Chapter 7 Relational Database Design¶
1 Functional Dependencies¶
函数依赖(Functional Dependency, FD)是加在关系模式上的约束,用来描述一组属性的取值能否唯一确定另一组属性的取值,记作 \(\alpha \to \beta\)。
其含义是:在关系模式 \(R\) 的任意合法实例中,只要两个元组在 \(\alpha\) 上取值相同,它们在 \(\beta\) 上也必须相同,即:
示例:inst_dept(ID, name, salary, dept_name, building, budget)
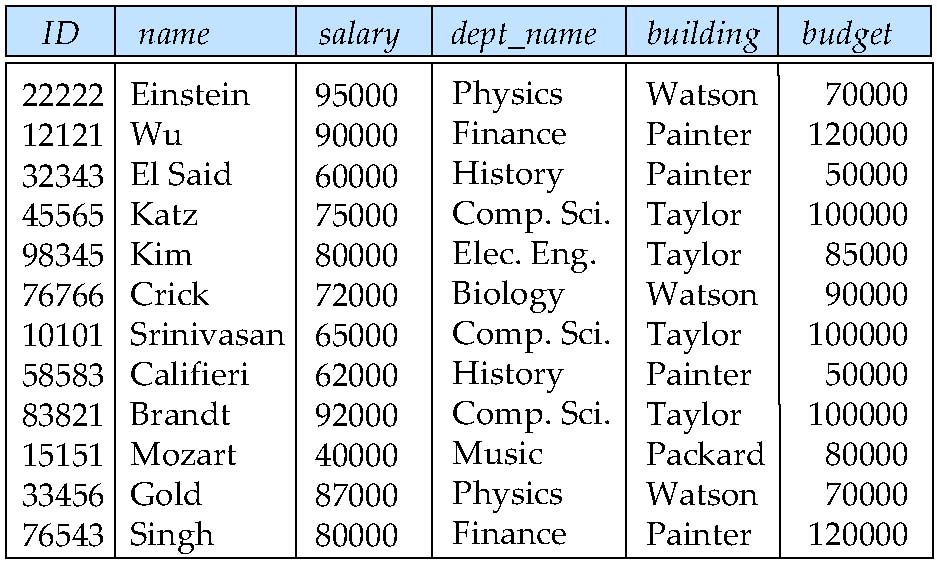
我们通常期望:
dept_name → building, budgetID → name, salary, dept_name, building, budget
但不会期望:
dept_name → salary
函数依赖是键概念的推广。
- Superkey(超键):若 \(K → R\),则 \(K\) 是关系模式 \(R\) 的超键。
- Candidate Key(候选键):若 \(K → R\),且任意真子集 \(α ⊂ K\) 都不满足 \(α → R\),则 \(K\) 是候选键。
平凡函数依赖(Trivial FDs)
若 \(β ⊆ α\),则 \(α → β\) 一定成立,称为平凡函数依赖(trivial FD),例如:ID, name → ID,name → name。
对非平凡 FD \(α → β\),判断好坏时要看两件事:
α是否是超键β中是否包含候选键中的属性(prime attribute)
这正好对应:
- BCNF:要求非平凡 FD 的左边必须是超键
- 3NF:允许一部分左边不是超键的 FD 存在,但右边必须是主属性
FD 的用途
- 指定合法关系必须满足的约束
- 测试某个关系实例是否合法
- 判断关系模式是否处于良好范式(good form),在需要时进行分解(decompose)
- 在少数场景下进行合并(combine)
注意
某个具体关系实例可能碰巧满足一个 FD,但并不代表这个 FD 是该模式上的真实业务约束。
例如:某张 instructor 表当前可能刚好满足 name → ID,但这通常不是合法设计中应成立的依赖。
合并
对于 dept_building(dept_name, building) 和 dept_budget(dept_name, budget),若二者都由同一个决定因素 dept_name 控制,则可以合并成 department(dept_name, building, budget) 且不会引入重复。
2 Normal Forms¶
- 原子域(Atomic Domain):如果一个属性域中的值被当作不可再分的原子单位(atomic)使用,则称该域是原子的。
示例:非原子域
- 属性值是一个集合
- 复合属性直接塞进一个字段
- 编码后可以再拆出业务含义的值
2. 1 First Normal Form¶
若关系模式中所有属性的域都是原子的,则该关系模式属于第一范式(First Normal Form, 1NF)。
- 1NF 让关系模型中的每个单元格只放一个原子值,避免非原子值带来的存储复杂性和重复存储。
规范化(Normalization)
- 目标:判断一个关系模式 \(R\) 是否处于良好范式,若不是,则把它分解为一组更好的关系模式 \({R_1, R_2, …, R_n}\),使得每个分解后的关系模式均符合良好范式,且该分解为无损连接分解。理想情况下,该分解还应具备依赖保持性。
- 理论基础:函数依赖(functional dependencies)和多值依赖(multivalued dependencies)。
2. 2 BCNF¶
关系模式 \(R\) 相对于 FD 集 \(F\) 属于 BCNF,当且仅当对 \(F^+\) 中任意形如 \(α → β\) 的函数依赖,只要它是非平凡的,就必须满足 \(α\) 是 \(R\) 的超键。
BCNF 违反示例
对关系 inst_dept(ID, name, salary, dept_name, building, budget),若有 dept_name → building, budget,由于 dept_name 不是超键,因此该关系不在 BCNF 中。
