Chapter 16 Query Optimization¶
1 Overview¶
查询优化(query optimization)的目标是在多个逻辑等价、但执行代价可能差异巨大的方案中,选择估计代价最低的执行计划。实际差异可能从秒级扩大到天级,因此优化器通常是 DBMS 性能的核心组件之一。
- 等价表达式(Equivalent expressions):同一查询可以写成多个关系代数表达式,只要它们在所有合法数据库实例上产生相同结果,就认为等价。
- 物理执行算法(Evaluation algorithms):同一个关系代数操作可以用不同算法实现,例如不同连接算法、扫描方式和排序方式。
- 执行计划(Evaluation plan):明确指定每个操作使用的算法,以及这些操作之间如何协调执行的计划。
基于代价的查询优化通常分为三步:
- 使用等价规则生成逻辑等价表达式。
- 为逻辑表达式标注具体物理算法,形成候选执行计划。
- 根据统计信息和算法代价公式,估计每个计划的成本并选择最便宜的计划。
代价估计依赖三类信息:
- 基本统计信息:关系大小、元组数、属性不同值个数等。
- 中间结果统计估计:复杂表达式的中间结果大小和不同值个数。
- 算法代价公式:中选择、排序、连接等操作的 I/O 成本公式。
查看查询执行计划
大多数数据库支持 EXPLAIN <query>,用于显示优化器选择的计划和估计成本。
- Oracle:
explain plan for <query>,再执行select * from table(dbms_xplan.display) - SQL Server:
set showplan_text on - PostgreSQL:
EXPLAIN ANALYZE <query>会实际执行查询并显示运行时统计信息
PostgreSQL 等系统中,代价有时写成 f..l,其中 f 表示产出第一条元组的代价,l 表示产出全部结果的总代价。
2 Statistical Information for Cost Estimation¶
2. 1 Basic Catalog Statistics¶
优化器通常在系统目录(catalog)中维护以下统计信息:
| 记号 | 含义 |
|---|---|
| \(n_r\) | 关系 \(r\) 中的元组数 |
| \(b_r\) | 存放关系 \(r\) 元组的数据块数 |
| \(l_r\) | 关系 \(r\) 中一条元组的大小 |
| \(f_r\) | 关系 \(r\) 的阻塞因子(blocking factor),即一个块可容纳的 \(r\) 元组数 |
| \(V(A,r)\) | 关系 \(r\) 中属性 \(A\) 的不同取值个数,也就是 \(\lvert \Pi_A(r) \rvert\) |
如果关系 \(r\) 的元组物理上存放在同一个文件中,则:
Histograms
直方图(histogram)用于更精细地估计属性值分布,尤其适合处理非均匀分布。
- 等宽直方图(Equi-width histogram):将属性值范围划分为宽度相同的区间。
- 等深直方图(Equi-depth histogram):将属性值范围划分为若干区间,使每个区间包含近似相同数量的元组。
- 很多数据库还会额外保存最常见的 \(n\) 个取值及其出现次数,直方图只针对剩余取值构建。
统计信息通常基于随机样本计算,可能过期。部分数据库需要手动执行 ANALYZE 更新统计信息,部分数据库会在元组数量变化达到一定比例后自动重新计算。
2. 2 Selection Size Estimation¶
对于等值选择:
若 \(A\) 是键属性,则:
对于比较选择,以 \(\sigma_{A \le v}(r)\) 为例,\(\sigma_{A \ge v}(r)\) 对称。令 \(c\) 为满足条件的估计元组数,若系统目录中有 \(\min(A,r)\) 和 \(\max(A,r)\),并假设 \(A\) 均匀分布,则:
若有直方图,可用直方图区间进一步修正估计。若没有统计信息,常粗略估计为:
2. 3 Complex Selection Size Estimation¶
条件 \(\theta_i\) 的选择率(selectivity)是关系 \(r\) 中元组满足该条件的概率。若满足 \(\theta_i\) 的元组数为 \(s_i\),则选择率为:
若假设多个条件相互独立,则:
- 合取选择(Conjunction)
- 析取选择(Disjunction)
- 否定选择(Negation)
2. 4 Join Size Estimation¶
Running example: student ⋈ takes
- \(n_{student}=5000\)
