Chapter 8 CPU Scheduling¶
1 基本概念¶
1. 1 CPU 调度¶
- CPU 调度是操作系统决定就绪进程/线程何时运行、运行多久的决策过程,在多道程序环境中不可或缺,直接影响系统性能与生产力,其目标是最大化 CPU 利用率,避免 CPU 空闲
CPU 调度发生的时机?
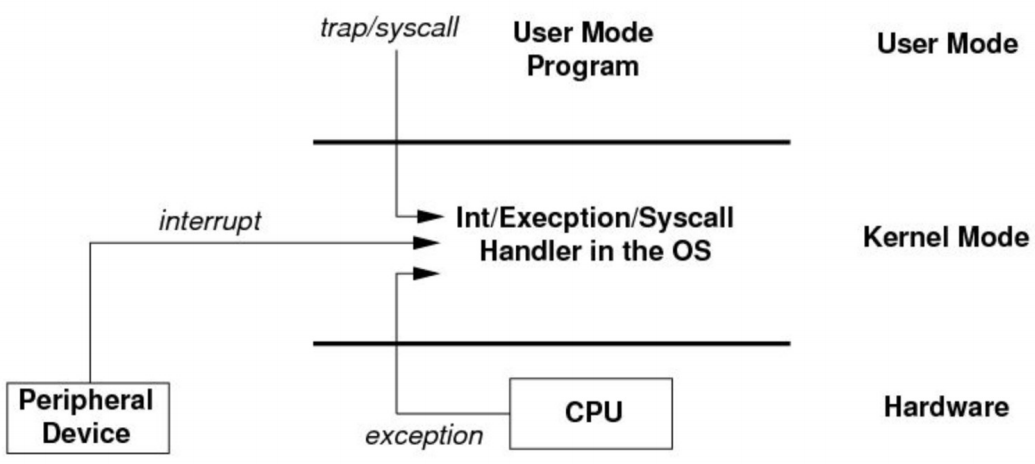
- 调度操作发生在 CPU 处于内核态的时候,触发原因是硬件中断或软件中断(如系统调用)
- 策略(Policy):指进程调度的具体方案,规定了进程的调度规则与优先级判定逻辑
- 机制(Mechanism):即调度器,是操作系统实现进程调度的核心组件,负责在多个进程之间进行切换。
- 调度器依赖上下文切换机制完成进程的切换操作
- 对于分时系统,调度器的核心要求是调度延迟低、运行速度快
1. 2 CPU 突发和 I/O 突发¶
-
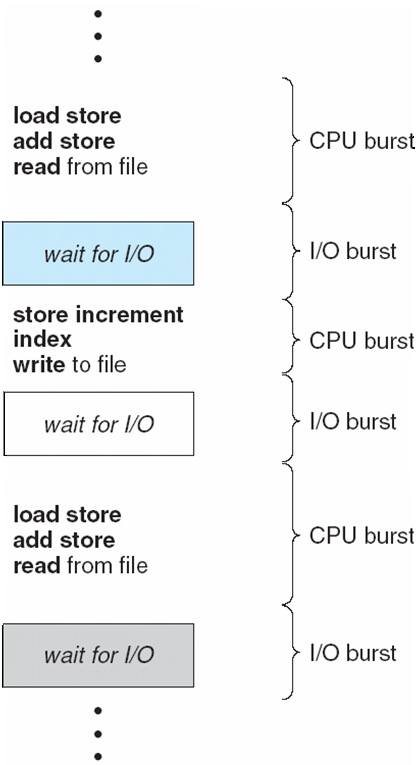
进程会交替进行 CPU 突发(执行指令)和 I/O 突发(等待设备),以 CPU 突发开始和结束,据此可将进程分为以下两类:
- I/O密集型进程(I/O-bound process):频繁等待 I/O,CPU 突发短,如
/bin/cp(复制命令) - CPU密集型进程(CPU-bound process):主要占用 CPU,I/O 突发极短或无,如图像增强操作
- 进程类型的多样性增加了 CPU 调度的复杂度
CPU 突发时长的直方图
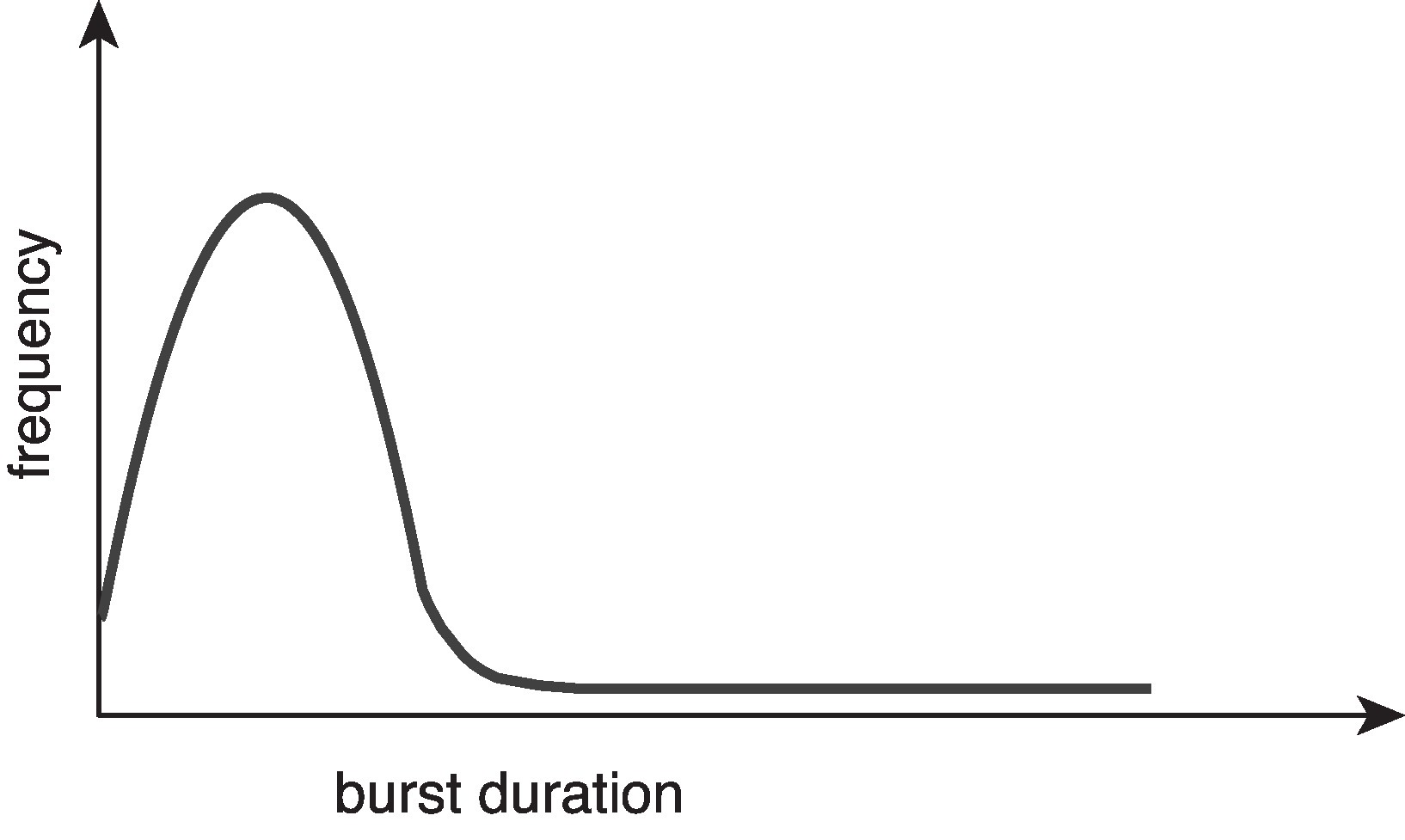
- 大部分 CPU 突发是短时长的(对应图中左侧峰值区域,频率很高)
- 只有少量 CPU 突发是较长时长的(对应图中右侧拖尾区域,频率很低)
- I/O密集型进程(I/O-bound process):频繁等待 I/O,CPU 突发短,如
1. 3 抢占式与非抢占式调度¶
- 抢占(Preemption)指的是强制暂停一个正在运行的进程的操作
| 非抢占式调度(Non-preemptive Scheduling) /协作式调度(Cooperative Scheduling) |
抢占式调度(Preemptive scheduling) | |
|---|---|---|
| 特点 | 进程会一直占用 CPU,直到它主动释放(终止或等待 I/O) | 可强制暂停运行中进程(如时间片到期) |
抢占式调度的优势和复杂性
- 优势:无需依赖进程主动释放 CPU,OS 保持对系统的控制权
- 复杂性:会带来许多进程同步相关问题
- 需考虑共享数据的访问(冲突)
- 需考虑内核态下的抢占操作
- 需考虑关键操作系统活动期间发生的中断
