9 Synchronization¶
What really happened on Mars?
着陆后数日,探测器开始收集气象数据时,频繁发生全系统重置(System Reset),每次重置都会导致该周期收集的数据丢失。
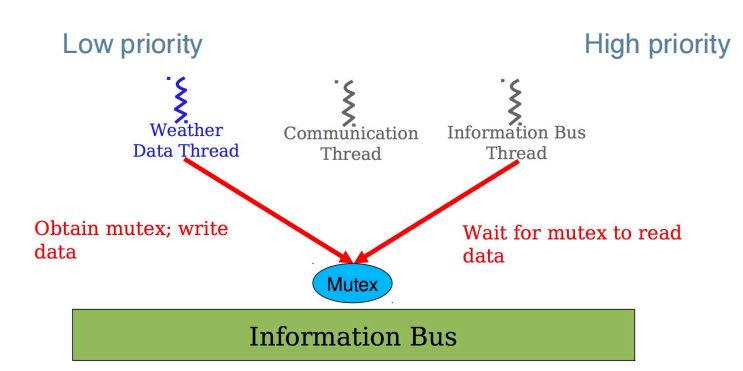
VxWorks RTOS 支持多任务,任务按优先级高低调度,上述现象的根本原因是优先级反转(Priority Inversion),其过程如下:
- 低优先级的气象线程再发布自身数据时获取互斥锁,向信息总线写入数据
- 中断触发,气象线程被调度暂停,但仍持有互斥锁
- 高优先级的信息总线线程尝试获取同一互斥锁,因锁被占用而阻塞
- 中等优先级的通信线程被调度执行,且运行时间较长
- 气象线程无法获得 CPU 资源释放互斥锁,信息总线线程持续阻塞
- 看门狗(Watchdog)检测到系统异常,触发全系统重置
探测器保留了 VxWorks 的 C 语言解释器(调试功能),可实时执行 C 代码,互斥锁的优先级继承参数存储在全局变量中,且地址包含在发射软件的符号表中,可通过 C 解释器访问,于是一段简短的 C 程序被上传到航天器上,将 3 个关键互斥锁的参数从 FALSE 改为 TRUE,此后系统再未出现重置的情况。
1 Synchronization Tools¶
- 进程/线程可并发执行,可能在任意时刻被中断(部分执行完成)
- 并发访问共享数据会导致数据不一致(Data Inconsistency),需通过有序执行保证协作进程的数据一致性。
Example
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int counter = 0;
static int loops = 166;
// pthread_mutex_t pmutex = PTHREAD_MUTEX_INITIALIZER;
void *worker(void *arg) {
int i;
printf("%s: begin\n", (char* )arg);
for (i = 0; i < loops; i++) {
// pthread_mutex_lock(&pmutex);
counter++;
// pthread_mutex_unlock(&pmutex);
}
printf("%s: done\n", (char *)arg);
}
int main(int argc, char *argv[]) {
pthread_t p1, p2;
printf("main: begin (counter = %d)\n", counter);
pthread_create(&p1, NULL, worker, "A");
pthread_create(&p2, NULL, worker, "B");
pthread_join(p1, NULL);
pthread_join(p2, NULL);
printf("main: done with both (counter: %d)\n", counter);
return 0;
}
多次执行上述程序,发现 counter 输出结果不一致,这是共享变量的竞争条件导致的。
1. 1 Race Condition¶
- 多个进程/线程并发访问并操作同一数据,执行结果依赖于访问的先后顺序,导致结果不确定。
示例 1:共享变量 counter 自增
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c

中断导致两次自增仅生效一次,进而导致 counter 为 51 而非 52
示例 2:内核中的竞争条件
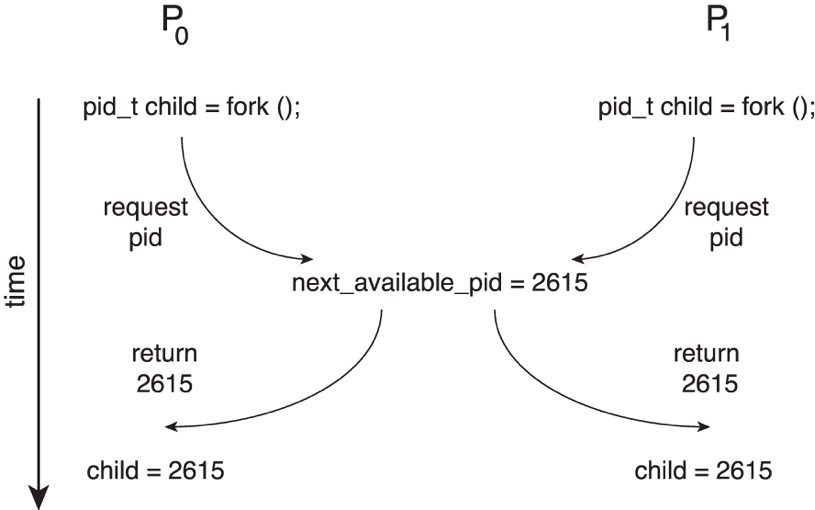
内核变量 next_available_pid 存在竞争条件,两进程同时请求 PID 时,除非实现互斥机制,否则可能分配相同 ID。
1. 2 Critical Section Problem¶
- 临界区(Critical Section):进程/线程中修改共享数据、更新表格、写文件等需原子执行的代码段,同一时刻只能有一个进程处于临界区
- 剩余区(Remainder Section):临界区之外的代码段
- 临界区问题:设计协议让进程可以同步自身活动,从而协作式地共享数据
while (true) {
Entry Section // 请求进入临界区
Critical Section // 原子执行段
Exit Section // 释放进入权限
Remainder Section // 其他逻辑
}
| 要求 | 定义 |
|---|---|
| 互斥(Mutual Exclusion) | 同一时刻仅一个进程能进入临界区 |
| 进展(Progress) | 无进程在临界区时,若有进程请求进入,仅非剩余区的进程参与决策,且决策不无限推迟,无死锁 |
| 有界等待(Bounded Waiting) | 进程请求进入临界区后,在该请求被允许之前,其他进程进入临界区的次数有上限(无饥饿) |
OS 中的临界区处理
- 禁止中断(Preventing interrupts):单核系统中效果良好,但在多处理器系统中不可行
- 非抢占式(Non-preemptive):进程会持续运行,直到退出内核态、发生阻塞或主动让出 CPU,优势是内核态下基本不会出现竞争条件
- 抢占式(Preemptive):允许进程在内核态运行时被抢占,必须精心设计,在对称多处理(SMP)架构下设计难度尤其高
1. 3 Peterson 算法¶
- Peterson 算法仅解决两个进程的同步问题,是典型的软件级方案。
- 假设
LOAD和STORE指令是原子操作(执行不可中断),硬件通常无法自动保证这种原子性,因此需要使用特殊指令来实现 - 两个进程共享两个变量
boolean flag[2]:标记进程是否准备进入临界区int turn:标记当前轮到哪个进程进入临界区

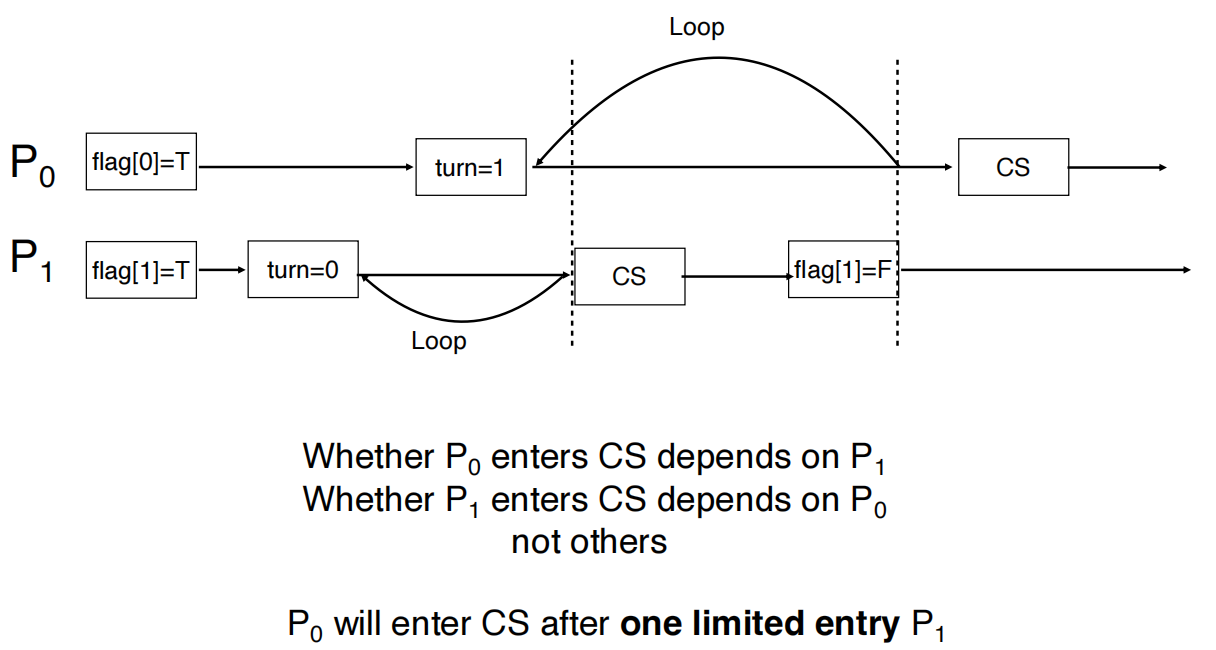
- 互斥性:当 \(P_0\) 进入临界区,则
flag[1]=false或turn=0,接下来证明 \(P_1\) 无法进入临界区- 若
flag[1]=false,则 \(P_1\) 不在临界区 - 若