若存在非平凡 FD \(α → β\) 违反 BCNF,则可把关系 \(R\) 分解为:
示例:对 inst_dept 的分解
令 α = dept_name,β = {building, budget},则可分解为:
department(dept_name, building, budget)instructor(ID, name, salary, dept_name)
这样就把院系决定楼和预算的依赖放到了单独的关系中。
Lossless Join
对分解 \(R → R_1, R_2\),若对 \(R\) 的所有合法实例 \(r\) 都有:
则称该分解是无损连接分解(lossless-join decomposition)。
对于二元分解,一个常用充分条件是:\(R_1 ∩ R_2 → R_1\) 或 \(R_1 ∩ R_2 → R_2\)。
Lossy Join
若分解后再自然连接,可能产生原关系中并不存在的元组,则是有损分解(lossy decomposition)。
错误分解会产生伪元组
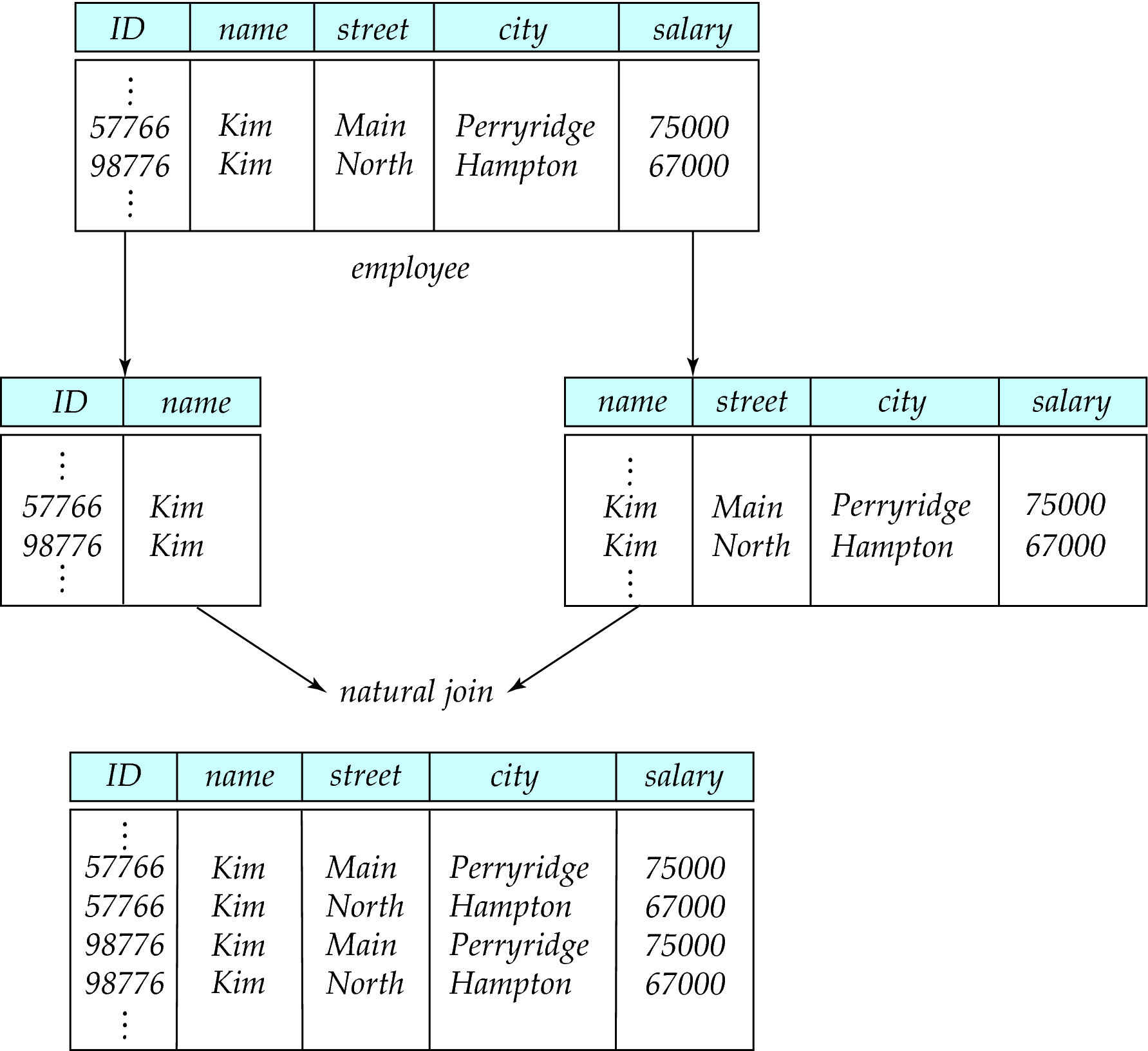
图中把 employee(ID, name, street, city, salary) 错误地分成:
employee_1(ID, name)employee_2(name, street, city, salary)
由于 name 不是键,连接后会把同名的 Kim 错误交叉组合,产生虚假的结果。
注意
不是分得越细越好,如果原关系中所有非平凡 FD 的左边本来都是超键,就不应该再机械分解。
2. 3 Third Normal Form¶
依赖保持(Dependency Preservation)
若一个分解只需要在各个子关系内部检查依赖,就能保证原来所有 FD 都成立,则该分解是保持依赖的(dependency preserving)。
形式化地,设 \(F_i\) 是 \(F^+\) 在 \(Ri\) 上的投影,则若:
则分解保持依赖。
关系模式 \(R\) 相对于 \(F\) 属于 第三范式(Third Normal Form, 3NF),当且仅当对 \(F^+\) 中任意 \(α → β\),至少满足以下之一:
- \(α → β\) 是平凡的
- \(α\) 是超键
- \(β - α\) 中的每个属性都属于某个候选键
注:第三条允许了一定程度的冗余,因此 3NF 是对 BCNF 的最小放松。
示例
设 advisor(s_id, i_id, dept_name),一个学生在某个院系中至多有一个导师,则有以下重要 FD:
s_id, i_id → dept_namei_id → dept_names_id, dept_name → i_id
若拆成 advisor(s_id, i_id) 和 instructor(i_id, dept_name),虽减少了重复,但检查同一院系至多一个导师就必须连接两表。 因此 3NF 允许保留适度冗余,以换取依赖保持。
BCNF 仍会有插入异常
对于关系模式 inst_info(ID, child_name, phone),一个教师可能有多个孩子,也可能有多个电话号码。
该关系没有非平凡 FD,因此形式上属于 BCNF,但若增加一个新电话号码,就要把它与该教师的每个孩子组合出多条元组,因此更合理的做法是拆成 inst_child(ID, child_name) 和 inst_phone(ID, phone_number)。
这说明仅靠 FD 和 BCNF 还不够,需要引入 MVD / 4NF。
2. 4 Fourth Normal Form¶
关系模式 \(R\) 相对于依赖集 \(D\) 属于 4NF,当且仅当对 D+ 中任意 α ⇉ β,至少满足 \(α \twoheadrightarrow β\) 是平凡的或 \(α\) 是超键。
- 4NF 是针对 MVD 的 BCNF,若一个关系在 4NF 中,则它一定也在 BCNF 中
4NF 分解
若 \(α \twoheadrightarrow β\) 非平凡且 \(α\) 不是超键,则像 BCNF 一样分解为 \(R_1 = α ∪ β\) 和 \(R_2 = R - (β - α)\)。