- \(f_{student}=50\),所以 \(b_{student}=5000/50=100\)
- \(n_{takes}=10000\)
- \(f_{takes}=25\),所以 \(b_{takes}=10000/25=400\)
- \(V(ID,takes)=2500\),平均每个选过课的学生选了 \(4\) 门课
takes.ID是引用student.ID的外键- \(V(ID,student)=5000\),因为
student.ID是主键
笛卡尔积 \(r \times s\) 有 \(n_r \cdot n_s\) 条元组,每条元组大小为 \(s_r+s_s\) 字节。
对自然连接 \(r \bowtie s\):
- 若 \(R \cap S = \emptyset\),则 \(r \bowtie s\) 等价于 \(r \times s\)。
- 若 \(R \cap S\) 是 \(R\) 的键,则 \(s\) 中每条元组至多与 \(r\) 中一条元组匹配,因此 \(|r \bowtie s| \le n_s\)。
- 若 \(R \cap S\) 是 \(S\) 中引用 \(R\) 的外键,则 \(|r \bowtie s| = n_s\),反向情形对称。
在 student ⋈ takes 中,takes.ID 是引用 student.ID 的外键,因此结果大小正好为:
若 \(R \cap S=\{A\}\),且 \(A\) 既不是 \(R\) 的键也不是 \(S\) 的键,则可估计:
或:
通常取两者中较小的估计,即:
若有直方图,可以对每个直方图区间分别估计后再求和。
不用外键信息估计 student ⋈ takes
已知 \(V(ID,takes)=2500\),\(V(ID,student)=5000\)。
取较小值 \(10000\),与使用外键信息得到的结果一致。
2. 5 Size Estimation for Other Operations¶
| 操作 | 估计大小 |
|---|---|
| 投影 \(\Pi_A(r)\) | \(V(A,r)\) |
| 分组聚合 \(_G\gamma_A(r)\) | \(V(G,r)\) |
| 同一关系上的选择并/交 | 改写为选择条件后按选择估计 |
| 不同关系的并 \(r \cup s\) | \(\lvert r \rvert + \lvert s \rvert\) |
| 不同关系的交 \(r \cap s\) | \(\min(\lvert r \rvert , \lvert s \rvert)\) |
| 差 \(r-s\) | $\lvert r \rvert $ |
| 左外连接 \(r ⟕ s\) | \(\lvert r \bowtie s \rvert + \lvert r \rvert\) |
| 全外连接 \(r ⟗ s\) | \(\lvert r \bowtie s \rvert +\lvert r \rvert + \lvert s \rvert\) |
并、交、差的粗略估计可能不准确,但能提供上界。
2. 6 Estimation of Distinct Values¶
对选择 \(\sigma_\theta(r)\):
- 若 \(\theta\) 强制 \(A\) 取某个指定值,如 \(A=3\),则 \(V(A,\sigma_\theta(r))=1\)。
- 若 \(\theta\) 强制 \(A\) 取指定集合中的一个值,如 \(A=1 \lor A=3 \lor A=4\),则 \(V(A,\sigma_\theta(r))\) 约为指定值个数。
- 若 \(\theta\) 是 \(A \ \text{op}\ v\) 形式,且选择率为 \(s\),则:
- 其他情况下常用近似:
对连接 \(r \bowtie s\):
- 若属性集 \(A\) 全部来自 \(r\),则:
- 若 \(A\) 同时包含来自 \(r\) 和 \(s\) 的属性,令 \(A_1\) 为 \(A\) 中来自 \(r\) 的属性,\(A_2\) 为 \(A\) 中来自 \(s\) 的属性,则可估计为:
对投影和分组属性,不同值估计通常直接继承原关系中的对应 \(V\) 值。对聚合结果:
min(A)与max(A):可估计为 \(\min(V(A,r),V(G,r))\),其中 \(G\) 是分组属性。- 其他聚合值:通常假设各组聚合结果互不相同,估计为 \(V(G,r)\)。
Campus Card Example
给定关系模式:
card(cno char(5), name char(8), depart char(10), balance integer)