| 用户抢占(User preemption) | 内核抢占(Kernel preemption) | |
|---|---|---|
| 特点 | 从内核态返回用户态时触发(如系统调用、中断处理后) | 内核态执行中触发(如中断处理退出、显式调用 schedule()、内核任务阻塞等) |
- 用户抢占和内核抢占都发生在内核态中,区分依据是 CPU 接下来要返回的目标位置
| 序号 | 触发场景 | 对应调度类型 |
|---|---|---|
| # 1 | 运行状态 \(→\) 等待状态(如等待 I/O) | 非抢占式/抢占式均触发 |
| # 2 | 运行状态 \(→\) 就绪状态(如发生中断时) | 仅抢占式触发 |
| # 3 | 等待状态 \(→\) 就绪状态(如 I/O 完成时) | 仅抢占式触发 |
| # 4 | 运行状态 \(→\) 终止状态 | 非抢占式/抢占式均触发 |
| # 5 | 新建\(→\)就绪 | 仅抢占式触发 |
调度时机分析
-
# 1 和 # 4 都是进程主动释放 CPU,这是非抢占式调度的唯一调度时机
-
# 2 是系统强行打断当前进程,# 3 是系统把 CPU 优先分配给新就绪的高优先级进程,这两种都是系统主动干预,对应抢占式调度,且需要计时器等硬件支持
-
如果进程在操作共享资源时突然被系统抢占,可能导致数据错乱,因此需要同步原语(Synchronization primitives)保护共享资源
1. 4 进程队列管理¶
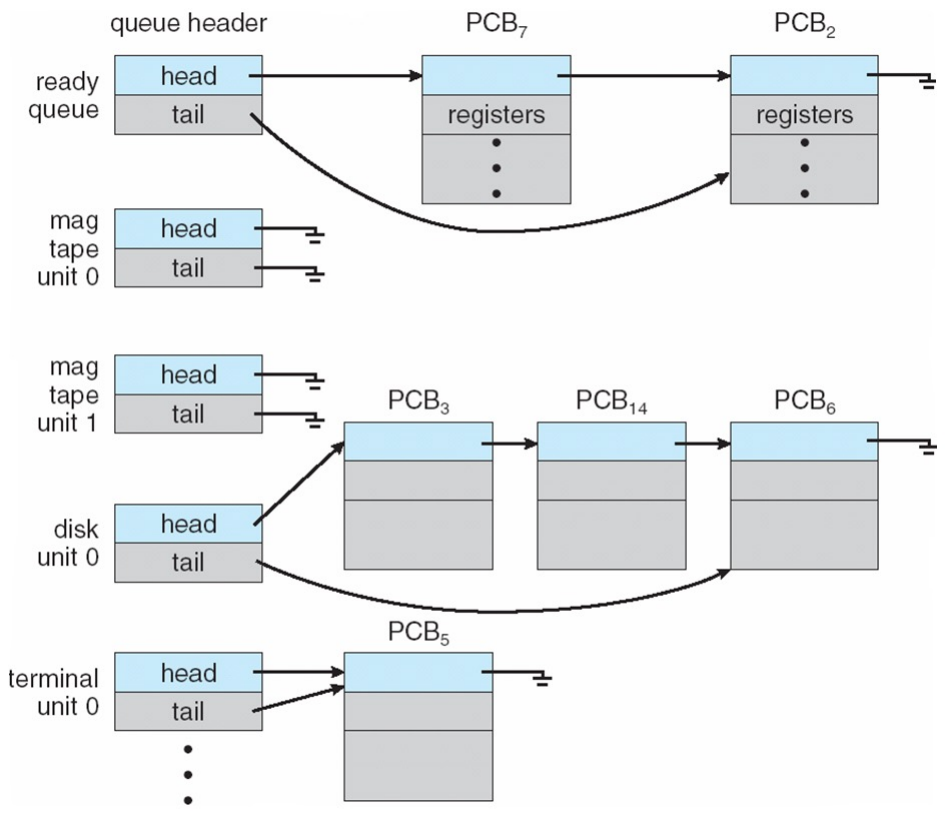
- 内核通过队列管理进程,基于 PCB 链表实现
- 就绪队列(Ready Queue):存储所有就绪状态的进程,Linux 中通过
list_head结构体实现 - 设备队列(Device Queues):按设备分类,存储等待该设备的进程(如磁盘队列、终端队列)
- 就绪队列(Ready Queue):存储所有就绪状态的进程,Linux 中通过
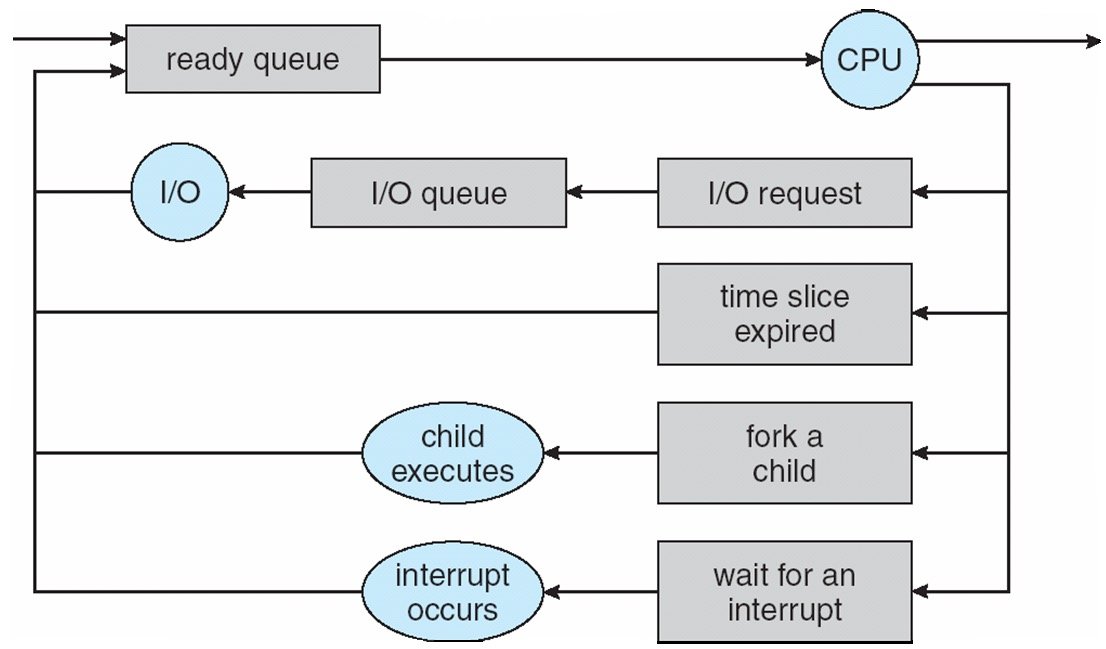
- 调度模块将 CPU 的控制权交给调度程序选中的进程,具体包括:切换上下文、切换到用户模式并跳转到用户程序中的对应位置以重启该程序
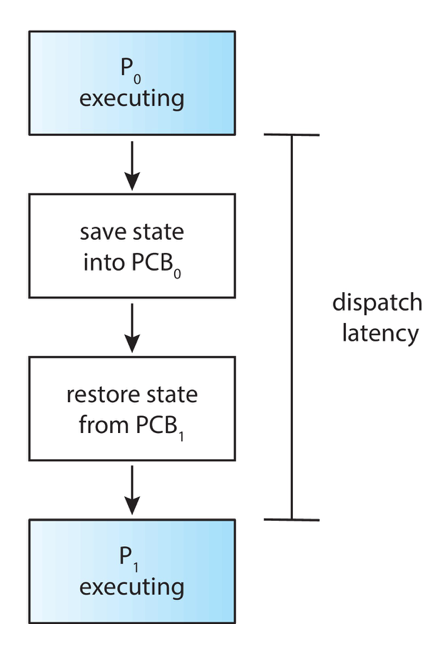
- 调度延迟(Dispatch latency):调度模块停止一个进程并启动另一个进程所需的时间
2 调度算法¶
调度的目标
- 最大化 CPU 利用率:尽可能让 CPU 保持忙碌状态
- 最大化吞吐量(Throughput):单位时间内完成执行的进程数量
- 最小化周转时间(Turnaround time):从进程被提交到进程执行完成所花费的时间