4NF 分解算法保证结果关系都在 4NF,且分解是 lossless-join。
示例:\(R=(A, B, C, G, H, I)\),\(F=\{A \twoheadrightarrow B, B \twoheadrightarrow HI, CG \twoheadrightarrow H\}\)
-
\(A \twoheadrightarrow B\) 中的 \(A\) 不是 \(R\) 的超键,故分解为 \(R_1 = (A, B)\) 和 \(R_2 = (A, C, G, H, I)\)
-
\(CG \twoheadrightarrow H\) 中的 \(CG\) 不是 \(R_2\) 的超键,故分解为 \(R_{21} = (C, G, H)\) 和 \(R_{22} = (A, C, G, I)\)
-
\(A \twoheadrightarrow I\) 中的 \(A\) 不是 \(R_{22}\) 的超键,故分解为 \(R_{221} = (A, I)\) 和 \(R_{222} = (A, C, G)\)
Restriction of MVD
当把依赖集 \(D\) 限制到某个子关系 \(R_i\) 上时,得到的 \(D_i\) 包括:
- \(D^+\) 中所有只涉及 \(R_i\) 属性的 FD
- 以及所有形如 \(α \twoheadrightarrow (β ∩ R_i)\) 的 MVD,其中 \(α ⊆ R_i\) 且 \(α \twoheadrightarrow β ∈ D^+\)
4NF 检查与 4NF 分解算法都依赖这种投影到子关系的思想。
3 Functional Dependency Theory¶
3. 1 Function Closure¶
给定一组 FD \(F\),由它逻辑推出的全部 FD 构成 \(F^+\),称为 \(F\) 的闭包(Closure)。
\(F^+\) 的朴素迭代算法
F+ = F
repeat
for each functional dependency f in F+
apply reflexivity and augmentation rules on f
add the resulting functional dependencies to F+
for each pair of functional dependencies f1 and f2 in F+
if f1 and f2 can be combined using transitivity
then add the resulting functional dependency to F+
until F+ does not change any further
3. 2 Armstrong’s Axioms¶
- Reflexivity(自反律):若 \(β ⊆ α\),则 \(α → β\)
- Augmentation(增广律):若 \(α → β\),则 \(γα → γβ\)
- Transitivity(传递律):若 \(α → β\) 且 \(β → γ\),则 \(α → γ\)
以上规则满足 sound(不会推出错误依赖)和 complete(能推出所有逻辑可推出的依赖)的特点,并且可以进一步推出以下规则:
- Union(合并):若 \(α → β\) 且 \(α → γ\),则 \(α → βγ\)
- Decomposition(分解):若 \(α → βγ\),则 \(α → β\) 且 \(α → γ\)
- Pseudotransitivity(伪传递):若 \(α → β\) 且 \(γβ → δ\),则 \(αγ → δ\)
3. 3 Attribute Closure¶
给定属性集 \(α\),在 FD 集 \(F\) 下可由 \(α\) 推出的全部属性集合记为 \(α^+\)。
\(\alpha ^ +\) 的标准算法
result := a;
while (changes to result) d
for each β → γ in F do
begin
if β ⊆ result then result := result ∪ γ
end
示例