flag[1]=true且turn=1,则 \(P_0\) 会处于循环等待状态,与 \(P_0\) 已进入临界区矛盾 - 若
flag[1]=true且turn=0,则 \(P_1\) 会处于循环等待状态
- 若
- Peterson 算法仅适用于双进程场景,在现代架构不适用,处理器/编译器为优化性能可能会重排无依赖的指令,这会导致多线程下结果不一致(如破坏互斥性,两个进程同时进入临界区)
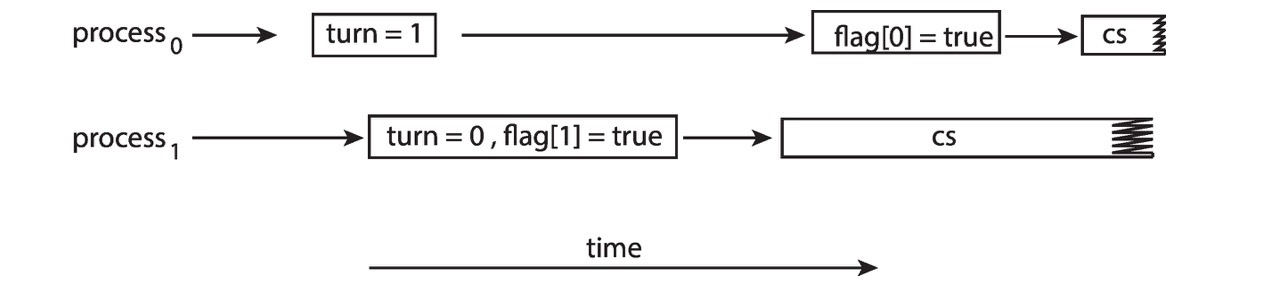
What is the expected output?

答案
预期输出为 100,但线程 2 的操作可能会被重排,此时输出结果可能为 0。
flag = true;
x = 100;
1. 4 硬件支持同步¶
许多系统会为临界区代码提供硬件支持,在单处理器场景下,对应的实现方式是禁用中断,此时当前运行的代码会在无抢占的状态下执行,但这种方式通常在多处理器系统上效率极低,需要禁用所有中断且不具备可扩展性。
1. 4. 1 Memory Barriers/Fences¶
- 强制内存修改可见于所有处理器,防止指令重排,保证内存操作的顺序性和可见性。
- 内存模型分类
- 强有序(Strongly ordered):一个处理器的内存修改立即对所有处理器可见
- 弱有序(Weakly ordered):内存修改可能延迟可见,需内存屏障强制同步
添加内存屏障以确保线程 1 输出 100
while (!flag)
// 确保在看到 flag 的变更前不会读取 x 的值
memory_barrier();
print x;
x = 100;
// 确保在修改 flag 前 x 的新值对其他处理器可见
memory_barrier();
flag = true;
| 内存基本类型 | 说明 |
|---|---|
| Write (or store) memory barriers | 保证相对于系统其他组件,屏障前的所有 STORE 操作先于屏障后的 STORE 操作执行 |
| Address-dependency barriers (historical) | —— |
| Read (or load) memory barriers | 是地址依赖屏障的扩展,保证相对于系统其他组件,屏障前的所有 LOAD 操作先于屏障后的 LOAD 操作执行 |
| General memory barriers | 保证相对于系统其他组件,屏障前的所有 LOAD/STORE 操作先于屏障后的 LOAD/STORE 操作执行 |
| 隐式内存屏障 | 分为获取(ACQUIRE)操作和释放(RELEASE)操作 |
Linux 内核拥有多种作用于不同层级的屏障(编译器屏障和CPU 内存屏障),其中包含七种基础的 CPU 内存屏障,除地址依赖屏障外,所有内存屏障都隐含着一个编译器屏障,而地址依赖不会施加任何额外的编译器排序约束。
| 类型(TYPE) | 强制型(MANDATORY) | SMP 条件型(SMP CONDITIONAL) |
|---|---|---|
| 通用(GENERAL) | mb() |
smp_mb() |
| 写(WRITE) | wmb() |
smp_wmb() |
| 读(READ) | rmb() |
smp_rmb() |
| 地址依赖(ADDRESS DEPENDENCY) | 无 | READ_ONCE() |
| 隐式内存屏障 | 说明 |
|---|---|
| 锁获取函数 (Lock acquisition functions) |
包含自旋锁、读写自旋锁、互斥锁、信号量、读写信号量等锁结构,每种结构均有 ACQUIRE 和 RELEASE 变体 |
| 中断禁用函数 (Interrupt disabling functions) |
用于禁用中断的函数(等价 ACQUIRE)和启用中断的函数(等价 RELEASE),仅作为编译器屏障,若需内存或 I/O 屏障需额外补充 |
| 睡眠与唤醒函数 (Sleep and wake-up functions) |
针对全局数据标记事件的睡眠/唤醒操作,需保证任务状态与全局数据的执行顺序,对应的原语隐含特定屏障 |
| 杂项函数 (Miscellaneous functions) |
如 schedule() 等函数隐含完整内存屏障 |
1. 4. 2 Hardware Instructions¶
硬件指令中的特殊指令可通过原子性(不可中断)的方式完成测试并修改单个字内容、或交换两个字内容的操作。
1. Test-and-Set Instruction¶
- 功能:返回目标变量的原始值,并将其设为
trueboolean test_and_set(boolean *target) { boolean rv = *target; // 读取原始值(原子) *target = true; // 设置为 true(原子) return rv; } - 基础 Test-and-Set 锁不满足有界等待,多线程时低优先级线程可能饥饿
bool lock = true; // 共享变量 do { while (test_and_set(&lock)); // 忙等直到获取锁 /* critical section */ lock = false; // 释放锁 /* remainder section */; } while (true);
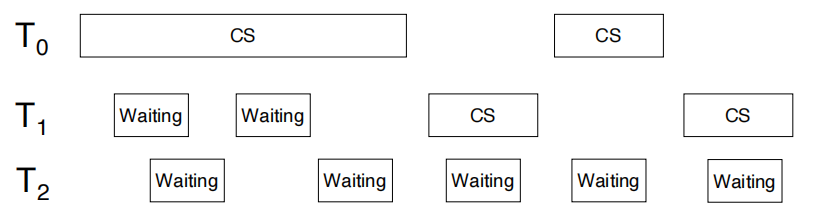
改进:引入 waiting 数组记录等待线程,释放锁时传递给下一个等待线程
do {
waiting[i] = true;
while (waiting[i] && test_and_set(&lock)) ;
waiting[i] = false;
/* critical section */
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i)
lock = false;
else
waiting[j] = false;
/* remainder section */
} while (true);
2. Compare-and-Swap Instruction, CAS¶
- 功能:比较目标变量与期望值,相等则更新为新值,返回原始值