pos(pno char(4), campus char(8), location char(10))
detail(cno char(5), pno char(4), cdate date, ctime time, amount integer, remark char(10))
统计假设:
- \(n_{card}=10000\),\(n_{pos}=100\),\(n_{detail}=10000000\)
- \(l_{card}=25\),\(l_{pos}=22\),\(l_{detail}=29\)
- \(V(campus,pos)=6\),\(V(location,pos)=20\)
- \(V(depart,card)=100\),\(V(name,card)=5000\)
detail.cdate在2017-01-01到2017-12-31之间均匀分布- 块大小为 \(4\) KB,B+ 树指针大小为 \(4\) 字节
card与detail均按cno顺序存放detail(cno)上有 B+ 树索引
估计 self join 结果大小
查询:
select d1.cno, d2.cno
from detail d1, detail d2
where d1.pno = d2.pno
and d1.cdate = d2.cdate
and d1.cdate between '2017-05-01' and '2017-07-31';
答案
\(V((pno,cdate),detail)=100 \times 365\)。日期范围约占全年 \(1/4\),所以估计结果大小为:
估计 card 与 detail 的块数
card 每块可容纳:
因此:
detail 每块可容纳:
因此:
估计 detail(cno) B+ 树高度
B+ 树扇出:
对 \(10000000\) 条记录,高度估计为 \(2\)。
估计 \(\sigma_{name='张三'}(card) \bowtie detail\) 的代价
先用文件扫描完成选择,再使用 indexed nested-loop join。
选择 card 的成本:
满足 name='张三' 的 card 元组数:
每个 card.cno 在 detail 中对应的块数:
连接成本:
若采用流水线执行,总成本为:
3 Transformation of Relational Expressions¶
两个关系代数表达式如果在每一个合法数据库实例上都产生相同的元组集合,则称为等价。元组顺序无关紧要,且不要求在违反完整性约束的数据库上仍然等价。
SQL 的输入和输出通常是多重集(multiset),因此 SQL 优化中的等价需要保持多重集中的重复次数一致。
3. 1 Basic Equivalence Rules¶
规则 1:合取选择可拆分
规则 2:选择操作可交换
规则 3:连续投影只保留最后需要的属性集
其中 \(L_1 \subseteq L_2 \subseteq \cdots \subseteq L_n\)。
规则 4:选择可与笛卡尔积或 theta join 合并
3. 2 Join Equivalence Rules¶
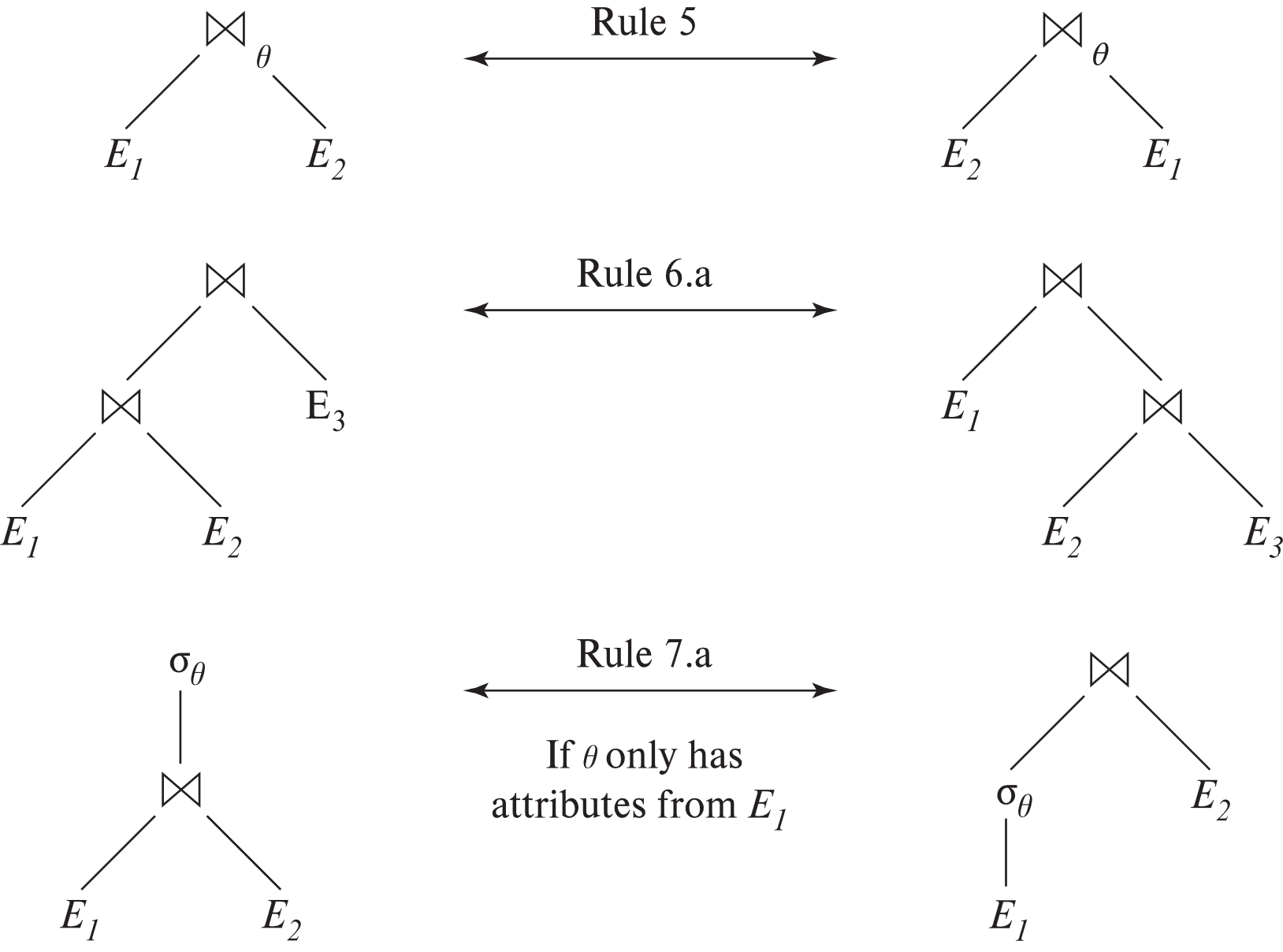
规则 5:theta join 与自然连接可交换
规则 6a:自然连接满足结合律
规则 6b:theta join 的结合律
其中 \(\theta_2\) 只涉及 \(E_2\) 和 \(E_3\) 的属性。
3. 3 Pushing Selections and Projections¶
规则 7a:选择下推到 join 的一侧
如果 \(\theta_0\) 只涉及 \(E_1\) 的属性,则:
规则 7b:选择同时下推到 join 两侧
如果 \(\theta_1\) 只涉及 \(E_1\) 的属性,\(\theta_2\) 只涉及 \(E_2\) 的属性,则:
规则 8a:投影分配到 theta join
如果 \(\theta\) 只涉及 \(L_1 \cup L_2\) 中的属性,则:
规则 8b:一般投影下推
对连接 \(E_1 \bowtie_\theta E_2\),令:
- \(L_1\) 为最终需要且来自 \(E_1\) 的属性。
- \(L_2\) 为最终需要且来自 \(E_2\) 的属性。
- \(L_3\) 为 \(\theta\) 中涉及 \(E_1\)、但不在 \(L_1 \cup L_2\) 中的属性。
- \(L_4\) 为 \(\theta\) 中涉及 \(E_2\)、但不在 \(L_1 \cup L_2\) 中的属性。
则:
类似等价也适用于左外连接、右外连接和全外连接,但外连接的等价规则限制更多。