已知关系模式 \(R = (A, B, C, G, H, I)\),函数依赖集 \(F\): \(A \to B\), \(A \to C\), \(CG \to H\), \(CG \to I\), \(B \to H\),求 \((AG)^+\) 并判断 \(AG\) 是否为候选键。
解答
- result = \(AG\)
- result = \(ABCG\)(由 \(A \to C\) 与 \(A \to B\) 推导)
- result = \(ABCGH\)(由 \(CG \to H\) 与 \(CG \subseteq AGBC\) 推导)
- result = \(ABCGHI\)(由 \(CG \to I\) 与 \(CG \subseteq AGBCH\) 推导)
由 \((AG)^+ = ABCGHI = R\) 可知 \(AG\) 为超键,又 \(A^+ = ABCH\),\(G^+ = G\),\(AG\) 的任何真子集都不是超键,所以 \(AG\) 是候选键。
\(\alpha ^ +\) 的用途
- 测试超键:若 \(\alpha ^ +\) 包含 \(R\) 的全部属性,则 \(α\) 是超键
- 测试某个 FD 是否在 \(F^+\) 中:若 \(β ⊆ α^+\),则 \(α → β\) 成立
- 计算 \(F^+\):先算每个属性集的闭包,再基于闭包枚举所有依赖关系
- 辅助找候选键
3. 4 Find all Candidate Keys¶
- 若某属性只出现在非平凡 FD 的左边,它通常应出现在某个候选键中
- 若某属性只出现在非平凡 FD 的右边,它通常不应出现在候选键中
- 若某属性完全不出现在任何非平凡 FD 中,它必须出现在候选键中
示例
- \(R=(A,B,C,D,E), F={AB→C, B→D, AD→E}\) 的候选键是 \(AB\)
- \(R=(A,B,C,D,E), F={AC→BD, B→A}\) 的候选键是 \(ACE\) 和 \(BCE\)
3. 5 Canonical Cover¶
一个 FD 集的正则覆盖(canonical cover)是与原 FD 集等价、但去掉了一切冗余依赖和冗余属性的最简形式,其中所有函数依赖的左部均唯一。
无关属性(Extraneous Attribute)
考虑函数依赖集 \(F\) 以及其中的函数依赖 \(\alpha \to \beta\):
- 左部(LHS):若 \(\alpha - A\) 在原 \(F\) 的闭包 \((\alpha - A)^+_F\) 包含 \(\beta\),则称 \(A\) 是 \(\alpha\) 中的无关属性
- 右部(RHS):若属性 \(A \in \beta\) 去掉后,删掉右部 \(A\) 之后的新依赖 \(α → (β−A)\) 能被 \(F\) 推出,则称 \(A\) 是 \(\beta\) 中的无关属性
示例
- 给定函数依赖集 \(F = \{A \to B,\ B \to C,\ AB \to C\}\),由 \(A^+ = ABC\) 得 \(AB \to C\) 中的 \(B\) 是无关属性。
- 给定函数依赖集 \(F = \{A \to C,\ AB \to CD\}\),由于在 \(F' = \{A \to C,\ AB \to D\}\) 下有 \(AB^+ = ABCD\),故 \(AB \to CD\) 中的 \(C\) 是无关属性。
正则覆盖的计算思路
- 用 union 把左部相同的依赖合并
- 不断检查左边和右边是否有无关属性
- 删除冗余部分
- 重复直到不再变化
示例
已知关系模式:\(R = (A, B, C)\),函数依赖集:\(F = \{A \to BC,\ B \to C,\ A \to B,\ AB \to C\}\),求正则覆盖。
答案
-
合并 \(A \to BC\) 与 \(A \to B\),此时函数依赖集更新为 \(\{A \to BC,\ B \to C,\ AB \to C\}\)
-
\(AB \to C\) 中的属性 \(A\) 是无关属性,化简后函数依赖集更新为 \(\{A \to BC,\ B \to C\}\)
-
\(A \to BC\) 中的属性 \(C\) 是无关属性,化简后函数依赖集更新为 \(\{A \to B,\ B \to C\}\)
最终结果为:\(\{A \to B,\ B \to C\}\)
- 正则覆盖不一定唯一,不同化简路径可能得到不同但等价的结果。
