OOP 朋辈辅学 Lec2 构造、析构、拷贝¶
1 练习¶
例题 1:嵌套类访问外部类成员
#include <iostream>
using namespace std;
// 1. 外部类 Outer
class Outer {
public:
// 外部类的构造函数(给私有成员 x 赋值)
Outer(int x): x(x){}
// 2. 嵌套在外部类里的内部结构体 Inner
struct Inner{
// 打印外部类的私有成员 x
void display(Outer& outer){cout << outer.x << endl;}
};
// 3. 外部类里,创建一个内部结构体的对象
Inner inner;
private:
// 4. 外部类的私有成员(只有自己/内部类能访问)
int x;
};
int main(){
// 创建外部类对象,给 x 赋值 10
Outer outer(10);
// 调用内部对象的函数,打印 x
outer.inner.display(outer);
return 0;
}
运行结果
输出 10。
display() 接收了一个 Outer& outer,因此可以通过这个对象访问 outer.x。
这里并不是 Inner 自动携带一个外部类对象,而是显式传入了一个 Outer 对象
例题 2:引用
#include <iostream>
using namespace std;
int main(){
int x = 100;
auto& y = x;
y = 200;
cout << "x:" << x << " y:" << y << endl;
return 0;
}
运行结果
输出 x:200 y:200。
y 是 x 的引用,本质上是 x 的别名。
例题 3:输入
如果用户输入 Hello World,执行 string s; cin >> s; 后,变量 s 的内容是?
运行结果
s 的内容是 Hello,因为 >> 会在空白字符处停止读取。
例题 4:指针和引用
以下关于指针和引用的说法正确的是?
\(\text{A}\). 指针和引用都可以为空 \(\qquad\) \(\text{B}\). 指针和引用都必须有初始值
\(\text{C}\). 引用的本质是对象的别名 \(\qquad\) \(\text{D}\). 指针和引用都可以被重新赋值
答案
\(\text{C}\)
- \(\text{A}\) 错:指针可以为空,引用不能为空
- \(\text{B}\) 错:指针不一定必须在定义时指向有效对象,引用必须绑定到对象
- \(\text{C}\) 对:引用可以看作对象的别名
- \(\text{D}\) 错:指针可以改指向,引用一旦绑定通常不能改绑
2 函数¶
2. 1 传参方式¶
- 值传递:创建实参副本,函数内部修改不影响外部对象。
- 指针传递:传地址,可以通过解引用修改原对象。
- 引用传递:传别名,既避免大对象拷贝,也比裸指针更自然。
实践建议
- 小对象可以值传递,大对象通常用引用传递
- 若不希望被修改,优先使用常量引用,如
const std::vector<int>& v
2. 2 默认参数¶
- 默认参数在调用方省略对应实参时由编译器补上
- 默认参数通常写在函数声明处
- 默认参数必须从右往左连续提供
示例
#include <iostream>
using namespace std;
void printSum(int a, int b=10){
cout << a+b << endl;
}
int main(){
printSum(5); // 输出15
printSum(5, 5); // 输出10
return 0;
}
2. 3 函数重载¶
- 函数重载:函数名相同,但参数列表不同(参数个数、类型或顺序不同)。
示例
void print(int i) { cout << "Integer" << endl; }
void print(double f) { cout << "Double" << endl; }
void print(int i, double f) { cout << "Integer & Double" << endl; }
float c = 3.0; print(c); 的运行结果?
输出 Double。
long d = 4; print(d); 能正确输出吗?