3. 4 Set Operation Rules¶
规则 9:并和交可交换
集合差不可交换。
规则 10:并和交满足结合律
规则 11:选择可分配到并、交、差
另外:
但上一类只对交和差成立,不适用于并。
规则 12:投影可分配到并
3. 5 Aggregation and Outer Join Rules¶
规则 13:选择可下推到聚合前
若 \(\theta\) 只涉及分组属性 \(G\),则:
规则 14:外连接交换规则
全外连接可交换:
左外连接和右外连接本身不可交换,但有:
规则 15:选择可在特定条件下分配到左/右外连接
若 \(\theta_1\) 只涉及 \(E_1\) 的属性,则:
规则 16:某些外连接可替换为内连接
若 \(\theta_1\) 对 \(E_2\) 的属性是 null-rejecting 条件,即补 NULL 后一定无法通过选择条件,则:
对称地:
外连接不满足很多普通 join 的等价规则
例如:
外连接通常也不满足结合律:
4 Transformation Examples¶
4. 1 Pushing Selections¶
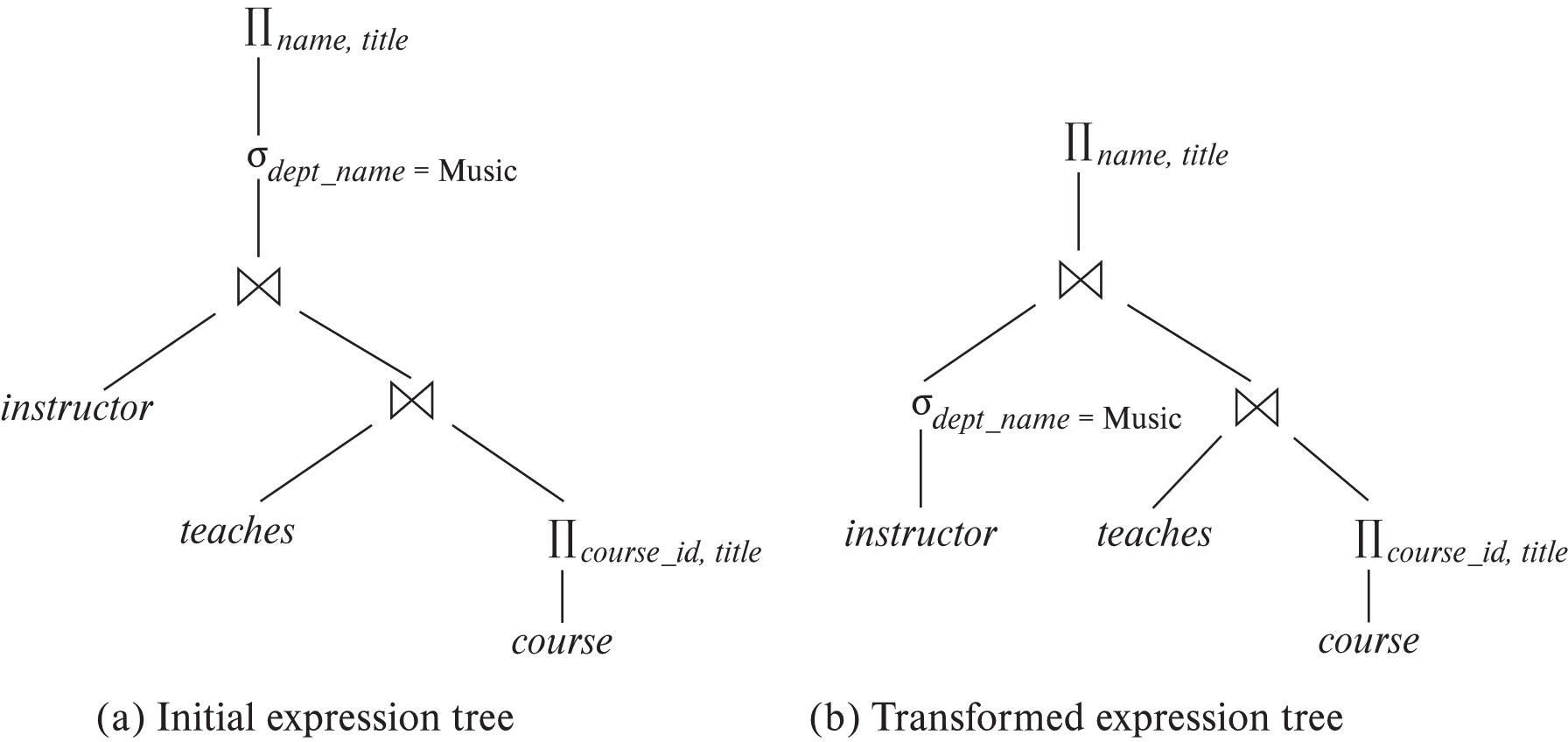
查询:找出 Music 系所有教师姓名,以及他们教授课程的标题。
根据规则 7a,可将选择尽早下推:
选择越早执行,后续连接输入越小。
4. 2 Multiple Transformations¶
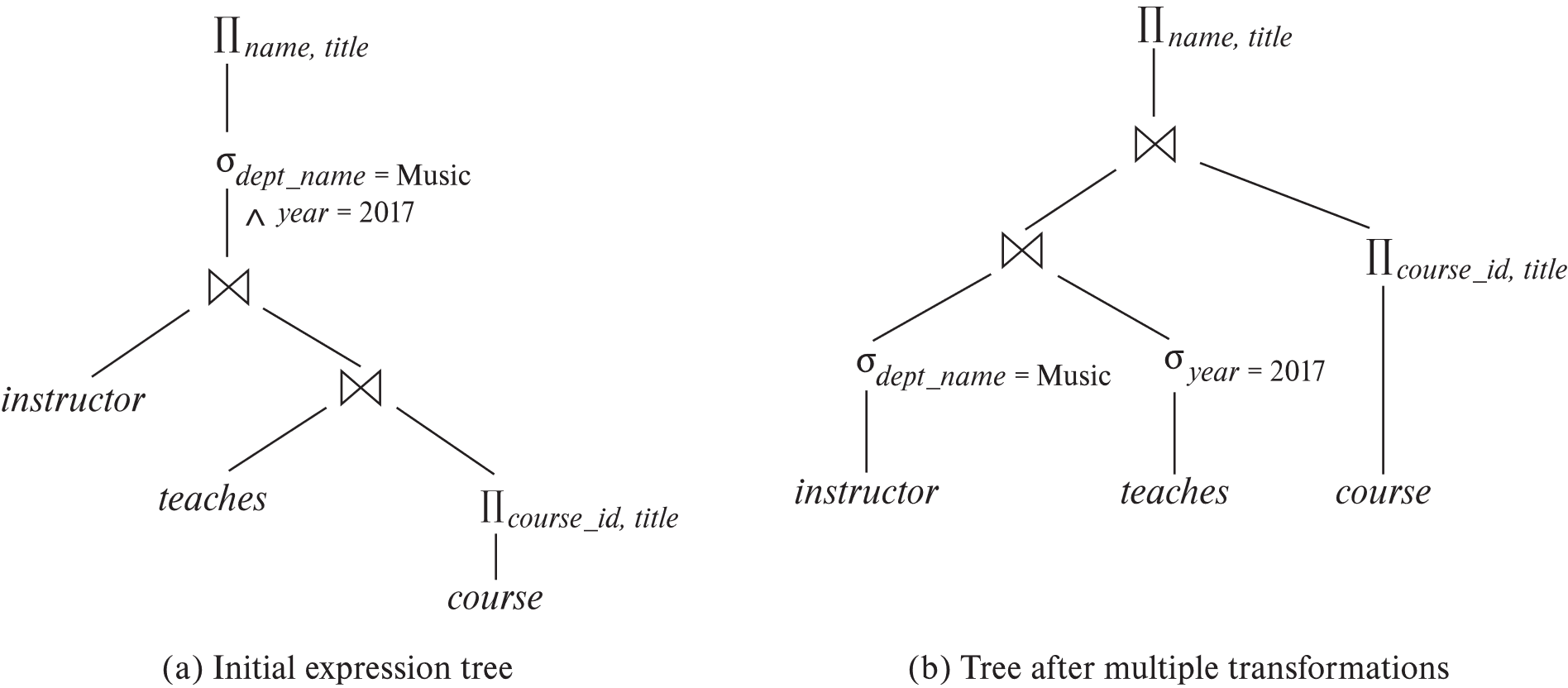
查询:找出 Music 系所有在 2017 年教过课的教师姓名,以及他们教过课程的标题。
先用连接结合律改写:
随后可将选择分别下推到 instructor 和 teaches:
4. 3 Pushing Projections¶
考虑中间表达式:
若直接计算,结果模式可能为:
但最终只需要 name、title,并且后续连接还需要 course_id。因此可提前投影:
提前投影可以减少中间结果的属性数,从而降低中间结果大小和 I/O。
4. 4 Join Ordering¶
连接结合律允许改变连接顺序:
若 \(r_2 \bowtie r_3\) 很大,而 \(r_1 \bowtie r_2\) 很小,则应优先计算:
在 Music 系查询中,只有少量教师属于 Music 系,因此通常先算:
而不是先算可能很大的:
5 Cost-Based Optimization¶
5. 1 Enumeration of Equivalent Expressions¶
查询优化器可以使用等价规则系统地生成等价表达式:
- 对目前已知的每个表达式及其子表达式应用所有可用等价规则。
- 将新生成的表达式加入候选集合。
- 重复上述过程,直到不再生成新表达式。
这种朴素方法会产生巨大的时间和空间开销,因此实际系统通常采用:
- 基于转换规则的优化计划生成。
- 针对选择、投影、连接查询的特殊优化方法。
- 动态规划和 memoization 避免重复求解。
5. 2 Transformation-Based Optimization¶
空间开销可通过共享公共子表达式减少。应用等价规则时,很多转换只改变表达式树顶层结构,底层子树可通过指针共享。
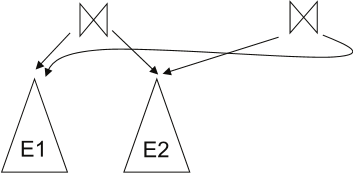
时间开销可通过不生成所有表达式来减少。实际优化器会检测重复生成的子表达式,并对已经优化过的子表达式复用结果。
5. 3 Cost Estimation in Optimization¶
每个操作符的成本可按第 15 章算法估计,但输入可能是中间结果,因此优化器必须同时估计中间结果的元组数、元组大小、不同值个数等统计信息。
选择执行计划时不能只独立选择每个操作最便宜的算法,因为操作之间会相互影响:
- Merge join 单独看可能比 hash join 贵,但它输出有序结果,可能降低上层分组、排序或 merge join 的成本。
- Nested-loop join 可能支持流水线,避免物化中间结果。
- 某些物理等价规则可将逻辑计划转换为不同物理计划,例如指定 join 算法、访问路径和排序方式。
实际优化器通常结合两类方法:
- 搜索候选计划并以代价为准选择最优计划。
- 使用启发式规则缩小搜索空间。
5. 4 Dynamic Programming for Join Order¶
考虑寻找:
的最佳连接顺序。该表达式的连接顺序数量为:
当 \(n=7\) 时有 \(665280\) 种;当 \(n=10\) 时超过 \(176\) billion 种。
动态规划的核心思想是:对任意关系子集 \(S \subseteq \{r_1,r_2,\dots,r_n\}\),只计算一次其最优计划,并存储起来供后续复用。