- 最小化等待时间(Waiting time):进程在就绪队列中等待的时间长度
- 最小化响应时间(Response time):从进程被提交到第一次被执行的时间(适用于分时环境)
2. 1 先来先服务调度(FCFS, First-Come, First-Served Scheduling)¶
- 原理:按进程到达顺序分配 CPU,非抢占式,实现最简单
- 护航效应(Convoy Effect):短进程跟随长进程会导致整体延迟
示例
| 进程 | 突发时间 |
|---|---|
| \(P_1\) | 24 |
| \(P_2\) | 3 |
| \(P_3\) | 3 |
假设进程的到达顺序为 \(P_1\)、\(P_2\)、\(P_3\),则该调度对应的甘特图如下:

平均等待时间 \(t_{\text{average_waiting}} = \frac{0+24+27}{3} = 17\)
假设进程同时到达,顺序为 \(P_2\)、\(P_3\)、\(P_1\),则该调度的对应甘特图如下:

平均等待时间 \(t_{\text{average_waiting}} = \frac{6+0+3}{3} = 3\)
2. 2 短作业优先调度(SJF, Shortest-Job-First Scheduling)¶
- 原理:优先选择下次CPU突发时间最短的进程,分为非抢占式和抢占式
非抢占式调度示例
| 进程 | 到达时间 | 突发时间 |
|---|---|---|
| \(P_1\) | 0 | 10 |
| \(P_2\) | 2 | 6 |
| \(P_3\) | 4 | 7 |
| \(P_4\) | 5 | 2 |
该调度的对应甘特图如下:

平均等待时间 \(t_{\text{average_waiting}} = \frac{0+10+14+5}{4} = 7.25\)
抢占式调度示例
- 最短剩余时间优先(SRTF, shortest-remaining-time-first)
| 进程 | 到达时间 | 突发时间 |
|---|---|---|
| \(P_1\) | 0 | 10 |
| \(P_2\) | 2 | 6 |
| \(P_3\) | 4 | 7 |
| \(P_4\) | 5 | 2 |
该调度的对应甘特图如下:

平均等待时间 \(t_{\text{average_waiting}} = \frac{15 + 2 + 6 + 0}{4} = 5.75\)
- 短作业优先(SJF)在平均等待时间指标上被证明是最优的,也被称为最短剩余处理时间(SRPT, Shortest Remaining Processing Time),其最优性不受抢占与否影响
- 核心问题在于无法预知下次 CPU 突发时间,实际中需通过历史数据预测