int compare_and_swap(int *value, int expected, int new_value) { int temp = *value; // 读取原始值(原子) if (*value == expected) *value = new_value; // 相等则更新(原子) return temp; } - 基础 CAS 锁不满足有界等待
int lock = 0; // 共享变量(0 = 空闲,1 = 占用) do { while (compare_and_swap(&lock, 0, 1) != 0); // 忙等直到获取锁 /* critical section */ lock = 0; // 释放锁 /* remainder section */ } while (true);
改进:增加锁传递逻辑
while (true) {
waiting[i] = true; // 标记进入等待锁状态
key = 1;
// 循环抢锁
while (waiting[i] && key == 1)
key = compare_and_swap(&lock, 0, 1);
waiting[i] = false; // 取消等待标记
/* critical section */
// 找到下一个等待锁的线程,进行锁传递
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i)
// 若没有其他线程在等锁,直接释放锁
lock = 0;
else
// 若有等待的线程,取消等待标记,使其可以抢锁
waiting[j] = false;
/* remainder section */
}
Practice in x86 and ARM

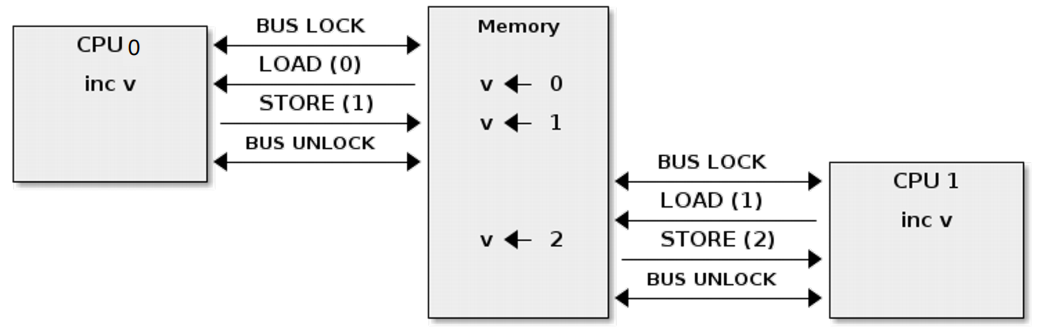
在 Intel x86 架构中,汇编语句 cmpxchg 被用于实现 compare_and_swap() 指令,通过 lock cmpxchg <目标操作数>, <源操作数> 锁定总线以保证操作的原子性。
ARM 架构无 cmpxchg 指令,采用 load-link/store-conditional (LL/SC) 机制,通过 LDREX(加载并标记原子操作)和 STREX(条件存储)实现。
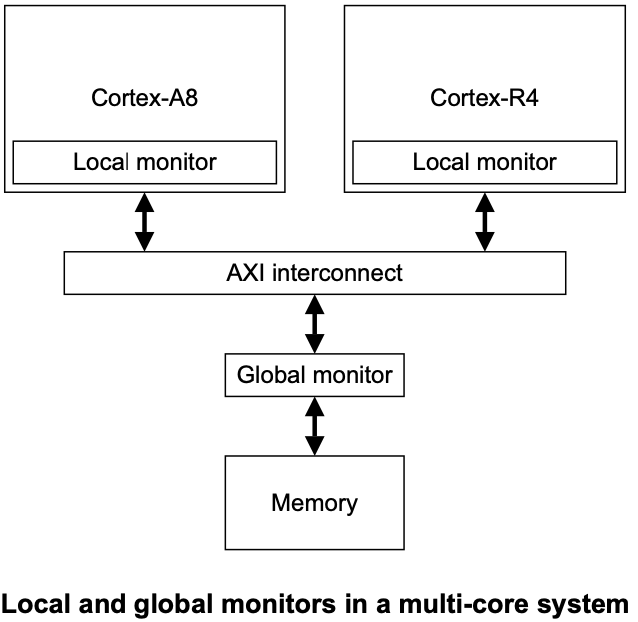
要实现原子操作,程序员必须重试该操作(同时执行 LDREX 与 STREX),直到独占监视器发出成功信号为止。
LDREX/STREX 指令在实际场景中的执行示例
| Thread 1 | Thread 2 | Status of the local monitor after the operation execution |
|---|---|---|
| Access state: Open | ||
| LDREX | Access state: Exclusive | |
| LDREX | Access state: Exclusive | |
| Modify | Access state: Exclusive | |
| STREX | Access state: Open | |
| Modify | Access state: Open | |
| STREX | Access State: Open; Failed to store |
LDREX/STREX 的原子性需要独占状态不被其他线程打断,若有线程抢占独占权,先执行 LDREX 的线程最终会 STREX 失败,这也是 ARM 的 LL/SC 机制需要重试操作的原因。
1. 4. 3 Atomic Variables¶
- 基于 CAS 等原子指令实现,支持对整数、布尔等基本类型的原子更新,如
increment(&sequence);能保证sequence的自增过程不会被中断
void increment(atomic_int *v) {
int temp;
do {
temp = *v;
} while (temp != compare_and_swap(v, temp, temp + 1));
}
1. 4. 4 Mutex Lock¶
- 简化临界区保护,通过
acquire()和release()原子操作保证互斥,可基于 Test-and-Set 或 CAS 实现
while (true) {
acquire lock
critical section
release lock
remainder section
}
acquire() {
while (!available); // 当锁不可用时忙等待
available = false; // 成功获取锁后标记锁已被占用
}
release() {
available = true; // 标记锁已释放,其他线程可尝试获取
}
由于该方案需要用到忙等待,这种锁也被称为自旋锁(Spinlock),单处理器系统中,持有锁的线程被中断后,其他线程自旋会浪费 CPU。
改进:使用 yield(),自旋时放弃CPU,避免忙等浪费
void init() {
flag = 0; // 表示锁当前处于可用状态
}
void lock() {
while (TestAndSet(&flag, 1) == 1)
yield(); // give up the CPU
}
void unlock() {
flag = 0; // 表示锁已释放,其他线程可尝试获取
}
自旋锁在多核系统中广泛应用,如果锁的持有时间很短,一个线程可以在某个处理核心上自旋,同时另一个线程在另一个核心上执行其临界区代码。
1. 4. 5 信号量(Semaphore)¶
信号量能为进程同步其活动提供更复杂的方式,包含一个整数变量 S,仅通过 wait(S)(P操作) 和 signal(S)(V操作) 两个原子操作访问。
wait(S) {
while (S <= 0)
; // busy wait
S--;
}
signal(S) {
S++;
}
- 计数信号量(Counting semaphore):
S取值无限制,用于控制资源访问数(如线程池大小),可以通过二元信号量来实现计数信号量 - 二元信号量(Binary semaphore):
S仅取 0 或 1,等价于互斥锁