动态规划递推
对关系集合 \(S\) 寻找最佳计划时,枚举所有非空真子集 \(S_1\),将计划写成:
递归求出 \(S_1\) 和 \(S-S_1\) 的最佳计划,再尝试所有可用连接算法,选择总代价最小的计划。
单关系是递归基:对每个关系 \(R_i\),使用该关系上的选择条件和可用索引,选择最佳访问路径。
procedure findbestplan(S)
if bestplan[S].cost != infinity
return bestplan[S]
if S contains only one relation
set bestplan[S] using the best access path
else
for each non-empty subset S1 of S where S1 != S
P1 = findbestplan(S1)
P2 = findbestplan(S - S1)
A = best algorithm for joining P1 and P2
cost = P1.cost + P2.cost + cost(A)
if cost < bestplan[S].cost
update bestplan[S]
return bestplan[S]
对具体连接算法还要考虑物理限制:
- Indexed nested-loop join 中,内层输入通常必须是单个关系,且该关系连接属性上有可用索引。
- Hash join 中,构建输入可以是 \(P_1\) 或 \(P_2\),两个方向应作为不同候选算法。
- Indexed nested-loop join 中,外层输入也可以是 \(P_1\) 或 \(P_2\),需要分别估计。
5. 5 Left-Deep Join Trees¶
Left-deep join tree 指每个连接的右输入都是一个基本关系,而不是中间连接结果。
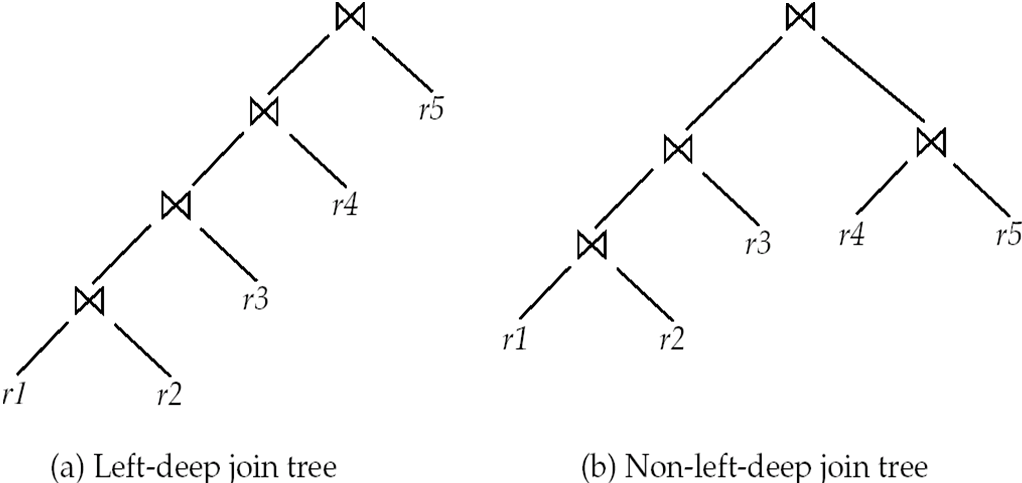
许多优化器只考虑 left-deep join order,因为它能显著降低优化复杂度,并且更适合流水线执行。
| 搜索空间 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| Bushy tree 动态规划 | \(O(3^n)\) | \(O(2^n)\) |
| Left-deep tree 动态规划 | \(O(n2^n)\) | \(O(2^n)\) |
当 \(n=10\) 时,动态规划约需考虑 \(59000\) 个子问题量级,远小于 \(176\) billion 个完整连接顺序。代价优化本身仍然昂贵,但对大型查询通常值得。
5. 6 Interesting Sort Orders¶
Interesting sort order 是指某种排序顺序虽然可能让当前操作稍贵,但能显著降低后续操作成本。
例如:
如果公共属性是 \(A\),使用 merge join 计算 \(r_1 \bowtie r_2\) 可能比 hash join 贵,但会输出按 \(A\) 排序的结果,从而让后续与 \(r_3\) 的 merge join 更便宜。
因此,仅为每个关系子集保存一个最优计划可能不够,还需要为每个子集、每个 interesting sort order 保存最佳计划。通常 interesting order 数量很少,不会显著改变复杂度。
5. 7 Cost-Based Optimization with Equivalence Rules¶
高效的基于等价规则的优化器依赖:
- 节省空间的表达式表示,避免复制大量公共子表达式。
- 高效检测重复推导出来的表达式。
- 基于 memoization 的动态规划,对子表达式只优化一次。
- 基于代价的剪枝,避免生成所有计划。
该方向由 Volcano 项目开创,并被 SQL Server 优化器等系统采用。
6 Heuristic Optimization and Optimizer Structure¶
基于代价的优化即使用动态规划也可能昂贵,因此系统常使用启发式规则减少需要精确估价的选择。
常见启发式规则:
- 尽早选择:减少参与后续操作的元组数。
- 尽早投影:减少参与后续操作的属性数。
- 优先执行限制性最强的选择和连接:先产生较小的中间结果。
不同系统策略不同:有的几乎只用启发式规则,有的将启发式与局部代价优化结合。
6. 1 Optimizer Structure¶
很多优化器只考虑 left-deep join order,并配合选择、投影下推:
- 降低优化复杂度。
- 产生更适合流水线执行的计划。