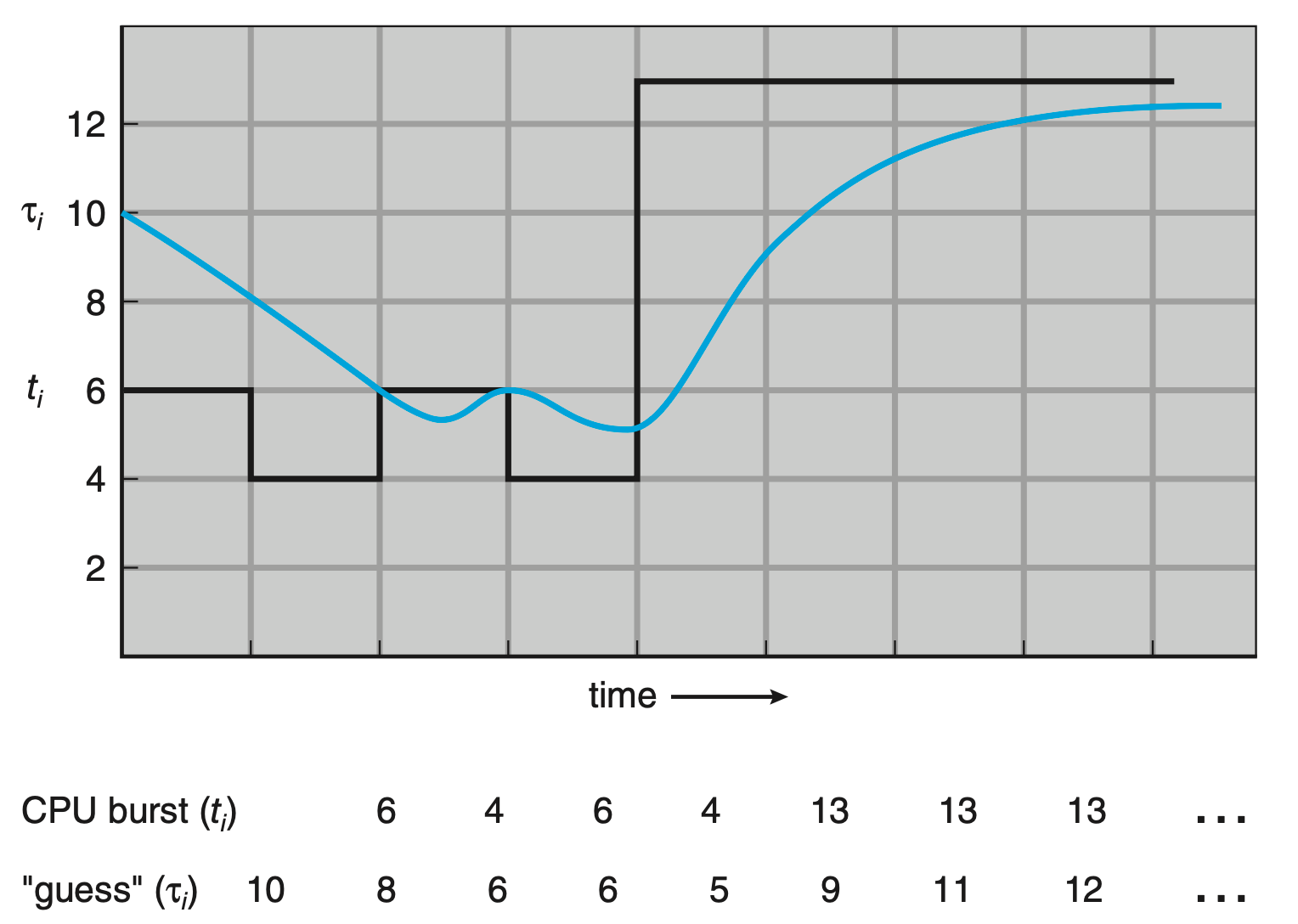
指数平均法预测 CPU 突发时长
- 根据过去的数据预测未来,给近期的历史数据赋予比远期历史数据更高的权重
参数 \(\alpha\) 的取值在 \(0\) 到 \(1\) 之间,\(0\) 表示不关注最近的历史数据,\(1\) 表示只关注最近的历史数据,\(0.5\) 表示一种这种方案,实际用例如下:
2. 3 时间片轮转调度(RR, Round-Robin Scheduling)¶
- RR 调度是抢占式的,专为分时系统设计
- 定义时间片,进程运行不超过时间片(突发时间短于时间片则提前释放)
- 就绪队列采用先进先出(FIFO)机制,进程就绪后进入队尾
示例
| 进程 | 突发时长 |
|---|---|
| \(P_1\) | 24 |
| \(P_2\) | 3 |
| \(P_3\) | 3 |
采用时间片 \(=4\),则对应的甘特图如下:
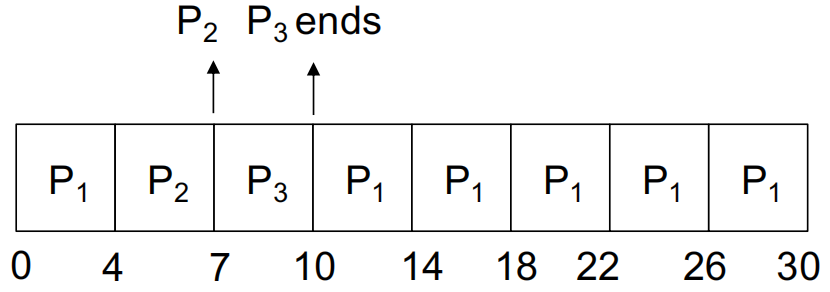
平均等待时间 \(t_{\text{average_waiting}} = \frac{6 + 4 + 7}{3} = 5.67\)
- 通常平均等待时间比短作业优先(SJF)差,但响应时间更好(不会出现饥饿现象)
| 响应性/交互性 | 上下文切换开销 | 备注 | |
|---|---|---|---|
| 短时间片 | 优秀 | 极高 | 若调度器足够快,开销有望不会过高 |
| 长时间片 | 较差 | 极低 | 当时间片极长时,轮询(RR)调度会退化为先来先服务(FCFS)调度 |
- 实际场景中,CPU 花在切换上的时间占比非常低,常用时间片范围为 \(10 - 100 \, \text{ms}\),上下文切换时间约 \(10 \, \text{μs}\)
2. 4 优先级调度(Priority Scheduling)¶
- 原理:为进程分配优先级(数值范围如 \(0-9\),无统一约定,低数值可能表示高/低优先级),优先调度高优先级进程
- 优先级分类:
- 内部优先级:基于进程属性(如 SJF 中预测突发时间、打开文件数)
- 外部优先级:用户指定(如任务重要性)
- 短作业优先(SJF)是优先级调度的特例,其优先级是下一次 CPU 突发时长预测值的倒数(即突发时长越短,优先级越高)
优先级调度示例
| 进程 | 突发时长 | 优先级 |
|---|---|---|
| \(P_1\) | 10 | 3 |
| \(P_2\) | 1 | 1 |
| \(P_3\) | 2 | 4 |
| \(P_4\) | 1 | 5 |
| \(P_5\) | 5 | 2 |
对应的甘特图如下:

平均等待时间 \(t_{\text{average_waiting}} = \frac{6 + 0 + 16 + 18 + 1}{5} = 8.2\)
结合轮询的优先级调度示例
- 调度规则:运行优先级最高的进程,优先级相同的进程采用轮询调度
| 进程 | 突发时长 | 优先级 |
|---|---|---|
| \(P_1\) | 4 | 3 |
| \(P_2\) | 5 | 2 |
| \(P_3\) | 8 | 2 |
| \(P_4\) | 7 | 1 |
| \(P_5\) | 3 | 3 |
采用时间片 \(=2\),则对应的甘特图如下:

- 和短作业优先(SJF)一样,优先级调度可以是抢占式或非抢占式的
- 饥饿问题(starvation):低优先级进程可能永远被高优先级进程抢占
- 解决方案:优先级老化(随进程等待时间增加优先级)
2. 5 多级队列调度(Multilevel Queue Scheduling)¶
- 原理:按进程类别(如优先级、类型)划分多个就绪队列,每个队列采用独立调度策略
- 队列内调度(Scheduling within queues):每个队列有自己的调度策略,如如高优先级队列用 RR,低优先级队列用 FCFS
- 队列间调度(Scheduling between the queues):通常采用抢占式优先级调度(高优先级队列非空时低优先级队列无法运行),或采用队列间的时间分片(如 \(80\%\) 的时间分配给队列 \(1\),\(20\%\) 的时间分配给队列 \(2\))
2. 6 多级反馈队列调度(Multilevel Feedback Queue Scheduling)¶
- 进程可在队列间迁移,动态调整优先级
示例
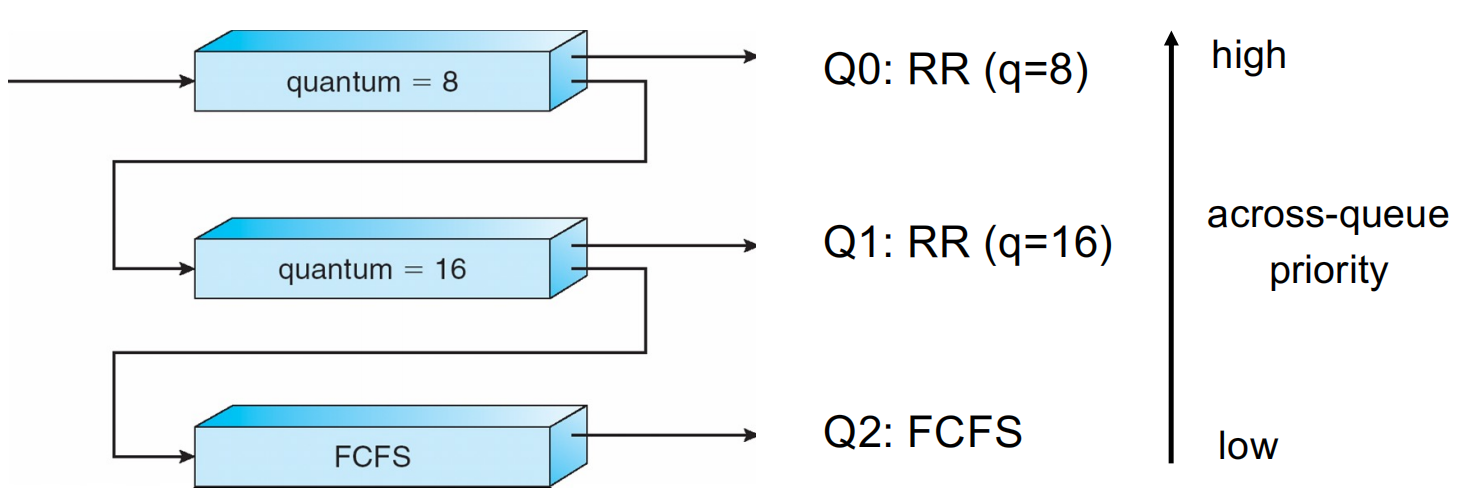
- 新进程入最高优先级队列
- 未用完时间片的进程大概率是 I/O 密集型,留在原队列,确保它在少数需要 CPU 的场合下可以顺利获得 CPU 资源
- 用完时间片的进程大概率是 CPU 密集型,降级至低优先级队列,只有在非 CPU 密集型进程不需要 CPU 时才能获得运行机会
- 饥饿防护:低优先级队列中长时间等待的进程逐步升级优先级
- 该算法是目前最通用的 CPU 调度算法,同时具备极强的可配置性(队列的数量、每个队列各自采用的调度算法、队列之间的调度规则,以及进程在不同队列间的升级/降级方式)
- 该算法同时也是复杂度最高的调度算法
- 适配某一系统或工作负载的最优配置,往往无法直接套用于其他场景,且参数繁多的可配置系统看似潜力充足,但实际很难达到预期的效果
- 计算开销大,Linux 内核开发者需要借助技巧提升运行效率
What's a Good Scheduling Algorithm?