示例
\(F: \{A \to B,\ B \to AC,\ C \to AB\}\) 的正则覆盖:
- \(F_C: \{A \to B,\ B \to C,\ C \to A\}\)
- \(F_C: \{A \to B,\ B \to AC,\ C \to B\}\)
4 Testing and Decomposition Algorithms¶
4. 1 Test Dependency Preservation¶
若要检验函数依赖 \(\alpha \to \beta\) 在关系模式 \(R\) 的分解(\(R_1, R_2, ..., R_n\))中是否具有依赖保持性,可使用一个多关系闭包过程:
- 初始化:\(result := α\)
- 对每个子关系 \(R_i\),计算 \(t = (\text{result} \cap R_i)^+ \cap R_i\),令 \(result = result ∪ t\),重复直到不再变化
- 若最终
result包含 \(β\),则函数依赖 \(\alpha \to \beta\) 具有依赖保持性
对原函数依赖集 \(F\) 中的所有依赖依次执行上述检验,若全部满足则说明该分解具有依赖保持性。
这个方法是多项式时间,比直接算完整闭包更实用。
示例
已知关系模式 \(R = (A, B, C)\) 和函数依赖集 \(F = \{A \to B,\ B \to C\}\),则该关系模式可通过两种不同方式分解:
- \(R_1 = (A, B)\),\(R_2 = (B, C)\):无损连接分解且满足依赖保持性
- \(R_1 = (A, B)\),\(R_2 = (B, C)\):无损连接分解但不满足依赖保持性
4. 2 Testing for BCNF¶
判断某个非平凡 FD \(α → β\) 是否违反 BCNF,只需计算 \(α^+\),看 \(α^+\) 是否覆盖关系的全部属性,若不能覆盖全部属性,则 \(α^+\) 不是超键,该 FD 违反 BCNF。
若对于 \(F\) 中所有函数依赖 \(\alpha \to \beta\),\(\alpha\) 均为 \(R\) 的超键,则称关系模式 \(R\) 满足 BCNF。
检查子关系时不能只盯着原始 \(F\)
原关系分解后,某个子关系中可能会出现原始 \(F\) 里没直接写出来、但属于 \(F^+\) 的新依赖。
例如 \(R=(A,B,C,D,E), F=\{A→B, BC→D\}\) 分出 \(R_2=(A,C,D,E)\) 后,\(AC→D\) 属于 \(F^+\),可能继续导致 \(R_2\) 违反 BCNF。
检验分解后的关系是否满足BCNF范式
- 方法 1:基于函数依赖集 \(F\) 在 \(R_i\) 上的限制进行检验:即考虑 \(F\) 的闭包 \(F^+\) 中所有仅包含 \(R_i\) 属性的函数依赖,判断 \(R_i\) 在这些依赖下是否满足BCNF。
- 方法 2:直接基于原关系 \(R\) 上的函数依赖集 \(F\) 进行检验,方法如下:
- 对于 \(R_i\) 的任意属性子集 \(\alpha\)(实际检验中无需遍历所有子集),计算 \(\alpha\) 的属性闭包 \(\alpha^+\),并验证:\(\alpha^+\) 要么不包含 \(R_i - \alpha\) 中的任何属性,要么包含 \(R_i\) 的全部属性。
- 若 \(R_i\) 中存在某个属性子集 \(\alpha\) 违反了上述条件,则函数依赖 \(\alpha \to (\alpha^+ - \alpha) \cap R_i\) 在 \(R_i\) 上成立,且 \(R_i\) 不满足 BCNF 范式。
4. 3 BCNF Decomposition Algorithm¶
标准分解算法
result := {R};
done := false;
compute F⁺;
while (not done) do
if (there is a schema Rᵢ in result that is not in BCNF)
then begin
let α → β be a nontrivial functional dependency that holds on Rᵢ
such that α → Rᵢ is not in F⁺, and α ∩ β = ∅;