一些 Oracle 版本使用启发式连接顺序选择:从每个可能起点开始,反复选择当前“最佳”的下一个关系,最后在多个起点方案中选最优。
更常见的优化流程是:
- 对嵌套块结构和聚合做启发式重写。
- 对每个块做基于代价的连接顺序优化。
SQL Server 等优化器可对整个查询应用转换,不完全依赖 SQL 块结构。
6. 2 Optimization Budget and Plan Caching¶
优化器本身也消耗资源,因此系统可能设置 optimization cost budget。当继续优化的代价超过潜在收益时,可提前停止。
计划缓存(plan caching)用于复用已经生成过的计划。即使查询常量不同,也可能复用同一参数化计划。对非常便宜的查询,优化器往往只使用简单启发式;对昂贵查询,才更可能做穷举或接近穷举的计划枚举。
7 Optimizing Nested Subqueries¶
7. 1 Correlated Evaluation¶
嵌套查询示例:
select name
from instructor
where exists (
select *
from teaches
where instructor.ID = teaches.ID
and teaches.year = 2019
);
SQL 概念上把 where 子句中的嵌套子查询看作带参数的函数。来自外层查询、并在内层子查询中使用的变量称为相关变量(correlation variables)。
概念执行方式是:外层 from 子句产生的每个元组组合,都调用一次嵌套子查询。这称为相关求值(correlated evaluation)。
相关求值可能非常低效:
- 嵌套子查询会被调用大量次数。
- 可能产生大量不必要的随机 I/O。
7. 2 Decorrelation and Semijoin¶
优化器会尽量把嵌套子查询转换为 join。上面的查询可粗略改写为:
但该改写可能产生不同的重复元组数量。要保持 exists 的重复语义,应使用半连接(semijoin)。
半连接 \(\ltimes\) 定义:若 \(r_i\) 在 \(r\) 中出现 \(n\) 次,且存在至少一条 \(s_j\) 与其满足连接条件,则 \(r_i\) 在 \(r \ltimes_\theta s\) 中仍出现 \(n\) 次。
因此查询可写为:
也可先下推选择:
这也等价于:
select name
from instructor
where ID in (
select teaches.ID
from teaches
where teaches.year = 2019
);
若需要只用 SQL join 表达,可先构造去重临时结果:
with t1 as (
select distinct ID
from teaches
where year = 2019
)
select name
from instructor, t1
where t1.ID = instructor.ID;
对 not exists 查询:
select name
from instructor
where not exists (
select *
from teaches
where instructor.ID = teaches.ID
and teaches.year = 2019
);
可用 anti-semijoin 表示:
7. 3 General Decorrelation¶
一般形式:
select A
from r1, r2, ..., rn
where P1
and exists (
select *
from s1, s2, ..., sm
where P21 and P22
);
其中:
- \(P_{21}\) 不涉及相关变量。
- \(P_{22}\) 涉及相关变量。
可改写为:
将嵌套查询替换为 join 或 semijoin 的过程称为去相关(decorrelation)。
去相关在以下情况下更复杂,系统可能仍采用相关求值:
- 嵌套子查询中包含聚合。
- 嵌套子查询是标量子查询。
标量聚合子查询有时也可以借助分组聚合去相关。例如:
select name
from instructor
where 1 < (
select count(*)
from teaches
where instructor.ID = teaches.ID
and teaches.year = 2019
);
可改写为:
8 Materialized Views¶
8. 1 Basic Concepts¶
物化视图(materialized view)是内容已经计算并存储下来的视图。
例如:
create view department_total_salary(dept_name, total_salary) as