示例场景:进程 \(P_1\) 和 \(P_2\) 需要 \(S_1\) 先于 \(S_2\) 执行
Create a semaphore “synch” initialized to 0
P1:
S₁;
signal(synch);
P2:
wait(synch);
S₂;
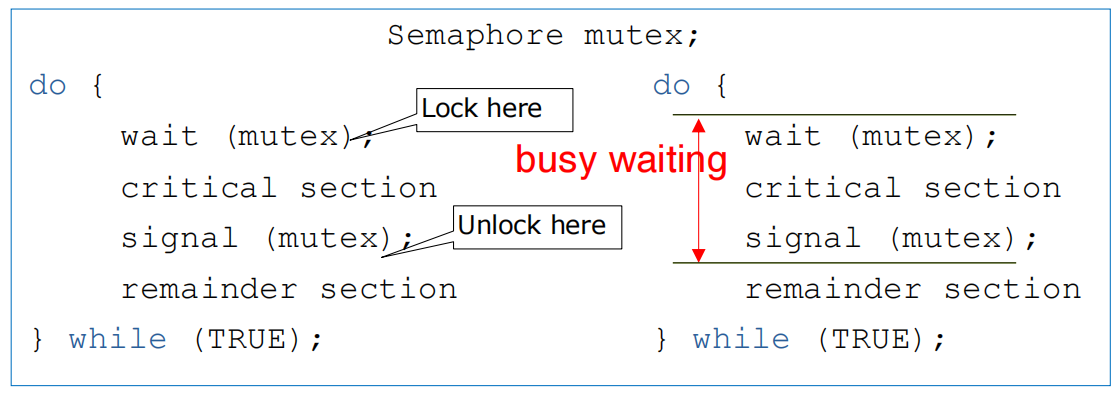
信号量可以实现互斥,但当其中一个进程执行 wait(mutex) 并成功获取锁后,另一个进程会进入 wait 操作里的 while 循环,即忙等待阶段。
改进:引入等待队列(Waiting Queue),避免忙等
typedef struct {
int value;
struct list_head *waiting_queue; // 等待进程队列
} semaphore;
void wait(semaphore *S) {
S->value--;
if (S->value < 0) {
add this process to S->list;;
block(); // 阻塞进程,将调用该操作的进程放入对应的等待队列中
}
}
void signal(semaphore *S) {
S->value++;
if (S->value <= 0) {
remove a process P from S->list;
wakeup(P); // 唤醒进程,从等待队列中取出一个进程,并将其放入就绪队列
}
}
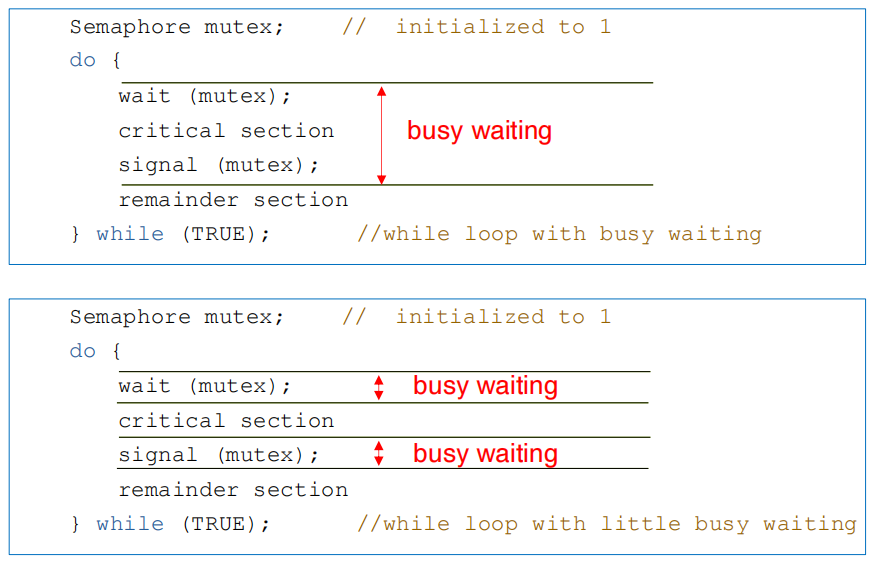
改进后,wait/signal 里的忙等待仅存在于原子性检查信号量状态的瞬间(而非持续循环),时间被大幅压缩,几乎可以忽略。
实现带等待队列的无忙等待锁
typedef struct __lock_t {
int flag; // 锁的状态标识:0 = 可用,1 = 被占用
int guard; // 守卫锁(自旋锁):保护 flag 和队列的原子操作
queue_t *q; // 等待队列:存放等待获取锁的线程 ID
} lock_t;
void lock_t_init(lock_t *m) {
m->flag = 0;
m->guard = 0;
queue_init(m->q)
}
void lock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
; // spin on guard
// CS to protect m->flag
if (m->flag == 0) {
m->flag = 1;
m->guard = 0;
} else {
queue_add(m->q, gettid());
m->guard = 0;
park(); // 挂起当前线程(放弃CPU)
}
}
void unlock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
;
if (queue_empty(m->q)) {
m->flag = 0;
} else {
unpark(queue_remove(m->q)); // 唤醒队列首个等待线程
}
m->guard = 0;
}
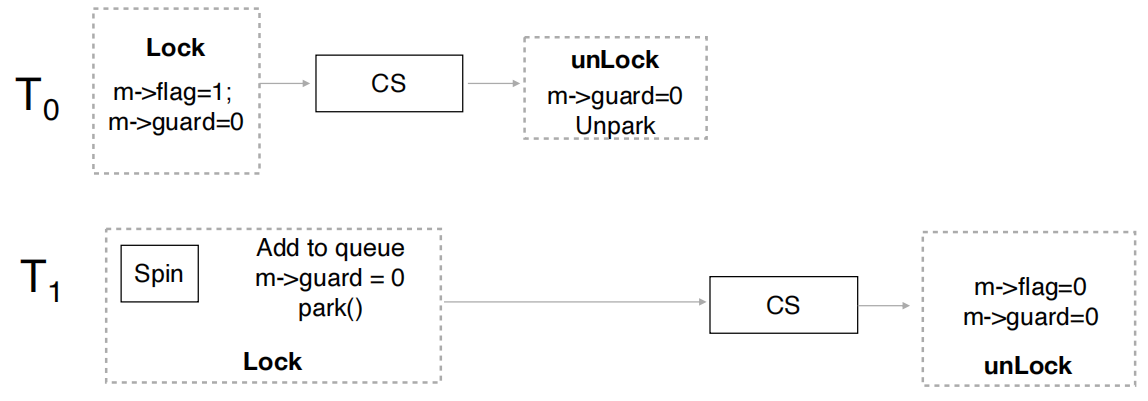
此时我们有一个小临界区用于保护 m->flag,同时还有一个程序层面的大临界区。
常见问题与解决方案
- 死锁(Deadlock)
- 定义:两个或多个进程无限等待对方持有的资源,导致所有进程阻塞。
- 示例:两个信号量
S和Q初始值为 1,\(P_0\) 先wait(S)再wait(Q),\(P_1\) 先wait(Q)再wait(S),双方互相等待。
- 饥饿(Starvation)
- 定义:进程无限期被阻塞在等待队列中,永远无法获取资源。
- 饥饿 \(≠\) 死锁,死锁是循环等待,饥饿是资源分配优先级导致的长期等待。
- 优先级反转(Priority Inversion)
- 定义:高优先级进程被低优先级任务间接抢占
- 低优先级任务持有锁,但由于优先级较低,始终无法获得 CPU 资源,因此永远无法完成任务并释放锁,高优先级任务等待该锁,陷入无限期等待。
- 优先级 PL < PM < PH,PL 持有 PH 需要的锁,PM 抢占 PL 的 CPU,PH 阻塞,相当于反转了 PM 和 PH 的优先级。
- 解决方案:优先级继承,将持有锁的低优先级进程临时提升为等待进程的最高优先级。
- 定义:高优先级进程被低优先级任务间接抢占
2 Synchronization Examples¶
实际案例:CVE-2025-68260
- 首个影响 Linux 内核 Rust 代码的 CVE,涉及基于 Rust 的 Android Binder(
rust_binder) -
根本原因:锁覆盖不足导致竞态条件
- 本地列表(
local_list)并非深拷贝,仍引用共享节点,节点的prev/next指针可被并发修改 - 不变量(invariant)假设节点仅存在于一个列表或无列表中,
unlock()后并发修改导致该不变量失效
Thread A Thread B lock()
move list items → local_list
unlock()
iterate local_list // still accesses shared node linkslock()
unsafe_remove(node)
unlock() - 本地列表(
2. 1 Classical Synchronization Problems¶
2. 1. 1 Bounded-buffer problem(Producer-consumer problem)¶
- 两个进程共享 \(N\) 个缓冲区,生产者生成数据写入缓冲区,消费者从缓冲区读取数据
- 生产者不写入满缓冲区,消费者不读取空缓冲区
| 信号量 | 初始值 | 作用 |
|---|---|---|
lock_buffer |
\(1\) | 保证缓冲区操作互斥 |
full_slots |
\(0\) | 已占用缓冲区数量(消费者条件) |
empty_slots |
\(N\) | 空闲缓冲区数量(生产者条件) |
核心代码
// The producer process
do {
//produce an item
...