- 理论分析:
- 可用的分析/理论结论较少
- 核心思路:选取两种调度算法和一个评估指标(如平均等待时间),对比其表现
- 仅极少数场景能证明算法最优(如短作业优先对平均等待时间最优)
- 模拟测试:
- 测试方式:通过自动生成甘特图,覆盖上百万种场景
- 对比结果:统计算法在多数场景的表现
- 实际实现(最终验证方案):
- 将算法 A、B 都部署到内核中(耗时较高)
- 针对同一基准工作负载,分别用两种算法运行 \(10\) 小时
- 对比结果,以实际有效工作为标准
3 调度机制¶
3. 1 线程调度(Thread Scheduling)¶
- 支持线程的系统中,调度对象是线程而非进程
| 进程竞争范围(PCS, process-contention scope) | 系统竞争范围(SCS, system-contention scope) | |
|---|---|---|
| 竞争范围 | 同一进程内的用户级线程 | 系统内的所有线程 |
| 典型实现 | 线程库调度,将用户级线程映射到轻量级进程(LWP),通常由程序员设置优先级 | 内核直接调度线程到可用CPU |
对应的 Pthread 宏 |
PTHREAD_SCOPE_PROCESS |
PTHREAD_SCOPE_SYSTEM (Linux、macOS 仅支持此模式) |
3. 2 多处理器调度(Multiple-Processor Scheduling)¶
- 架构类型:多核 CPU、多线程核心、非统一内存访问(NUMA)系统、异构多处理(HMP, Heterogeneous multiprocessing)
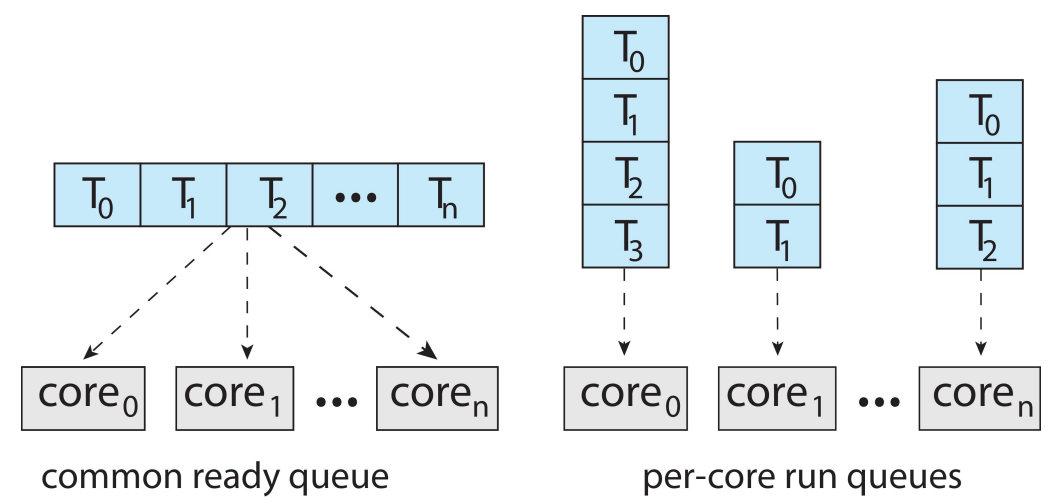
- 对称多处理(SMP, Symmetric multiprocessing)是指每个处理器自主进行调度
- 所有线程可处于一个公共就绪队列(common ready queue)中
- 每个处理器可拥有自己的私有线程(private queue)队列
- 多核处理器(Multicore Processors):利用内存停顿的时间,在内存读取的过程中推进另一个线程的执行,运行速度更快且功耗更低
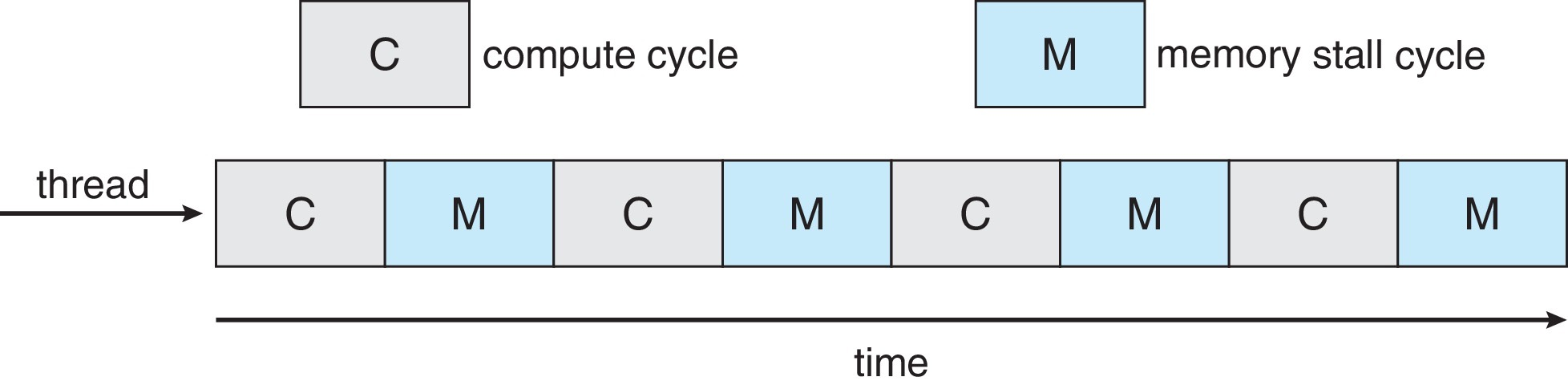