select dept_name, sum(salary)
from instructor
group by dept_name;
如果经常查询各部门工资总额,物化该视图可以避免每次都扫描多条 instructor 元组并重新求和。
8. 2 Materialized View Maintenance¶
保持物化视图与底层数据同步称为物化视图维护(materialized view maintenance)。
维护方式包括:
- 每次底层数据更新后完全重新计算视图。
- 使用增量视图维护(incremental view maintenance)。
- 手动定义触发器处理每个基础关系的插入、删除和更新。
- 手写代码在基础表更新时同步视图。
- 周期性重算,例如夜间批处理。
- 使用数据库系统内置的增量维护机制。
增量维护通常比完全重算更高效,也能避免手写维护逻辑的正确性问题。
8. 3 Differentials¶
关系或表达式的变化称为差分(differential)。
- \(i_r\):插入到关系 \(r\) 的元组集合。
- \(d_r\):从关系 \(r\) 删除的元组集合。
为简化讨论,可将更新操作视为先删除旧元组,再插入新元组。
9 Incremental View Maintenance¶
9. 1 Join Operation¶
设物化视图:
若向 \(r\) 插入元组集合 \(i_r\),则:
由于 \(r_{old}\bowtie s\) 是旧视图 \(v_{old}\),因此:
若从 \(r\) 删除元组集合 \(d_r\),则:
对 \(s\) 的插入和删除对称。
9. 2 Selection and Projection¶
若:
则插入时:
删除时:
投影维护更困难。若 \(R=(A,B)\),且:
则:
删除 \((a,2)\) 时不能删除投影结果 \((a)\),因为 \((a,3)\) 仍能产生它。只有再删除 \((a,3)\) 后,才应删除 \((a)\)。
因此,对每个投影结果元组维护一个引用计数:
- 插入时,如果投影元组已存在,则计数加 \(1\);否则插入该元组并设计数为 \(1\)。
- 删除时,对应投影元组计数减 \(1\);若计数变为 \(0\),删除该投影元组。
9. 3 Aggregation Operations¶
对:
插入 \(i_r\) 时,对 \(i_r\) 中每条元组找到其分组:
- 若分组已存在,则
count加 \(1\)。 - 若分组不存在,则插入新分组并设
count = 1。
删除 \(d_r\) 时,对每条被删元组所在分组:
count减 \(1\)。- 若
count变为 \(0\),删除该分组。
对:
维护方式类似,只是插入时加上 \(B\) 值,删除时减去 \(B\) 值。同时仍需维护 count,用于判断某个分组是否已经没有元组。不能只用 sum = 0 判断,因为合法数据本身可能求和为 \(0\)。
对 avg(B),应分别维护 sum(B) 和 count(B),查询时再相除。
对 min(B) 和 max(B):
- 插入维护简单,可直接比较新值。
- 删除维护可能昂贵,因为删除当前最小值或最大值后,需要查看同组其他元组以找出新的最小值或最大值。
9. 4 Other Operations and Full Expressions¶
对集合交:
- 向 \(r\) 插入元组时,若该元组也在 \(s\) 中,则加入 \(v\)。
- 从 \(r\) 删除元组时,若该元组在交集中,则从 \(v\) 删除。
- 对 \(s\) 的更新对称。
并、差可用类似方式维护。外连接与普通连接维护方式类似,但还需要额外处理未匹配元组补 NULL 或从补 NULL 状态变为匹配状态的情况。
对完整表达式,应从最小子表达式开始,自底向上推导每个子表达式的差分。例如对 \(E_1 \bowtie E_2\),若插入到 \(E_1\) 的差分为 \(D_1\),则插入到连接结果的差分为:
10 Query Optimization and Materialized Views¶
优化器应同时考虑使用物化视图和展开物化视图定义。
使用物化视图重写查询:
若已有物化视图:
用户查询:
可重写为:
是否采用取决于代价估计。
展开物化视图定义:
若已有物化视图 \(v=r\bowtie s\),但 \(v\) 上没有合适索引;用户查询:
如果 \(r\) 在 \(A\) 上有索引,\(s\) 在公共属性 \(B\) 上有索引,则最佳计划可能是先展开:
而不是直接扫描物化视图 \(v\)。
10. 1 Materialized View Selection¶
物化视图选择(materialized view selection)回答:应该物化哪些视图?
