \langle F_k(m_1), F_k(m_2), \cdots, F_k(m_\ell) \rangle\),解密过程使用有效可计算的\(F_k^{-1}\)。
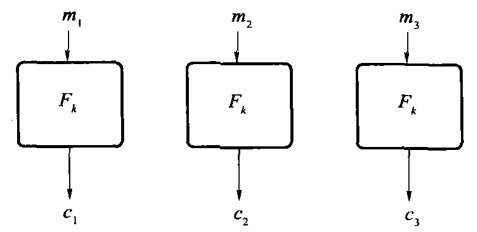
这里,加密过程是确定性的,因此,该操作模式不可能是 CPA 安全的;且在窃听者存在的情况下,ECB 加密模式并不具备不可区分性。因此,ECB 模式应该永远不被使用。
模式 2:密码分组链接(CBC)模式¶
选择一个长度为 \(n\) 的随机初始向量(\(IV\)),令\(c_0 := IV\),\(c_i := F_k(c_{i-1} \oplus m_i)\),\(c := \langle c_0, c_1, \cdots, c_\ell \rangle\),其中 \(IV\) 不加密并作为密文的一部分发送。
CBC 模式的加密是概率的,如果 \(F\) 为伪随机置换,那么 CBC 加密模式是 CPA 安全的。该模式的主要缺陷是加密必须依次执行,因此,如果并行处理是可行的,则 CBC 模式不是最有效率的选择。
变体:在每次加密时使用不同的\(IV\)(而不是随机的\(IV\))
不安全!
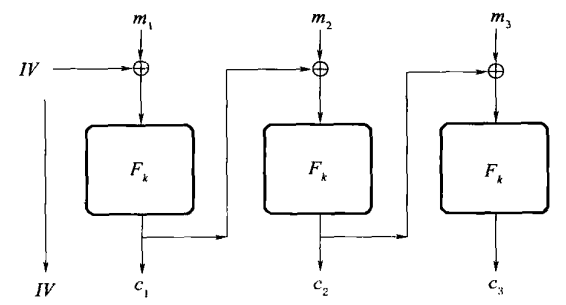
模式 3:输出反馈(OFB)模式¶
本质上是使用分组密码来生成伪随机流,然后和消息作异或操作。选择一个随机 \(IV \leftarrow \{0,1\}^n\),令 \(r_0 := IV\),\(r_i := F_k(r_{i-1})\),\(c_i := m_i \oplus r_i\)。
和 CBC 模式一样,为了解密,\(IV\) 是密文的一部分;相对于 CBC 模式,这里不需要 \(F\) 是可逆的(事实上,\(F\)甚至不需要是个置换)。
该模式也是概率的,如果 \(F\) 是伪随机函数,则它是 CPA 安全的加密方案。这里,加密和解密都必须依次执行。该模式的优点是大块的计算(也就是伪随机流的计算)能够独立于实际加密消息进行。所以,在预处理之前,准备好一个流是可能的,此后加密明文(一旦已知)是非常快的。
模式4:计数器(CTR)模式¶
有很多不同的 CTR 加密模式的变体,这里描述随机化的计数器模式。和 OFB 一样,计数器模式能够看成是一种用分组密码生成伪随机流的方法。
选择一个随机 \(IV \leftarrow \{0,1\}^n\) 并用ctr表示,令 \(r_i := F_k(\text{ctr} + i)\)(其中 \(\text{ctr}\) 和 \(i\) 被看作是整数,加法是模 \(2^n\) 的加法),\(c_i := r_i \oplus m_i\),\(IV\) 再次作为密文的一部分发送。该解密不要求\(F\)是可逆的,甚至不要求是置换。
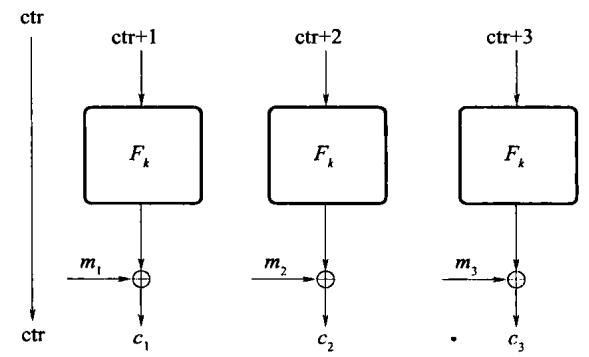
随机计数模式是 CPA 安全的;加密和解密都能完全并行;只解密第 \(i\) 个密文分组而不解密任何其他的密文是可能的,该特点被叫做随机访问。
? 单向函数(One-Way Functions)¶
求逆实验 \(\text{Invert}_{\mathcal{A},f}(n)\)
- \(x \leftarrow \{0,1\}^n\) ,\(y := f(x)\)
- \(1^n\) 和 \(y\) 作为 \(\mathcal{A}\) 的输入,输出为 \(x'\)
- 如果 \(f(x') = y\) ,那么定义该实验的输出为 \(1\),否则为 \(0\)
- 如果一个函数 \(f : \{0,1\}^* \to \{0,1\}^*\) 满足下述两个条件,那么它就是单向函数:
- (Easy to compute:)存在一个多项式时间算法 \(M_f\) 来计算 \(f\) ;也就是说,对所有 \(x\) ,有 \(M_f(x) = f(x)\)
- (Hard to invert:)对任意概率多项式时间算法 \(\mathcal{A}\) ,存在一个可忽略函数 \(\text{negl}\) ,满足 $$ \Pr\left[ \text{Invert}_{\mathcal{A},f}(n) = 1 \right] \leqslant \text{negl}(n) $$
温馨提示
上式第二条可用符号表示法表述为: $$ \Pr_{x \leftarrow {0,1}^n}\left[ \mathcal{A}(f(x)) \in f^{-1}(f(x)) \right] \leqslant \text{negl}(n) $$