wait(empty_slots);
wait(lock_buffer);
//add the item to the buffer
...
signal(lock_buffer);
signal(full_slots);
} while (TRUE)
// The consumer process:
do {
wait(full_slots);
wait(lock_buffer);
//remove an item from buffer
...
signal(lock_buffer);
signal(empty_slots);
//consume the item
...
} while (TRUE);
2. 1. 2 Readers-writers problem¶
- 一个数据集被多个并发进程共享,读者仅读取,写者可读写
- 多个读者可并发读取(共享访问),仅一个写者可独占访问(读写互斥、写写互斥)。
| 组件 | 初始值 | 作用 |
|---|---|---|
sem_lock |
\(1\) | 保护 read_count 计数 |
sem_write |
\(1\) | 保证写操作独占 |
read_count |
\(0\) | 当前活跃读者数量 |
核心代码
//The writer process
do {
wait(sem_write);
//write the shared data
...
signal(sem_write);
} while (TRUE);
// The structure of a reader process
do {
wait(sem_lock);
read_count++ ;
if (read_count == 1) //first reader
wait(sem_write) ; //block write
signal(sem_lock)
//reading data
...
wait(sem_lock) ;
read_count--;
if (read_count == 0)
signal(sem_write) ;
signal(sem_lock) ;
} while(TRUE);
- 读者优先:无写者活跃时,新读者直接读取,写者可能饥饿
- 写者优先:写者就绪后优先执行,新读者需等待,读者可能饥饿
- 上述代码实现的是读者优先
2. 1. 3 Dining-philosophers problem¶
- 哲学家围坐圆桌,交替思考/进餐,每两位相邻哲学家共享一根筷子,需同时持有左右两根筷子才能进餐
- 哲学家就餐问题代表了多资源同步的场景,核心挑战是避免死锁
- 解决方案(假设是5位哲学家):信号量
chopstick[5]的初始值设为 1
初始解决方案
Philosopher i (out of 5):
do {
wait(chopstick[i]);
wait(chopstick[(i+1)%5]);
eat
signal(chopstick[i]);
signal(chopstick[(i+1)%5]);
think
} while (TRUE);
- 死锁原因:所有哲学家同时拿起左筷子,均等待右筷子
避免死锁的方案
- 最多允许 4 位哲学家同时就座
- 仅当两根筷子均可用时,才原子性拿起(需临界区保护)
- 不对称方案:奇数号哲学家先拿左筷子,偶数号先拿右筷子
不对称方案核心代码
void pickup(Phil_struct *ps) {
Sticks *pp = (Sticks *)ps->v;
int phil_count = pp->phil_count;
if (ps->id % 2 == 1) { // 奇数:左→右
pthread_mutex_lock(pp->lock[ps->id]);
pthread_mutex_lock(pp->lock[(ps->id+1)%phil_count]);
} else { // 偶数:右→左
pthread_mutex_lock(pp->lock[(ps->id+1)%phil_count]);
pthread_mutex_lock(pp->lock[ps->id]);
}
}
void putdown(Phil_struct *ps) {
// 解锁顺序与拿起顺序相反
Sticks *pp = (Sticks *)ps->v;
int phil_count = pp->phil_count;
if (ps->id % 2 == 1) {
pthread_mutex_unlock(pp->lock[(ps->id+1)%phil_count]);
pthread_mutex_unlock(pp->lock[ps->id]);
} else {
pthread_mutex_unlock(pp->lock[ps->id]);
pthread_mutex_unlock(pp->lock[(ps->id+1)%phil_count]);
}
}
2. 2 Linus Synchronization¶
- 内核特性:2.6 版本前通过禁用中断实现短临界区,2.6及以后支持完全抢占式
2. 2. 1 Atomic integers¶
- 头文件:
linux/include/linux/atomic.h、linux/include/asm-generic/atomic.h atomic_t是原子整数对应的类型- 简单操作:
atomic_read()、atomic_set()等 - 算术操作:
atomic_{add,sub,inc,dec}()、atomic_{add,sub,inc,dec}_return{_relaxed,_acquire,_release}()、atomic_fetch_{add,sub,inc,dec}{_relaxed,_acquire,_release}()等

- 按位操作:
atomic_{and,or,xor,andnot}()、atomic_fetch_{and,or,xor,andnot}{,_relaxed,_acquire,_release}()等 - 交换操作:
atomic_xchg{,_relaxed,_acquire,_release}()、atomic_cmpxchg{,_relaxed,_acquire,_release}()、atomic_try_cmpxchg{,_relaxed,_acquire,_release}()等
2. 2. 2 Spinlock¶
- 头文件:
linux/include/linux/spinlock.h
2. 2. 3 Semaphore¶
down(&sem):申请资源(count--),若count≤0则睡眠(睡眠前释放自旋锁)up(&sem):释放资源(count++),若等待队列非空则唤醒线程
核心代码
struct semaphore {
raw_spinlock_t lock; // 保护信号量的自旋锁
unsigned int count; // 资源计数
struct list_head wait_list; // 等待队列
};
void down(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(down);
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;
else
__up(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(up);
2. 2. 4 Reader-Writer Locks¶
- 类型:
rw_semaphore,支持多读单写,平衡读写性能 - 核心思想:读操作无锁(快速),写操作通过RCU(Read-Copy-Update)实现,延迟释放旧数据,用于就地更新链表结构
- 写操作步骤:
- 创建新数据结构,复制旧数据
- 修改新结构
- 原子更新全局指针指向新结构
- 等待所有旧读者完成后,释放旧结构(如
synchronize_rcu())