- 多线程多核系统(Multithreaded Multicore System):每个核心拥有不止 \(1\) 个硬件线程,若某个线程出现内存停顿,就切换到另一个线程
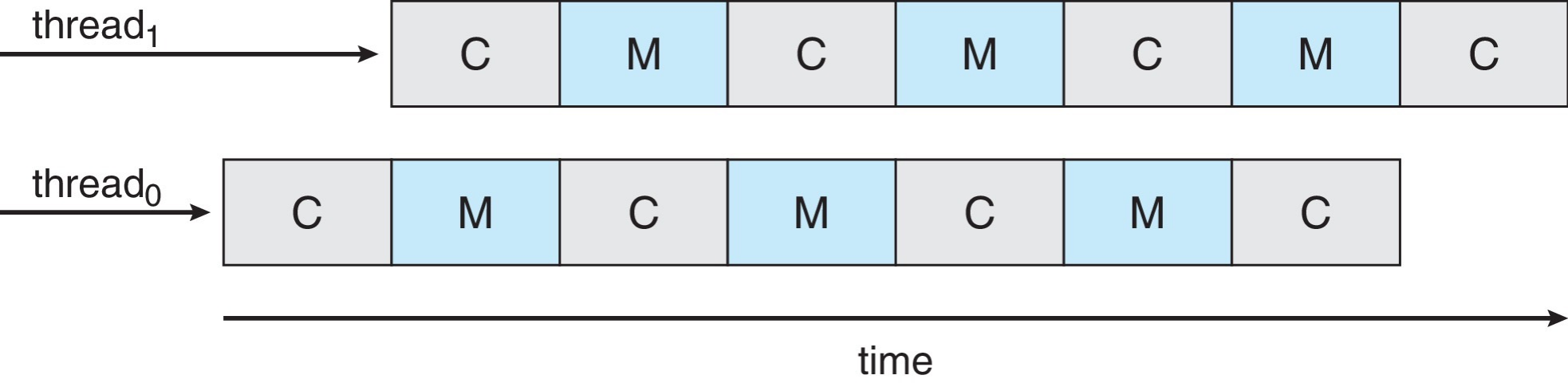
- 芯片多线程(CMT, Chip-multithreading):为每个核心分配多个硬件线程,英特尔称为超线程(hyperthreading)
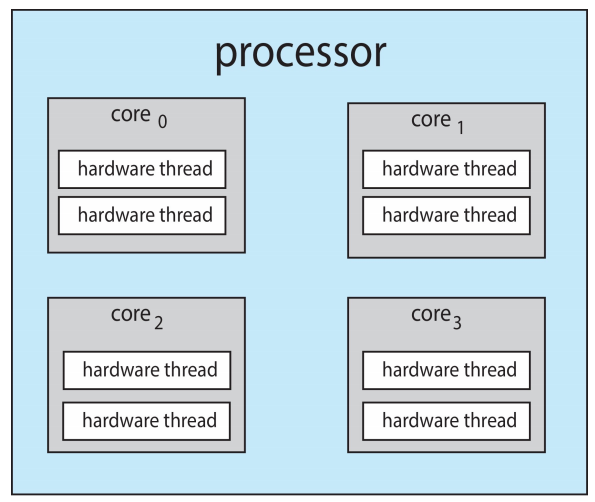
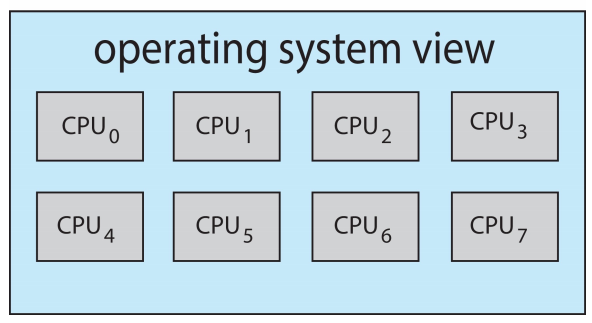
- 在每个核心包含 \(2\) 个硬件线程的四核系统(quad-core system)中,操作系统会识别出 \(8\) 个逻辑处理器
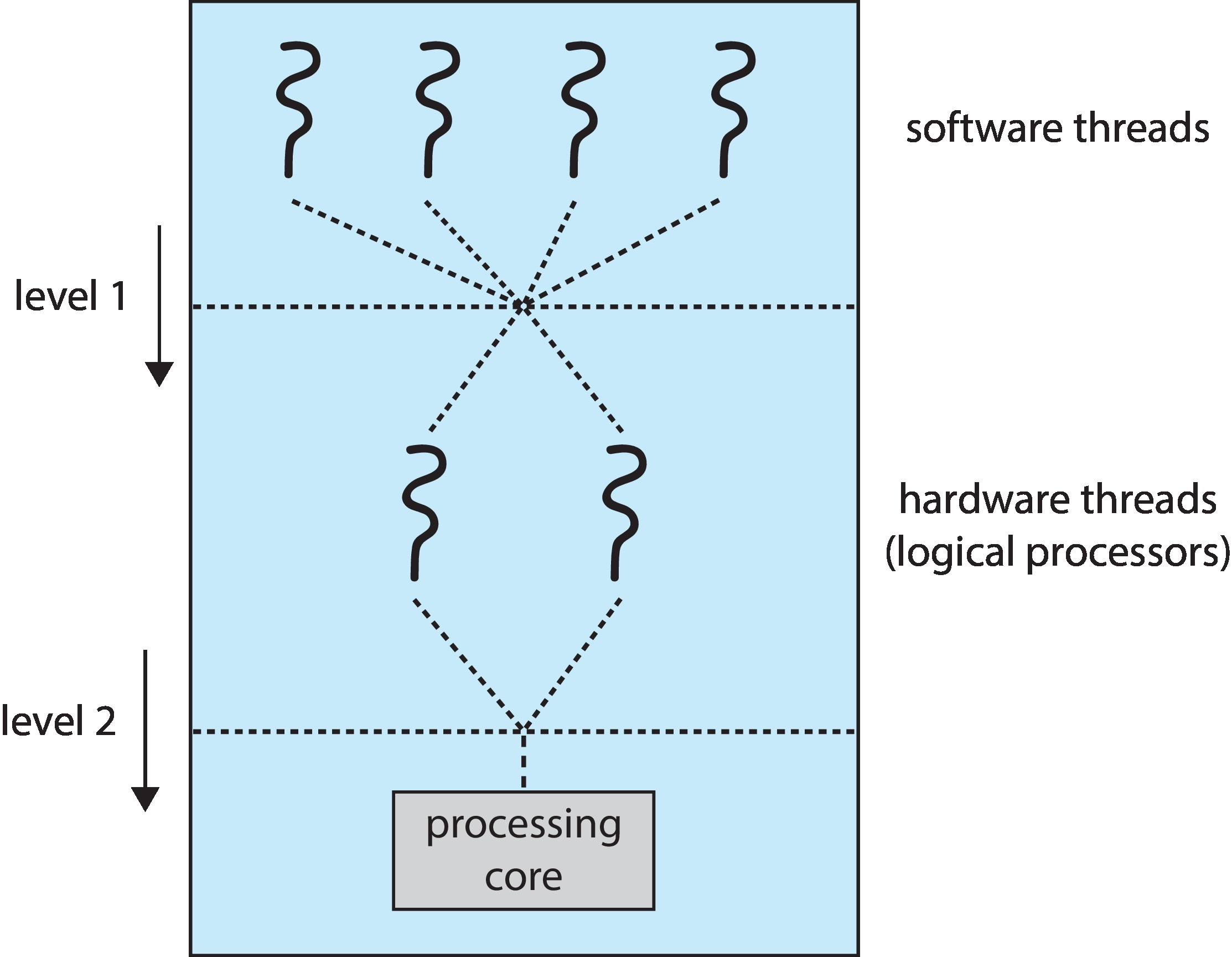
- 两级调度:
- 操作系统决定哪个软件线程在逻辑 CPU 上运行
- 每个核心决定哪个硬件线程在物理核心上运行
- 负载均衡(Load balancing)
- 推迁移(Push migration):定期检查过载 CPU,将任务推送至空闲 CPU
- 拉迁移(Pull migration):空闲 CPU 主动从繁忙 CPU 拉取任务
-
处理器亲和性(Processor Affinity):当线程在某处理器上运行时,该处理器的缓存会存储该线程的内存访问数据,这种线程与处理器之间的关联关系称为处理器亲和性
- 软亲和性(Soft affinity):OS 尽量让线程在同一 CPU 运行,但不提供强制保证
- 硬亲和性(Hard affinity):允许进程指定其可以运行的处理器集合
- 负载均衡可能会影响处理器亲和性:为了平衡负载,线程可能被从一个处理器迁移到另一个,但这样会导致线程丢失原处理器缓存中存储的内容
-
当操作系统具备 NUMA 感知能力时,会将内存分配到线程当前运行的 CPU 所在区域附近,以此优化内存访问效率
- 异构多处理(HMP)的处理器在计算能力、功耗等特性上并非完全一致,可根据任务需求灵活调度
3. 3 实时调度(Real-Time CPU Scheduling)¶
- 软实时系统(Soft real-time systems):关键实时任务优先级最高,但无法保证任务何时被调度
- 硬实时系统(Hard real-time systems):任务必须在截止时间前完成
4 主流 OS 调度实现¶