result := (result – Rᵢ) ∪ (Rᵢ – β) ∪ (α, β);
end
else done := true;
实用分解算法
result := {R};
compute F_c;
while (there is change with result) do
For each R_i in result
For each α → β in F_c
if α ⊂ R_i
For each γ, where α ⊆ γ and γ ⊂ R_i
compute γ⁺ with F_c
if γ ⊂ (γ⁺ ∩ R_i) and (γ⁺ ∩ R_i) ≠ R_i // γ is not a superkey for R_i
result := (result – R_i) ∪ (R_i – ((γ⁺ ∩ R_i) - γ)) ∪ (γ⁺ ∩ R_i)
该算法保证每个结果关系都在 BCNF 中,且分解是 lossless-join,但不保证 dependency preserving。
\(R = (A, B, C, D, E)\), \(F = { A → B, BC → D }\)
- Solution1:
- \(R_1=(A,B)\), \(R_2=(A,C,D,E)\)
- \(AC⁺ = (A,B,C,D)\), \(AC⁺ ∩ R_2 = (A,C,D)\)
- So split \(R_2\) into \((A,C,D), (A,C,E)\)
- Solution2:
- \(R_1=(B,C,D)\), \(R_2=(A,B,C,E)\)
- \(AC⁺ = (A,B,C,D)\), \(AC⁺ ∩ R_2 = (A,B,C)\)
- So split \(R_2\) into \((A,B,C), (A,C,E)\)
\(R = (A, B, C, D)\), \(F = { A → B, B → C }\)
- Decomposition1:
- \(R_1 = (B, C)\), \(R_2 = (A,B,D)\)
- \(R_1 = (B, C)\), \(R_2 = (A,B)\), \(R_3 = (A,D)\) //dependency preserving
- Decomposition2:
- \(R_1 = (A, B)\), \(R_2 = (A,C,D)\) //need to decompose R2
- \(R_1 = (A, B)\), \(R_2 = (A,C)\), \(R_3 = (A,D)\) //not dependency preserving
示例
已知对于 class(course_id, title, dept_name, credits, sec_id, semester, year, building, room_number, capacity, time_slot_id) 有以下函数依赖:
- course_id → title, dept_name, credits
- building, room_number → capacity
- course_id, sec_id, semester, year → building, room_number, time_slot_id
则候选键为 {course_id, sec_id, semester, year}
对于函数依赖 course_id → title, dept_name, credits,course_id 不是 class 关系的超键,违反 BCNF,故将 class 关系分解为两个新关系:
- 课程信息表:
course(course_id, title, dept_name, credits) - 课程安排表:
class-1(course_id, sec_id, semester, year, building, room_number, capacity, time_slot_id)
其中 course 关系满足 BCNF 范式,class-1 关系中存在函数依赖 building, room_number → capacity,但 {building, room_number} 并非 class-1 的超键,因此将 class-1 分解为两个新关系:
classroom(building, room_number, capacity)section(course_id, sec_id, semester, year, building, room_number, time_slot_id)
分解后的 classroom 和 section 均满足 BCNF 范式。
4. 4 3NF Decomposition Algorithm¶
3NF 分解以正则覆盖 \(F_c\) 为基础:
- 对 \(F_c\) 中每个 FD \(α → β\),创建一个关系模式 \(α ∪ β\)
- 若这些关系中没有任何一个包含原关系的候选键,则再补一个候选键关系
- 删除那些完全包含于其他关系中的冗余关系
该算法保证结果每个子关系都在 3NF,lossless-join,且 dependency preserving。
示例
设:
cust_banker_branch(customer_id, employee_id, branch_name, type)
FD 为:
customer_id, employee_id → branch_name, typeemployee_id → branch_namecustomer_id, branch_name → employee_id
先求正则覆盖,可化为:
customer_id, employee_id → typeemployee_id → branch_namecustomer_id, branch_name → employee_id
最终得到 3NF 分解:
(customer_id, employee_id, type)(customer_id, branch_name, employee_id)
5 Multivalued Dependencies¶
- 多值依赖(Multivalued Dependencies, MVD):记作 \(\alpha \twoheadrightarrow \beta\),表示在给定 \(α\) 后,\(β\) 的取值集合与剩余属性的取值集合是相互独立组合的。
表格化直观解释

- \(t_1[\alpha] = t_2[\alpha] = t_3[\alpha] = t_4[\alpha]\)
- \(t_3[\beta] = t_1[\beta]\)
- \(t_3[R - \beta] = t_2[R - \beta]\)
- \(t_4[\beta] = t_2[\beta]\)
- \(t_4[R - \beta] = t_1[R - \beta]\)
示例
设关系模式 \(R\) 的属性集合被划分为 \(3\) 个非空子集:\(Y, Z, W\),则称 \(Y\) 多值决定 \(Z\)(记作 \(Y \twoheadrightarrow Z\)),当且仅当对于关系模式 \(R\) 上的所有可能的关系实例 \(r(R)\):
- 若存在元组 \(< y_1, z_1, w_1 > \in r\) 和 \(< y_1, z_2, w_2 > \in r\),则必有元组 \(< y_1, z_1, w_2 > \in r\) 和 \(< y_1, z_2, w_1 > \in r\)
由于 \(Z\) 和 \(W\) 在定义中的地位是对称的,因此若 \(Y \twoheadrightarrow W\),则必然有 \(Y \twoheadrightarrow Z\)。
示例
对 inst_info(ID, child_name, phone_number) 成立的依赖是 \(ID \twoheadrightarrow child\_name\) 和 \(ID \twoheadrightarrow phone\_number\),其含义是:给定同一个 ID,孩子集合和电话号码集合相互独立。
- FD 是 MVD 的特例,若 \(α → β\) 成立,则必有 \(α \twoheadrightarrow β\)
多值依赖的用途
- 检验关系实例的合法性:判断一个关系实例是否满足给定的一组函数依赖与多值依赖约束。
- 定义合法关系的约束条件:为所有“合法的关系实例”设定规则,后续我们将只讨论满足指定函数依赖与多值依赖集合的关系。
如果一个关系实例 \(r\) 不满足某条给定的多值依赖,我们可以通过向 \(r\) 中添加元组,构造出一个满足该多值依赖的新关系实例 \(r'\)。