2. 3 POSIX Synchronization¶
2. 3. 1 POSIX Mutex Locks¶
#include <pthread.h>
pthread_mutex_t mutex;
/* create and initialize the mutex lock */
pthread_mutex_init(&mutex,NULL);
/* acquire the mutex lock */
pthread_mutex_lock(&mutex);
/* critical section */
/* release the mutex lock */
pthread_mutex_unlock(&mutex);
2. 3. 2 POSIX Semaphores¶
| 类型 | 适用场景 |
|---|---|
| Named semaphores | 无关联进程间同步 |
| Unnamed semaphores | 同一进程内线程间同步 |
#include <semaphore.h>
sem_t *sem;
/* Create the semaphore and initialize it to 1 */
sem = sem_open("SEM", O_CREAT, 0666, 1); // Named semaphores
sem_init(&sem, 0, 1); // Unnamed semaphores
/* acquire the semaphore */
sem_wait(sem);
/* critical section */
/* release the semaphore */
sem_post(sem);
2. 3. 3 POSIX Condition Variables¶
- 条件变量是一种同步原语,线程等待特定条件成立,由其他线程唤醒,避免忙等
- 条件变量是用户态对象,无法跨进程共享
- 条件变量支持的操作:
wait(condition, lock):释放锁,让线程进入睡眠状态,直到条件变量被发信号;当线程再次唤醒时,会在返回前重新获取锁signal(condition, lock):若有线程在该条件变量上等待,则唤醒其中一个。调用者必须持有锁,且该锁必须与wait调用中使用的锁是同一个broadcast(condition, lock):与signal作用类似,但会唤醒所有等待的线程
- 调用
signal后,发信号的线程会保留锁,被唤醒的线程会进入等待锁的队列 - 线程在
wait后唤醒时,无法保证期望的条件仍然成立,可能有其他线程已经抢先操作了 - 条件变量是一个显式队列,当执行状态(即某个条件)不符合预期时,线程可以通过等待该条件,将自身加入这个队列
- 当其他线程修改了前述状态后,可以通过向该条件发信号,唤醒一个(或多个)等待线程,让它们继续执行
代码示例
pthread_mutex_t mutex;
pthread_cond_t cond_var;
pthread_mutex_init(&mutex,NULL);
pthread_cond_init(&cond_var,NULL);
pthread_mutex_lock(&mutex);
while (a != b)
pthread_cond_wait(&cond_var, &mutex); // wait时释放锁,被信号唤醒时重新获取锁
pthread_mutex_unlock(&mutex);
pthread_mutex_lock(&mutex);
a = b;
pthread_cond_signal(&cond_var);
pthread_mutex_unlock(&mutex);
pthread_mutex_t mutex;
pthread_cond_t condition;
// Thread 1
pthread_mutex_lock(&mutex); //mutex lock
while(!condition){
pthread_cond_wait(&condition, &mutex); //wait for the condition
}
/* do what you want */
pthread_mutex_unlock(&mutex);
// Thread 2
pthread_mutex_lock(&mutex);
/* do something that may fulfill the condition */
pthread_mutex_unlock(&mutex);
pthread_cond_signal(&condition); //wake up thread 1
Why need mutex?
保护共享资源的访问,配合 wait 操作的原子性。
What's the difference between condition variable and semaphore?
条件变量仅关注条件是否成立,不维护计数;信号量可维护资源计数。
What if we only care if the queue is empty or not, while don’t care the queue length?
更适合用条件变量 + 互斥锁:只需将队列非空作为等待条件,通过 while(队列为空) 循环调用 pthread_cond_wait(),配合互斥锁保护队列的修改操作。
3 Deadlocks¶
- 死锁是指一组进程互相阻塞的状态,每个进程都持有部分资源,同时等待其他进程持有的资源,导致所有进程无法继续推进。
典型示例
- 硬件资源争夺:系统有 \(2\) 个磁盘驱动器,进程 \(P_1\) 和 \(P_2\) 各持有 \(1\) 个,且均需另 \(1\) 个才能继续
- 信号量误用:信号量 \(A\)、\(B\) 初始值为 \(1\),\(P_1\) 执行
wait(A) → wait(B),\(P_2\) 执行wait(B)→wait(A),二者互相等待 - 线程锁竞争:两个线程争夺两个互斥锁(
first_mutex、second_mutex),若线程 \(1\) 持有first_mutex、线程 \(2\) 持有second_mutex,后续互相等待对方的锁,则触发死锁 - 桥梁通行:单向通行的桥梁,多辆车占用不同路段且互相等待,需倒车(抢占资源+回滚)解决
- 死锁的四个条件
- 互斥(Mutual exclusion):资源同一时间只能被一个进程独占
- 持有并等待(Hold and wait):进程持有至少一个资源,同时等待其他进程的资源
- 无抢占(No preemption):资源只能由持有进程主动释放,无法强制抢占
- 循环等待(Circular wait):存在进程集合 \({P_0,P_1,...,P_n}\),\(P_0\) 等待 \(P_1\) 的资源,\(P_1\) 等待 \(P_2\) 的资源,...,\(P_n\) 等待 \(P_0\) 的资源,形成闭环
3. 1 Resource-Allocation Graph¶
- 资源类型:\(R_1, R_2, \cdots, R_m\)(如 CPU、内存、I/O 设备),每种资源有 \(W_i\) 个实例
- 进程使用资源的流程:请求(Request)→ 使用(Use)→ 释放(Release)。
- 节点:
- 进程节点(\(P_1, P_2, \cdots, P_n\)):表示系统中的进程
- 资源节点(\(R_1, R_2, \cdots, R_m\)):表示资源类型,节点旁数字表示实例数
- 边:
- 请求边(\(P_i→R_j\)):进 \(P_i\) 请求资源 \(R_j\),处于等待状态
- 分配边(\(R_j→P_i\)):资源 \(R_j\) 的一个实例已分配给进程 \(P_i\)
RAG 图例

- 死锁判断规则
- 无环 \(→\) 无死锁
- 有环
- 单实例资源类型 \(→\) 一定死锁
- 多实例资源类型 \(→\) 可能死锁(需结合资源实例数判断)
死锁实例
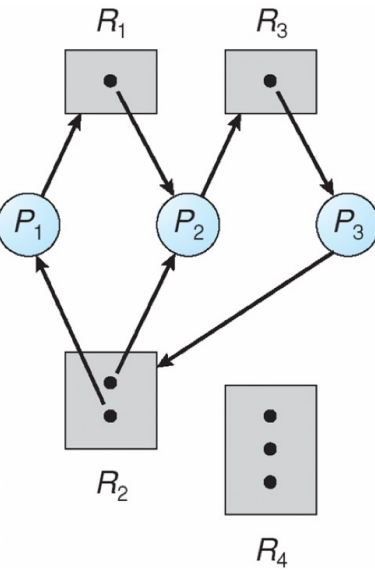 |