4. 1 Win XP Scheduling¶
- 采用基于优先级、基于时间片、多队列的抢占式调度
- \(32\) 级优先级机制,\(1-15\) 为可变类,\(16-31\) 为实时类,数值越高优先级越高
- 线程优先级动态调整
- 当线程的时间片耗尽时,非实时类线程优先级会被降低(CPU 密集型线程),保持系统的交互性
- 当线程唤醒时(I/O 密集型线程),其优先级会被提升
- 优先级的提升幅度取决于线程此前等待的对象
- Windows XP 会维护一个虚拟的空闲线程(idle thread),优先级为 \(0\) 或无优先级,在无其他进程运行时执行,避免 CPU 空闲场景
4. 2 Linux Scheduling¶
Linux 调度演进
| 内核版本 | 调度器类型 | 核心特点 |
|---|---|---|
| 0.11(1991) | RR+优先级 | 数组实现,简单快速,TASK_RUNNING 状态即为就绪 |
| 1.2(1995) | RR+优先级 | 循环队列实现,优化遍历效率 |
| 2.2(1999) | 调度类划分 | 支持实时、非抢占、非实时类,引入 goodness 函数计算进程优先级 |
| 2.4(2001) | 时间片 epoch 机制 | 按 epoch 分配时间片,I/O 密集型进程获得更大时间片,\(O(n)\) 复杂度(遍历所有就绪进程) |
| 2.6(2003) | \(O(1)\) 调度器 | 双数组(活跃/过期)+ 位图索引,无需遍历,调度决策 \(O(1)\) 时间 |
| ≥2.6.23(2007) | CFS(完全公平调度器) | 基于红黑树,跟踪进程虚拟运行时间,优先调度虚拟时间最短的进程(\(O(log n)\) 复杂度) |
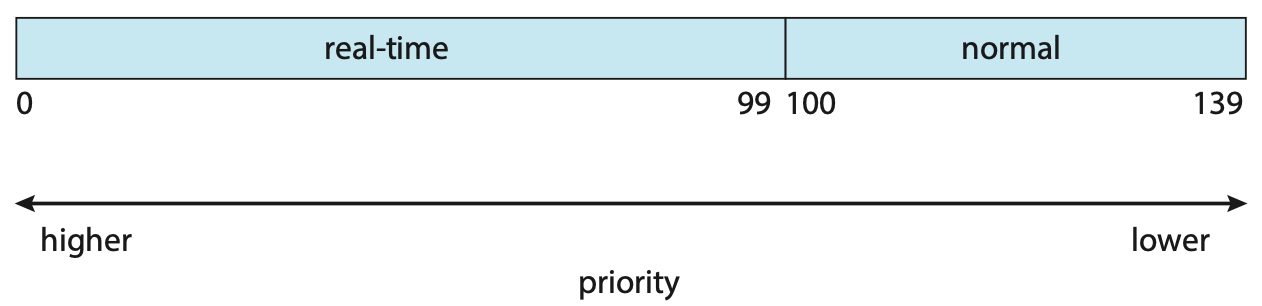
| 进程类型 | 优先级范围 | 计算方式 |
|---|---|---|
| 实时进程 | \(0-99\) | MAX_RT_PRIO - 1 - rt_prio = 100 - 1 - 实时优先级 |
| 普通进程 | \(100-139\) | static_prio = nice + DEFAULT_PRIO = nice + 120 |
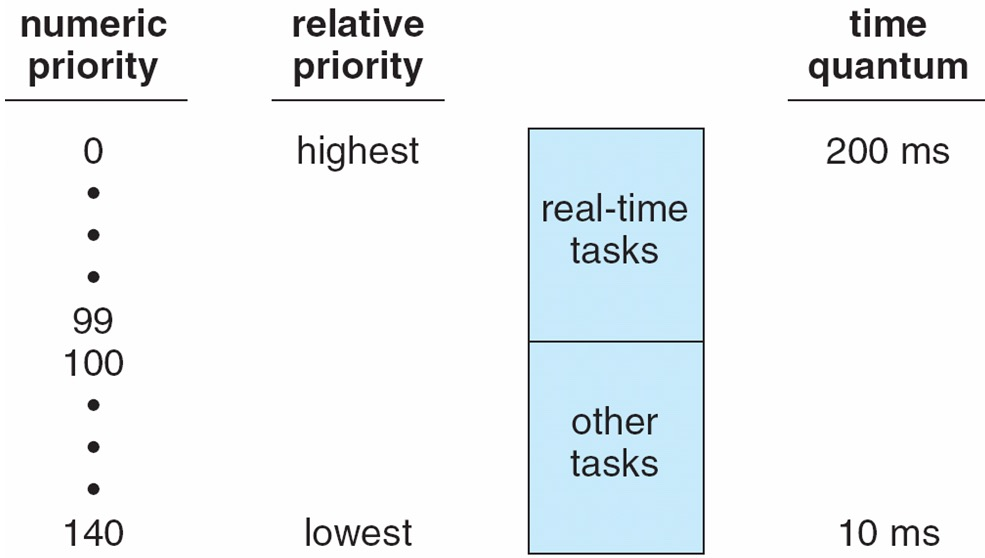
- 数值越小,优先级越高