这段代码会产生二义性(ambiguous),无法通过编译。long -> int 和 long -> double 都需要类型转换,编译器无法选出唯一更优的重载版本。
示例
# include <iostream>
using namespace std;
void print(int i) {cout << "Integer" << endl;}
void print(long l) {cout << "Long" << endl;}
void print(float f) {cout << "Float" << endl;}
void print(double f) {cout << "Double" << endl;}
void print(int i, double f) {cout << "Integer & Double" << endl;}
int main(){
print(1);
return 0;
}
- 当前演示程序运行输出为
Integer - 若调用
print(4L),则会命中print(long) - 若调用
print(3.0f),则会命中print(float)
2. 4 内联函数¶
- 适用于代码量很小且调用频繁的函数
- 含义是“建议编译器在调用点直接展开函数体”
- 它只是建议,是否真正内联由编译器决定
示例
inline int getMax(int a, int b){
return a > b ? a : b;
}
2. 5 Lambda 表达式¶
基本形式:[capture](parameters) -> return_type { body }
[capture]:捕获列表,决定能访问哪些外部变量(parameters):参数列表-> return_type:返回类型,很多时候可省略{ body }:函数体
常用捕获方式
[]:不捕获[x]:按值捕获x[&x]:按引用捕获x[=]:按值捕获所有外部变量[&]:按引用捕获所有外部变量
降序排序
vector<int> nums = {1, 4, 3, 5, 2, 6};
sort(nums.begin(), nums.end(), [](int a, int b){ return a > b; });
按值捕获 vs 按引用捕获
#include <iostream>
using namespace std;
int main(){
int x=1;
auto f=[x](){cout << x << endl;}; // 按值捕获,x 的副本 = 1
f(); // 输出 1
auto g=[&x]{x++;}; // 按引用捕获,对内部 x 的操作会直接作用在外面的 x 上
g(); // 执行 x++,把外面的 x 从 1 变成了 2
cout << x << endl; // 输出 2
return 0;
}
3 构造与析构¶
3. 1 构造函数¶
构造(Construction)不只是分配一块内存,更重要的是把这块原始存储初始化为一个合法、可用的对象。
C 风格的动态内存
int* p;
p = malloc(5 * sizeof(int));
// do something
free(p);
malloc只负责分配原始内存,不会调用构造函数malloc分配出的内容默认未初始化- 真正会把内存清零的是
calloc
- 构造函数把初始化规则收进类内部,保证对象一出生就处于合法状态。
没有构造的风险
- 安全性差:对象可能带着未初始化成员进入后续逻辑
- 封装性差:外部代码必须知道对象内部有哪些成员、该如何逐个设置
- 构造函数名必须和类名相同,且没有返回值,甚至不能写
void - 构造函数可以重载
- 若一个构造函数可以在不传参的情况下调用,则它是默认构造函数
编译器自动生成默认构造的规则
- 如果类没有声明任何构造函数,编译器会尝试自动生成默认构造函数
- 但这个自动生成的默认构造函数不会帮你初始化所有内置类型成员
- 一旦类里声明了任意构造函数,编译器通常就不再自动补一个默认构造函数
示例
#include <iostream>
using namespace std;
class Player {
public:
// 提示编译器生成默认构造函数
Player() = default;
// 带参数的构造函数,会用传入的值初始化 score 并打印 Constructor
Player(int score) : score(score){
cout << "Constructor" << endl;
}
int score;
};
int main(){
Player p; // 调用的是默认构造函数
cout << p.score << endl;
return 0;
}
运行结果
Player() = default 只是让编译器生成默认构造函数,对于 int score 这样的内置类型成员,它不会自动清零,因此 p.score 是未初始化值(indeterminate value)。
实际运行时可能打印任意垃圾值,编译器也会给出 used uninitialized 的警告。
3. 2 初始化列表¶
初始化列表(Initializer List)在进入构造函数体之前,直接构造成员变量。
示例
class Player {
public:
Player() = default;
// 用参数 score 的值去初始化成员变量 score
Player(int score): score(score) {}
int score;
};
初始化列表是初始化,而不是先默认构造再赋值,效率通常更高。
对于 const 成员和引用成员,它是唯一可行的初始化方式。
3. 3 析构函数¶