存在死锁 |
|---|---|
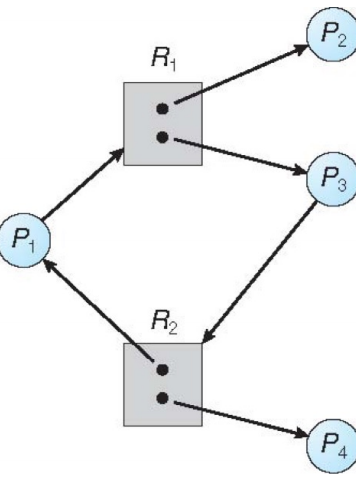 |
不存在死锁 |
3. 2 Handling deadlocks¶
3. 2. 1 Deadlock prevention¶
| 针对条件 | 预防策略 | 优缺点 |
|---|---|---|
| 互斥 | 仅共享资源可避免(非共享资源无法打破) | 无实际可操作性(多数资源为非共享) |
| 持有并等待 | 1. 进程启动前申请所有所需资源; 2. 申请新资源时必须释放已持有资源 |
资源利用率低,可能导致饥饿 |
| 非抢占 | 进程请求资源失败时,抢占其已持有资源,加入等待队列,进程需重新获取所有等待资源才能重启 | 适用于可抢占资源(如内存),不适用于不可抢占资源(如打印机) |
| 循环等待 | 1. 为所有资源类型分配唯一编号; 2. 进程必须按编号递增顺序申请资源 |
最常用,操作系统广泛采用(如 mutex 按编号顺序锁定) |
错误示例
/* thread_one 在该函数中运行 */
void *do_work_one(void *param)
{
pthread_mutex_lock(&first_mutex);
pthread_mutex_lock(&second_mutex);
/* 执行一些操作 */
pthread_mutex_unlock(&second_mutex);
pthread_mutex_unlock(&first_mutex);
pthread_exit(0);
}
/* thread_two 在该函数中运行 */
void *do_work_two(void *param)
{
pthread_mutex_lock(&second_mutex); // 错误:未按编号顺序获取
pthread_mutex_lock(&first_mutex);
/* 执行一些操作 */
pthread_mutex_unlock(&first_mutex);
pthread_mutex_unlock(&second_mutex);
pthread_exit(0);
}
针对动态获取的锁
void transaction(Account from, Account to, double amount)
{
mutex lock1, lock2;
lock1 = get_lock(from); // 获取转出账户对应的锁
lock2 = get_lock(to); // 获取转入账户对应的锁
acquire(lock1); // 加锁(占用转出账户的锁)
acquire(lock2); // 加锁(占用转入账户的锁)
withdraw(from, amount); // 从转出账户扣款
deposit(to, amount); // 向转入账户存款
release(lock2); // 释放转入账户的锁
release(lock1); // 释放转出账户的锁
}
transaction(checking_account, savings_account, 25.0)
transaction(savings_account, checking_account, 50.0)
当两个线程同时执行这两个转账调用时,两个线程会互相等待对方持有的锁,形成循环等待,最终卡死。
3. 2. 2 Deadlock avoidance¶
- 允许进程动态申请资源,但在分配前判断分配后系统是否处于安全状态,仅当安全时才分配,避免进入不安全状态
- 安全状态:存在进程序列 \(<P_1, P_2,\cdots, P_n>\),使得每个进程 \(P_i\) 的剩余资源需求可由当前可用资源和序列中前面进程释放的资源满足,最终所有进程可完成
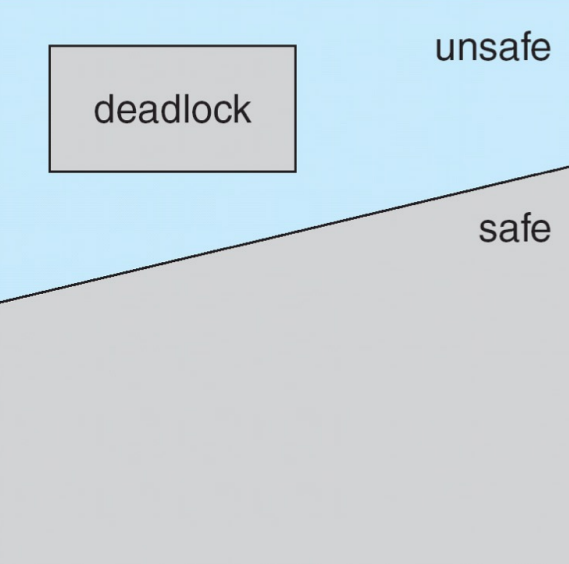
示例
已知系统的资源总量为 12,初始可用资源量 Available=3,进程资源表如下:
| Max need | Current have | Extra need | |
|---|---|---|---|
| \(P_0\) | 10 | 5 | 5 |
| \(P_1\) | 4 | 2 | 2 |
| \(P₂\) | 9 | 2 | 7 |
则安全序列为 \(P_1 → P_0 → P_2\),验证如下:
-
- \(P_1\) 的
Extra need=2\(≤\) 当前Available=3,分配 \(2\) 个资源给 \(P_1\) - \(P_1\) 完成后归还所有资源(
Current have=4),Available更新为3-2+4=5
处理 \(P_1\)
Max need Current have Extra need \(P_0\) 10 5 5 \(P_1\) 0 0 0 \(P₂\) 9 2 7 - \(P_1\) 的
-
处理 \(P_0\)
- \(P_0\) 的
Extra need=5\(≤\) 当前Available=5,分配 \(5\) 个资源给 \(P_0\) - \(P_0\) 完成后归还所有资源(
Current have=10),Available更新为5-5+10=10
Max need Current have Extra need \(P_0\) 0 0 0 \(P_1\) 0 0 0 \(P_2\) 9 2 7 - \(P_0\) 的
-
处理 \(P_2\)
- \(P_2\) 的
Extra need=7\(≤\) 当前Available=10,分配 \(7\) 个资源给 \(P_2\) - \(P_2\) 完成后归还所有资源,所有进程顺利结束,该序列为安全序列
- \(P_2\) 的
不安全状态示例(额外分配)
- 给 \(P_2\) 多分配 \(1\) 个资源后,
Current have(P₂)变为 \(3\),Extra need(P₂)变为 \(6\),Available更新为 \(2\)
| Max need | Current have | Extra need | |
|---|---|---|---|
| \(P_0\) | 10 | 5 | 5 |
| \(P_1\) | 4 | 2 | 2 |
| \(P_2\) | 9 | 3 | 6 |
- 尝试处理 \(P_1\)
- \(P_1\) 的
Extra need=2\(≤\) 当前Available=2,分配 \(2\) 个资源给\(P_1\) - \(P_1\) 完成后归还资源,
Available更新为2-2+4=4 - 此时
Available=4,无法满足 \(P_0\) 的Extra need(5)或 \(P_2\) 的Extra need(6),无后续可推进的进程,当前状态为不安全状态,存在死锁风险
- \(P_1\) 的
Deadlock Avoidance Algorithms
-
单实例资源(Single instance):资源分配图(resource-allocation graph)
- 新增声明边(claim edge) \(P_i → R_j\),用虚线表示,表示进程 \(P_i\) 可能请求资源 \(R_j\),系统中的资源必须预先声明
- 进程请求资源时,将声明边转为请求边
- 若请求边转换为分配边后无环(即安全状态),允许资源分配给进程,否则拒绝
- 当进程释放资源时,分配边会重新转换为声明边
-
多实例资源(Multiple instances):银行家算法(Banker's Algorithm)
- 进程需提前声明每种资源的最大使用量
- 进程请求资源时可能需要等待,进程获取到其所需的所有资源后必须在有限时间内释放这些资源
数据结构 含义 available[m]每种资源的可用实例数,如 available[j]表示第 \(j\) 类资源的空闲数max[n×m]进程的最大资源需求,如 max[i][j]表示进程 \(P_i\) 对第 \(j\) 类资源的最大需求allocation[n×m]进程已分配的资源,如 allocation[i][j]表示进程 \(P_i\) 当前持有第 \(j\) 类资源的数量need[n×m]进程的剩余资源需求,如 need[i][j] = max[i][j] - allocation[i][j]- 安全算法(判断系统是否安全):