索引选择(index selection)回答:应该创建哪些索引?
两者都依赖典型系统负载(workload),包括查询和更新。常见目标是在空间约束、关键查询或关键更新响应时间约束下,最小化整体工作负载执行时间。
商业数据库通常提供 tuning assistants 或 wizards,帮助 DBA 选择索引和物化视图。
11 Additional Optimization Techniques¶
11. 1 Top-K Queries¶
Top-K 查询示例:
select *
from r, s
where r.B = s.B
order by r.A asc
limit 10;
可选方案:
- 使用 indexed nested-loop join,并以 \(r\) 为外层关系,使输出更接近
r.A的顺序。 - 估计结果中第 \(K\) 小的
r.A上界 \(H\),在where子句中额外加入r.A <= H。若结果少于 \(10\) 条,则用更大的 \(H\) 重试。
11. 2 Optimization of Updates and Halloween Problem¶
Halloween problem 示例:
update R
set A = 5 * A
where A > 10;
如果使用 \(A\) 上的索引查找 A > 10 的元组,并在扫描过程中立即更新 \(A\),同一条元组可能因为索引位置变化而被再次找到并重复更新。
解决方案:
- 总是延迟更新:第一遍收集旧值和新值,第二遍再更新关系和索引。缺点是即使更新不影响筛选属性,也要付出额外开销。
- 必要时才延迟更新:如果更新不影响
where条件涉及的属性,可立即更新;否则延迟更新。
11. 3 Join Minimization¶
Join minimization 用于检测某些 join 是否冗余。
例如:
select r.A, r.B
from r, s
where r.B = s.B;
若 r.B 是引用 s.B 的外键,r.B 声明为 not null,且查询没有使用 s 的属性、也没有对 s 做筛选,则与 s 的连接可以删除。
另一个例子:
select r.A, s2.B
from r, s as s1, s as s2
where r.B = s1.B
and r.B = s2.B
and s1.A < 20
and s2.A < 10;
在满足相应约束时,与 s1 的连接及其筛选条件可能是冗余的,可以删除。
11. 4 Multiquery Optimization¶
多查询优化(multiquery optimization)寻找一组查询的整体最优执行计划,重点是识别可共享的公共子表达式。
例如:
-- Q1
select *
from (r natural join t) natural join s;
-- Q2
select *
from (r natural join u) natural join s;
两者共享子表达式 \(r \bowtie s\)。有时先计算一次共享结果并复用更便宜,但并不总是如此,因为共享子表达式本身可能很昂贵,原始计划反而更便宜。
一些系统使用简单启发式:
- 分别优化每个查询。
- 在各自最优计划中检测公共子表达式。
- 只在看起来有利时共享。
共享扫描(shared scans)是多查询优化的常见特例。多个物化视图维护计划也可能共享公共子表达式,因此多查询优化同样适用于视图维护。
11. 5 Parametric Query Optimization¶
参数化查询示例:
select *
from r natural join s
where r.a < $1;
参数 $1 在编译时未知,只在运行时确定;不同参数值可能对应不同最优计划。
可选策略:
- 每次运行时重新优化,准确但开销高。
- 参数化查询优化:优化器预先生成一组计划,每个计划对某些参数范围最优;运行时根据实际参数选择计划。
- 查询计划缓存:如果优化器判断同一计划很可能适用于所有参数值,则缓存并复用;否则每次重新优化。
对 \(1\) 到 \(3\) 个参数,最优计划集合通常较小。关键难点是如何高效找出这组计划。
11. 6 Plan Stability Across Optimizer Changes¶
优化器升级后,即使 \(95\%\) 的计划更快,也可能有 \(5\%\) 的计划变慢。原因是原计划可能依赖两个错误估计互相抵消;修正其中一个错误反而可能暴露另一个错误。
常见应对方式:
- 为查询提供 hints,让 DBA 手动调优。
- 设置优化级别,默认使用旧版本优化器行为,再逐个查询迁移测试。
- 保存旧版本计划,并将其交给新版本优化器使用,例如 Sybase、SQL Server 的计划表示机制。
11. 7 Adaptive Query Processing¶
自适应查询处理允许系统在运行时调整计划。
- 一些系统支持自适应算子,例如在运行时根据外层输入大小选择 indexed nested-loop join 或 hash join。
- 另一些系统监控执行行为,若发现实际行数与估计差异很大,可停止执行、重新优化并重启。
重新优化必须避免过于频繁,否则重启开销会抵消收益。