析构函数(Destructor)在对象生命周期结束时自动调用,负责释放对象占有的资源,如堆内存、文件句柄、网络连接等,形式为 ~ClassName()。
析构函数没有参数、没有返回值、不支持重载。
示例
#include <iostream>
using namespace std;
class Buffer {
public:
Buffer(int size=0):size(size) {
data=new int[size];
}
Buffer(const Buffer& other):size(other.size) {
data=new int[size];
for(int i=0;i<size;i++){
data[i]=other.data[i];
}
}
~Buffer() {
delete[] data; // 析构函数:释放资源
cout << "Deconstructor" << endl;
}
int* data;
int size;
};
int main(){
Buffer m1;
Buffer m2 = m1;
return 0;
}
运行结果
输出两次 Deconstructor,分别对应 m2 和 m1 的析构。
析构触发时机
- 局部对象离开作用域时
new出来的对象被delete时- 静态对象 / 全局对象在程序结束时
4 C++ 的内存管理¶
4. 1 new 与 delete¶
new:分配内存并调用构造函数delete:调用析构函数并释放内存new[]/delete[]:专门用于数组malloc/free和new/delete不能交叉混用
示例
auto* p1 = new Buffer();
delete p1;
int* p2 = new int[4];
delete[] p2;
4. 2 内存分布¶
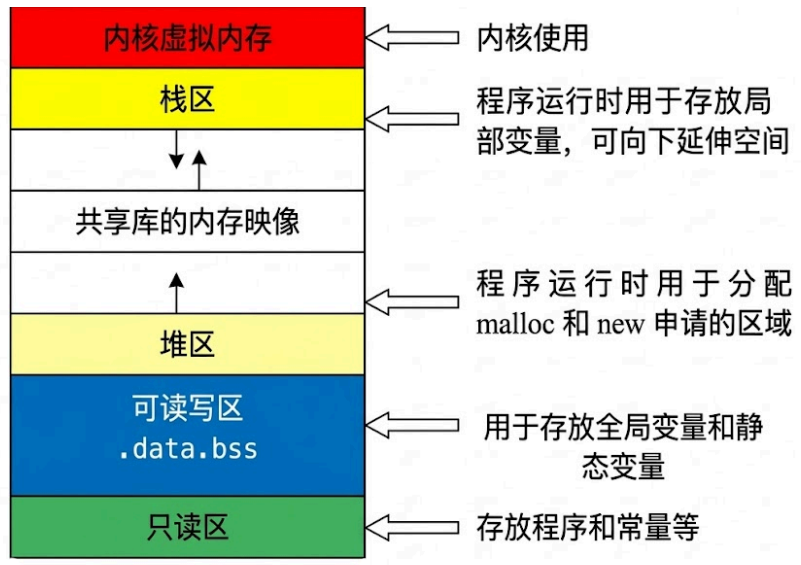
4.3 RAII¶
RAII(Resource Acquisition Is Initialization,资源获取即初始化) 的核心思想是:把资源的获取和释放绑定到对象生命周期上。
典型场景
- 构造对象时申请内存
- 对象析构时自动释放内存
- 即使中途异常退出,只要离开作用域,析构函数仍会被执行
RAII 是 C++ 资源管理的核心范式,它能显著降低内存泄漏和资源泄漏风险。
4. 4 内存泄漏检测¶
- 静态检测:如
Cppcheck - 动态检测:
- Valgrind:Linux 上常用,检测全面,但运行较慢
- AddressSanitizer:由编译器集成,速度更快,现代项目中很常见
5 拷贝¶
5. 1 浅拷贝与深拷贝¶
- 浅拷贝(Shallow Copy):逐个成员复制。若成员中含有指针,则只复制地址,多个对象会指向同一块堆内存。
风险
- 一个对象改数据,另一个对象也会看到变化
- 两个对象析构时会对同一块内存重复释放,导致
double free
- 深拷贝(Deep Copy):不仅复制成员值,还重新分配资源,并把原资源内容复制过去。
5. 2 拷贝构造函数¶
- 函数签名:
ClassName(const ClassName& other);
Buffer 的拷贝构造
Buffer(const Buffer& other):size(other.size) {
data=new int[size];
for(int i=0;i<size;i++){
data[i]=other.data[i];
}
}
触发场景
ClassA obj2 = obj1;,注意此处不是调用拷贝赋值ClassA obj2(obj1);- 以值传递方式把对象传给函数
注:Buffer m2 = m1; 在定义语句里出现,触发的是拷贝构造,不是拷贝赋值。
5.3 拷贝赋值运算符¶
- 函数签名:
ClassName& operator=(const ClassName& other);
示例
Buffer& operator=(const Buffer& other) {
if (this == &other) return *this; // 防止自赋值
delete[] data; // 先释放旧资源
size = other.size;
data = new int[size];
for (int i = 0; i < size; i++) data[i] = other.data[i];
return *this;
}
和拷贝构造的区别
- 拷贝构造:目标对象还没创建完成
- 拷贝赋值:目标对象已经存在,可能已经持有旧资源
- 因此拷贝赋值往往需要先处理旧资源,再完成深拷贝
5.4 this 指针¶
- 每个非静态成员函数都有一个隐含的
this指针 - 它始终指向当前正在调用该成员函数的对象
- 其类型可理解为
ClassName* const this指针在成员函数开始执行前被创建,在函数执行后销毁
在 Buffer 中显式写出 this
Buffer(const Buffer& other):size(other.size) {
this->data = new int[size];
for(int i = 0; i < this->size; i++){
this->data[i] = other.data[i];
}
}
this 的常见用途
- 在成员函数中区分当前对象成员和同名参数
- 在赋值运算符中检测自赋值:
if (this == &other) - 返回当前对象本身:
return *this;
Rule of Three
如果一个类显式定义了以下三者中的任意一个,通常就应该认真考虑是否也要显式定义另外两个:
- 析构函数
- 拷贝构造函数
- 拷贝赋值运算符
Buffer 正是这个典型例子:它管理堆内存,因此这三者往往要配套考虑。