- 初始化:\(\text{work} = \text{available}\),\(\text{finish}[i] = \text{false}\),\(i = 1, 2, \cdots, n-1\)
- 循环:找到满足 \(\text{finish}[i] = \text{false}\) 且 \(\text{need}[i] ≤ \text{work}\) 的进程 \(P_i\),若不存在这样的 \(i\),跳到终止步骤
- 更新:释放 \(P_i\) 的资源,\(\text{work} = \text{work} + \text{allocation}[i]\),\(\text{finish}[i] = \text{true}\),跳回循环步骤
- 终止:若 \(\forall \, i \in \{ 1, 2, \cdots, n-1\}\),\(\text{finish}[i] = \text{true}\)f,则系统处于安全状态,否则不安全
- 资源请求算法(处理进程的资源申请):
- 若 \(\text{request}[i] > \text{need}[i]\),进程超出最大资源申请量,报错
- 若 \(\text{request}[i] > \text{available}\),资源不足,进程需等待
- 模拟分配
available -= request[i]allocation[i] += request[i]need[i] -= request[i]
- 用安全算法判断模拟后是否安全,安全则实际分配,否则撤销模拟,进程等待
银行家算法示例
已知有 \(\text{P}_0\)~ \(\text{P}_4\) 共 \(5\) 个进程,\(A\)(\(10\) 个实例)、\(B\)(\(5\) 个实例)、\(C\)(\(7\) 个实例)共 \(3\) 种资源,\(T_0\) 时有初始可用资源 \(\text{available} = (3,3,2)\),其余初始状态如下:
进程 allocation(A,B,C)max(A,B,C)need(A, B, C)\(\text{P}_0\) 0,1,0 7,5,3 7,4,3 \(\text{P}_1\) 2,0,0 3,2,2 1,2,2 \(\text{P}_2\) 3,0,2 9,0,2 6,0,0 \(\text{P}_3\) 2,1,1 2,2,2 0,1,1 \(\text{P}_4\) 0,0,2 4,3,3 4,3,1 初始 \(\text{work} = \text{available} = (3,3,2)\),接下来执行步骤如下:
- 选 \(\text{P}_1\),标记 \(\text{P}_1\) 完成,\(\text{work}\) 更新为 \((5,3,2)\)
- 选 \(\text{P}_3\),标记 \(\text{P}_3\) 完成,\(\text{work}\) 更新为 \((7,4,3)\)
- 选 \(\text{P}_4\),标记 \(\text{P}_4\) 完成,\(\text{work}\) 更新为 \((7,4,5)\)
- 选 \(\text{P}_2\),标记 \(\text{P}_2\) 完成,\(\text{work}\) 更新为 \((10,4,7)\)
- 选 \(\text{P}_0\),标记 \(\text{P}_0\) 完成,\(\text{work}\) 更新为 \((10,5,7)\)
故有安全序列:\(\text{P}_1 \to \text{P}_3 \to \text{P}_4 \to \text{P}_2 \to \text{P}_0\)
3. 2. 3 Deadlock detection¶
-
允许系统进入死锁,通过算法定期检测,一旦发现死锁则触发恢复
-
单实例资源:等待图(Wait-for Graph)
- 节点表示进程,边 \(P_i → P_j\) 表示 \(P_i\) 等待 \(P_j\) 持有的资源
- 定期搜索等待图,若存在环则说明系统处于死锁状态,时间复杂度为 \(O(n^2)\)
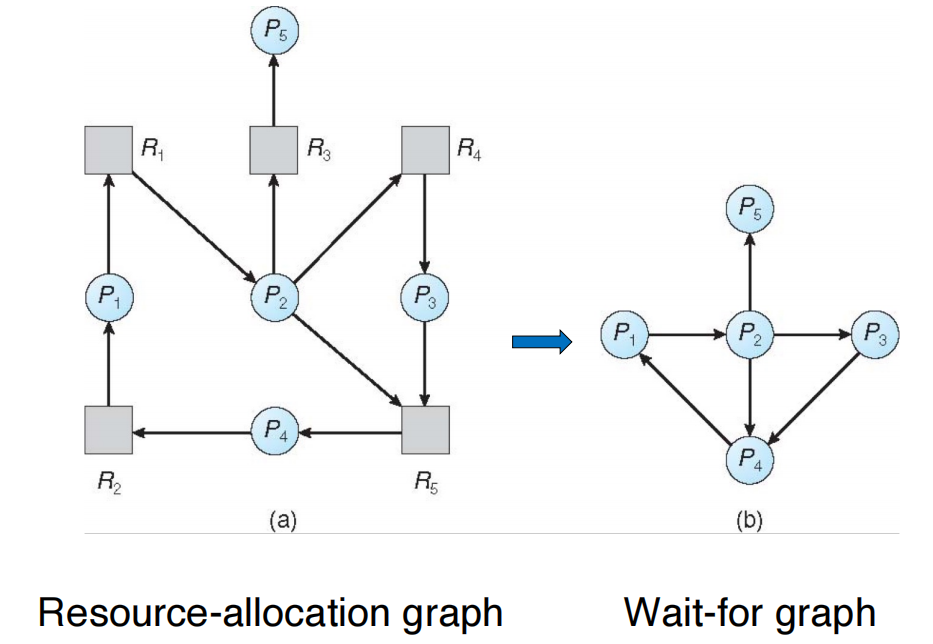
- 多实例资源:类银行家算法
- 初始化:\(\text{work} = \text{available}\),\(\text{finish}[i] = \text{false}\)(\(\text{allocation}[i] ≠ 0\) 时)
- 找到 \(\text{finish}[i] = \text{false}\) 且 \(\text{request}[i] ≤ \text{work}\) 的进程 \(P_i\),更新
work += allocation[i],finish[i] = true - 若存在 \(\text{finish}[i] = \text{false}\) 的进程,则该进程死锁
What is the difference between this algorithm and the Banker’s algorithm?
- 银行家算法在资源分配前判断,检查进程剩余需求
- 死锁检测算法在资源分配后判断,检查进程当前请求
类银行家算法示例
已知有 \(\text{P}_0\)~ \(\text{P}_4\) 共 \(5\) 个进程,\(A\)(\(7\) 个实例)、\(B\)(\(2\) 个实例)、\(C\)(\(6\) 个实例)共 \(3\) 种资源,初始状态如下:
| 进程 | allocation(A,B,C) |
max(A,B,C) |
available(A, B, C) |
|---|---|---|---|
| \(P_0\) | 0, 1, 0 | 0, 0, 0 | 0, 0, 0 |
| \(P_1\) | 2, 0, 0 | 2, 0, 2 | |
| \(P_2\) | 3, 0, 3 | 0, 0, 0 | |
| \(P_3\) | 2, 1, 1 | 1, 0, 0 | |
| \(P_4\) | 0, 0, 2 | 0, 0, 2 |
执行序列 \(<P_0, P_2, P_3, P_1, P_4>\) 后,所有进程的 finish[i] = true,此时系统无死锁。
若 \(P_2\) 额外请求1个类型 \(C\) 的资源,则相关状态更新如下:
| 进程 | allocation(A,B,C) |
max(A,B,C) |
available(A, B, C) |
|---|---|---|---|
| \(P_0\) | 0, 1, 0 | 0, 0, 0 | 0, 0, 0 |
| \(P_1\) | 2, 0, 0 | 2, 0, 2 | |
| \(P_2\) | 3, 0, 3 | 0, 0, 1 | |
| \(P_3\) | 2, 1, 1 | 1, 0, 0 | |
| \(P_4\) | 0, 0, 2 | 0, 0, 2 |
检测发现仅能回收 \(P_0\) 持有的资源,但资源不足以满足其他进程的请求,此时系统存在死锁,死锁进程为 \(P_1、P_2、P_3、P_4\)。
3. 2. 4 Deadlock Recovery¶
核心思想:打破死锁的循环等待,让进程继续推进。
-
终止进程
- 方案
- 终止所有死锁进程(简单但代价大)
- 逐个终止进程,直到死锁解除(需选择最优终止顺序)
- 终止顺序选择依据:进程优先级、进程已运行时间/剩余运行时间、已使用资源/剩余所需资源、进程影响范围(需终止的进程数)、进程类型(交互式/批处理)
- 方案
-
资源抢占
- 选择受害者(被抢占资源的进程)
- 抢占资源并分配给死锁进程
- 回滚受害者进程到上一个安全状态(避免数据不一致)
- 注意:避免饥饿(需保证同一进程不被反复抢占)